CCNet--于"阡陌交通"处超越恺明 Non-local
加入极市专业CV交流群,与6000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!更有机会与李开复老师等大牛群内互动!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。点击文末“阅读原文”立刻申请入群~
作者:Lingyun Zeng
来源:https://zhuanlan.zhihu.com/p/51393573
原文:https://arxiv.org/pdf/1811.11721.pdf
code:https://github.com/speedinghzl/CCNet
所属领域:语义分割
一、了解一些背景是阅读本文的充分条件
题目是“CCNet--于"阡陌交通"处超越恺明Non-local”...好的,我们先来简要介绍下Non-local(CVPR'2018)吧。
Non-local Neural Networks:(kaiming和RGB出品)
1、中心思想:将传统图像处理方法中的Non-Means(非局部平均)去噪的思想用在Neural Networks中,在视频分类&检测&分割都取得很好的结果。
要知道Non-Means(非局部平均),我们只要知道“局部平均”就够了。
所谓的局部平均,从字面意思理解,就是只在局部位置求平均。比如中值滤波、双线性滤波,因为它们在操作前都需要在被滤波的图像上确定一块区域,再对这个区域进行滤波,所以它们都属于“局部平均”的去噪方法。(当然啦,这里想强调的是“局部”,实际操作时也不一定只取平均,理解局部的思想即可。)
中值滤波:将每一像素点的灰度值设置为该点某领域窗口内的所有像素点灰度值的中值。—— 百度百科
so,Non-Means(Baudes于2005年提出),顾名思义,就是不再只对部分区域进行滤波,而是直接对整幅图像进行去噪,对常见的高斯噪声有很好的滤波作用。
2、Non-local:
于是乎,Non-local应运而生。此处的local是针对CNN中的卷积操作来说的。
一次卷积操作,它的感受野大小(此处指在输入feature map上的感受野)即为卷积核大小,除了“全局卷积”(卷积核大小与原图尺寸相同)的情况,所有卷积核都只能考虑到输入feature map的局部区域。都是“local”的。
然而,图像之间距离较远的像素间的相关信息也是有价值的。尤其是在处理序列化数据(比如视频帧)时。分析一个人奔跑的动作,Ta在第1帧位于S1像素区域的手臂动作,和第10帧位于S2像素区域的手臂动作相关性就极大。静态图像同理,不能只关注手臂区域,还要关注手臂和腿部的相对位置,来更好地分析目标整体的动作。
如果能将这种远距离像素(视频任务是指时空域上的远距离,静态图像识别是指空间域上的远距离)间的相关性信息加入网络中,我们也许能够得到信息更丰富的feature map,从而提升网络的性能。
理解到需要捕获全局信息,就算作对Non-local做到了心中有数。
我们来看看它的具体实现:
类似于attention机制(可以先简单理解为,根据各像素之间的相关性,对所有像素进行加权。权重越大,说明我们更要pay attention to them。),定义公式如下:


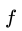
因为是对输入feature map每个向量都进行相同操作,所以输入输出feature map大小相同,故这种结构也很容易嵌入网络中。

接下来看看CCNet是怎么改进的。
二、CCNet——Criss-Cross Attention for Semantic Segmentation
(一种为语义分割设计的十字型attention....哈,论一个好标题的作用:它可能是设计了一种十字型attention,用在语义分割里效果杠杠的)
下图蓝色点为待处理像素点
(a)是Non-local,含蓝色中心的feature map是输入,分为上下两个分支处理:
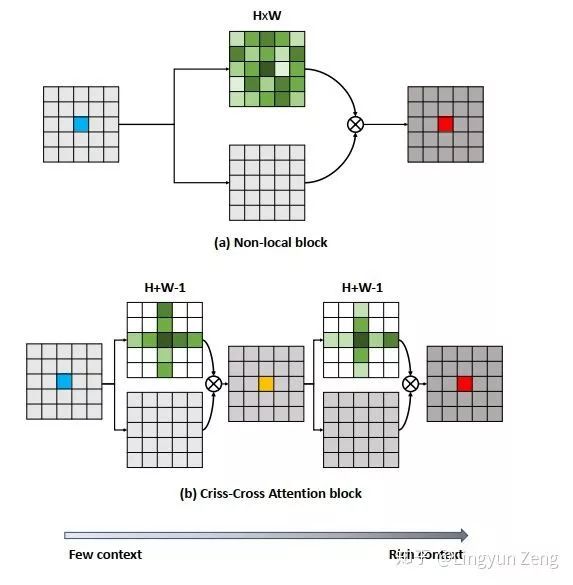
深绿色分支代表已经完成Non-local操作,得到了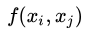
下面灰色分支代表进行了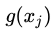
(b)即为CCNet的改进,可以看到,深绿色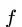

