GCNet:当Non-local遇见SENet
加入极市专业CV交流群,与6000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!更有机会与李开复老师等大牛群内互动!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。点击文末“阅读原文”立刻申请入群~
陀飞轮:复旦大学研究生在读,研究方向是目标检测、分割、跟踪
好文!非常insight!研究思路类似于DPN,DPN深入探讨了ResNet和DenseNet的优缺点,然后结合ResNet和DenseNet的优点提出了DPN,同样GCNet深入探讨了Non-local和SENet的优缺点,然后结合Non-local和SENet的优点提出了GCNet。
Motivation
为了捕获长距离依赖关系,产生了两类方法:
第一种是采用自注意力机制来建模query对的关系。
第二种是对query-independent(可以理解为无query依赖)的全局上下文建模。
NLNet就是采用自注意力机制来建模像素对关系。然而NLNet对于每一个位置学习不受位置依赖的attention map,造成了大量的计算浪费。
SENet用全局上下文对不同通道进行权值重标定,来调整通道依赖。然而,采用权值重标定的特征融合,不能充分利用全局上下文。
通过严格的实验分析,作者发现non-local network的全局上下文在不同位置几乎是相同的,这表明学习到了无位置依赖的全局上下文。
基于上述观察,本文提出了GCNet,即能够像NLNet一样有效的对全局上下文建模,又能够像SENet一样轻量。
Revisiting the Non-local Block
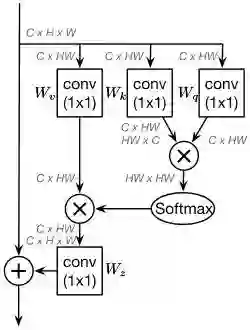
non-local block旨在从其他位置聚集信息来增强当前位置的特征。将输入的feature map定义为 



non-local block可以表示为:











作者从COCO数据集中随机选择6幅图,分别可视化3个不同位置和它们的attention maps。作者发现对于不同位置来说,它们的attention maps几乎是相同的。作者通过分析不同位置全局上下文的距离,进一步证明了这一点。换句话说,虽然non-local block想要计算出每一个位置特定的全局上下文,但是经过训练之后,全局上下文是不受位置依赖的。
Simplifying the Non-local Block
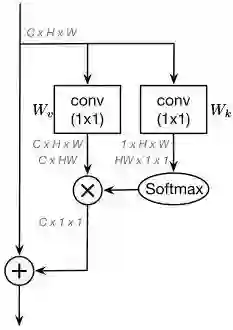
基于上述观察,作者通过计算一个全局的attention map来简化non-local block,并且对所有位置共享这个全局attention map。忽略


为了进一步减少简化版non-local block的计算量,将

这样修改之后,1x1卷积 

不同于原始的non-local block,简化版non-local block的第二项是不受位置依赖的,所有位置共享这一项。因此,作者直接将全局上下文建模为所有位置特征的加权平均值,然后聚集全局上下文特征到每个位置的特征上。
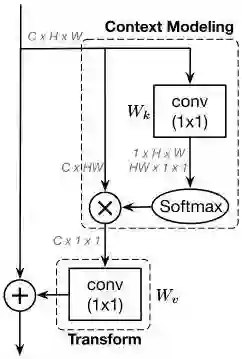
Global Context Modeling Framework
简化版的non-local block可以抽象为3个步骤:
(a)全局attention pooling:采用1x1卷积
(b)特征转换:采用1x1卷积
(c)特征聚合:采用相加操作将全局上下文特征聚合到每个位置的特征上。
作者将该抽象过程作为全局上下文建模的框架,定义为:

(a) 

(b) 
(c) 
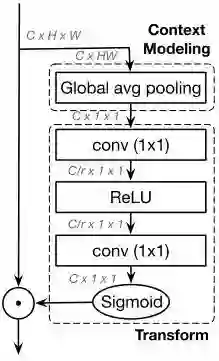
SE block也可以抽象成3个步骤:
(a)global avg pooling用于上下文建模(即squeeze operation)。
(b)bottleneck transform用于计算每个通道的重要程度(即excitation operation)。
(c)rescaling function用于通道特征重标定(即element-wise multiplication)。
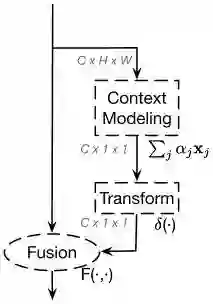
Global Context Block
作者提出了一种新的全局上下文建模框架,global context block(简写GCNet),即能够像SNL block一样建立有效的长距离依赖,又能够像SE block一样省计算量。
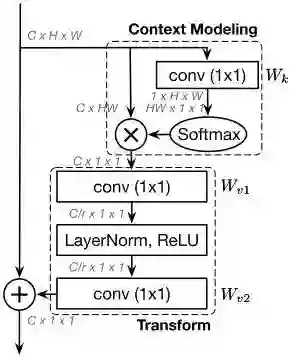
在简化版的non-local block中,transform模块有大量的参数。为了获得SE block轻量的优点,1x1卷积用bottleneck transform模块来取代,能够显著的降低参数量(其中r是降低率)。因为两层bottleneck transform增加了优化难度,所以在ReLU前面增加一个layer normalization层(降低优化难度且作为正则提高了泛化性)。
GC block表示为:



GC block的3个步骤为:
(a)global attention pooling用于上下文建模。
(b)bottleneck transform来捕获通道间依赖。
(c)broadcast element-wise addition用于特征融合。
为什么Non-local和SENet有效
其实仔细一想,卷积也能拆分成空间依赖、通道依赖、特征融合三个步骤,Non-local和SENet有效主要是因为context modeling,卷积只能对局部区域进行context modeling,导致感受野受限制,而Non-local和SENet实际上是对整个输入feature进行context modeling,感受野可以覆盖到整个输入feature上,这对于网络来说是一个有益的语义信息补充。另外,网络仅仅通过卷积堆叠来提取特征,其实可以认为是用同一个形式的函数来拟合输入,导致网络提取特征缺乏多样性,而Non-local和SENet正好增加了提取特征的多样性,弥补了多样性的不足。
GCNet充分结合了Non-local全局上下文建模能力强和SENet省计算量的优点,在各个计算机视觉任务上得到更好的结果。
其实论文中还有一个地方没有讲清楚,就是Non-local block为什么经过训练后不受位置依赖呢,有没有大佬给我解答一下~,感谢!
是不是因为Non-local更关注于那些需要focus的物体,从而去掉了那些不需要focus的冗余特征,所以导致了每个位置的attention map基本上只覆盖到前景物体上。
Reference
1.Squeeze-and-Excitation Networks
https://arxiv.org/abs/1709.01507
2.Non-local Neural Networks
https://arxiv.org/abs/1711.07971v1
3.GCNet: Non-local Networks Meet Squeeze-Excitation Networks and Beyond
https://arxiv.org/abs/1904.11492?context=cs.LG
欢迎交流指正~
*延伸阅读
点击左下角“阅读原文”,即可申请加入极市目标跟踪、目标检测、工业检测、人脸方向、视觉竞赛等技术交流群,更有每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流,一起来让思想之光照的更远吧~

觉得有用麻烦给个好看啦~