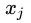
为什么堆叠两次即可?
我们先看看信息是如何通过十字型结构传递的:
上图展示了蓝色像素点的信息传达到左下角点的过程:
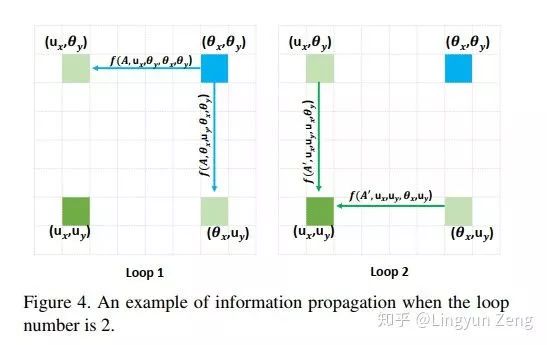
第一次loop1,我们在计算左下角点的f时,只能包含左上角点和右下角点的信息,此时并没有左下角点与蓝色点的相关信息。但在计算左上(or右下)点时,是计算了蓝色点与它们的相关性信息的。
第二次loop2,当我们再次计算左下角点的
同理,其他不在左下点十字型位置的像素点,都可以通过这种方式在第二次loop的时候就将信息传递给左下点。于是实现两次loop便“遍历”了所有点。
事实上,我们可以发现蓝色点信息是传递了两遍给左下点的(左上传递了一次,右下传递了一次),虽然是间接传递没有直接计算得到的结果强度大,但这种对于信息的两次加强也很有可能是最终效果 略胜于 Non-local的原因之一。
于是乎,原本需要计算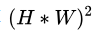
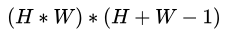
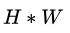
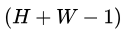
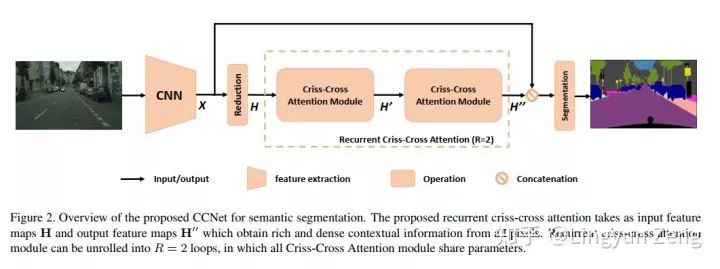
以下是CCNet的网络结构:
选择预先训练过的ImageNet
使用ResNet-101作为backbone(删除了最后两个下采样操作并采用dilation卷积)
Results:
上图中间两列是 y 的输出结果,R是指使用了R个CC-Attention block。第一列标识一个绿色的点,中间两列展示整幅图像各个像素点与该绿色位置像素点的相关性大小,越亮代表相关性越大。可以看到,当R=2时,亮的部分已经基本可以标识出绿点所指示的物体轮廓。
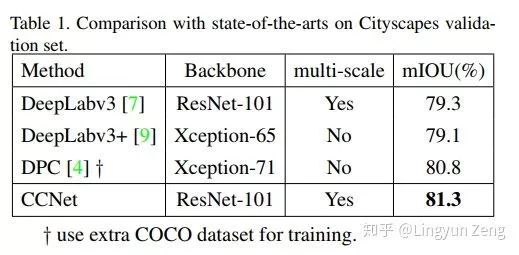
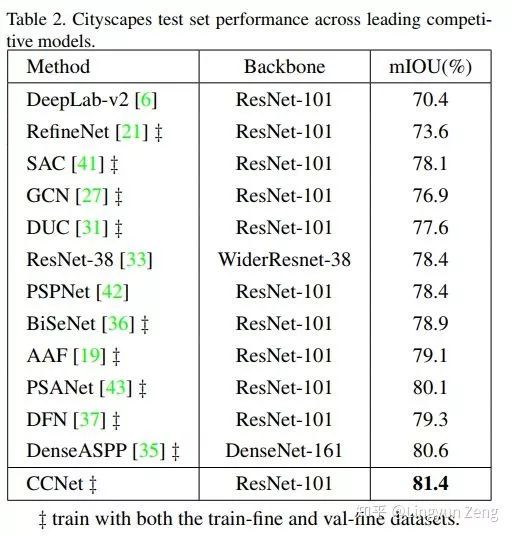

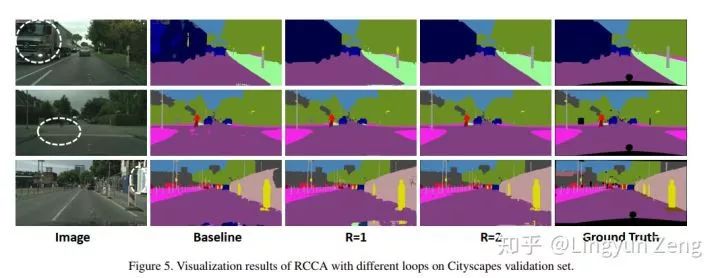
可以看到结果相当不错。
吼吼,和Non-local相比,1/11的内存消耗,15%的计算开销!666!
*延伸阅读
Fast-OCNet: 更快更好的OCNet.
语义分割 | context relation
每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。点击左下角“阅读原文”立刻申请入群~

觉得有用麻烦给个好看啦~


