CVPR 2018|视频分析的非局部(non-local) 神经网络模块,CMU与Facebook AI研究室视频分类识别新贡献
来源:David 9的博客
http://nooverfit.com/wp/cvpr2018精选2-视频分析的非局部non-local-神经网络模块,cmu与facebook-ai/#more-4829
拥有什么,决定了你只能决定什么。——David 9
很大程度上,目前的芯片工艺和技术,决定了人类只能迷恋神经网络这样的方案(高于传统机器学习一个计算级别)。就像进入铁器时代,人们才能方便地砍伐森林、挖掘矿山、开垦土地(如果在青铜时代就别想了)。在铁器时代,对铁器的改进很受欢迎;正如今年CVPR上大神Kaiming He和Xiaolong Wang 的文章试图改进神经网络工具去“开垦”视频分析这片土地。
我们知道视频和图片的区别无非是多了时间的维度(time,视频的帧)。最直觉的做法是先用cnn,再用擅长时间序列的rnn;或者,直接用3D卷积去做。而实际情况是直接用3D卷积效果不是最好,于是有人用两个cnn去做(一个cnn分析时间,一个cnn分析空间),或者另外用一个分析轨迹(trajectories)的模块去加强时空感。
而非局部(non-local) 模块把非局部感受野的信息提取操作做成一个神经网络模块,方便了端到端的视频分析:
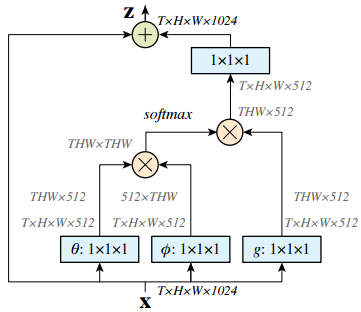
这个模块输入x可以理解为32帧的视频(32张图片帧数 T=32,长宽为H×W),输出z也是H×W大小的特征图。有没有注意到最左端的箭头是一个跳层连接?没错,non-local模块就是把视频额外的时空信息提取作为一个残差操作,这样整个模块可以任意插入到一个残差网络resnet中:
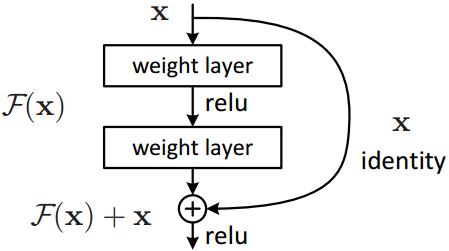
事实上,残差信息就是要学习一些额外的信息,下面画出红线的就是学习残差信息的部分:
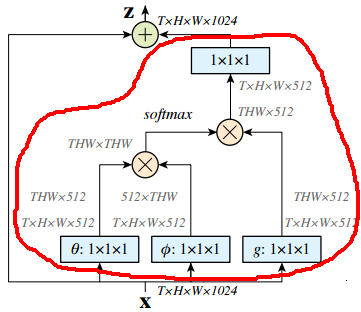
来自:https://arxiv.org/pdf/1711.07971.pdf
上述non-local模块是依据下面公式给出的:
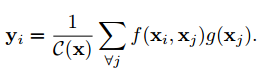
之所以叫做non-local模块,是对比卷积操作的局部感受野而言的,其中xi,xj 可以理解为不同帧i和j 的两张图片:

来自:https://arxiv.org/pdf/1711.07971.pdf
我们要知道这段视频是一个“踢球”的Action,我们对每一帧分析时要知道两个点:
关键点1.
与这一帧的关联性比较高的其他帧是哪些?上式中关联度的标量计算由f 函数给出:
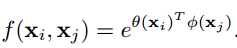
f 函数度量两和位置之间的相关度,用高斯函数或点乘等操作都可以达到计算的效果,文章也指出,用各种方式计算,其实差别并不大:
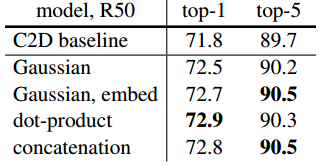
关键点2.
这些关联性比较高的帧,可能在做什么是什么Action?这就需要上式的g 函数计算得到在xj 处的图像特征。其实仔细一开始的模块图,就可以发现其实这里的函数 g,超参数θ和Φ 都是用1×1的卷积去计算的。
注意到公式中j 是对每个位置的xj 都一一对比,所以该模块被称之为非局部(non-local)模块。
文章中的实验是基于ResNet-50 的卷积2D网络(C2D),数据集采用谷歌deepmind的Kinetics人体行为视频数据集。网络架构如下:
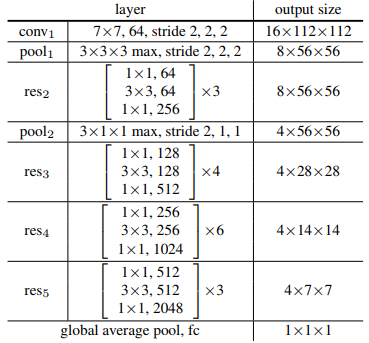
来自:https://arxiv.org/pdf/1711.07971.pdf
输入视频为32×224×224(32帧,长宽为224×224)。其中大的方括号中是一个残差块(Residual blocks),“×3”代表3个残差块组成的res2阶段的组。文章中称一组残差块为一个阶段(stage),如上图res2阶段有3个残差块,到了res3有4个残差块,而到了较后层的res4阶段,有6个残差块(不要以为阶段stage是训练的不同阶段。它其实是在网络的不同深度而已)。文章也指出把non-local模块放在不同阶段的位置,网络性能也有差异,最好不要放在最后res5那一层之后,因为到了res5之后的特征图空间已经比较小,学习不到太多空间关系了:
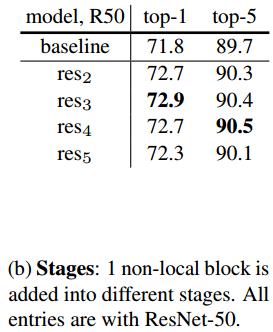
另外之前有人在知乎上说较长的视频可能效果就不好,但是文章的实验结果似乎在128帧的视频上预测效果还是比较好的:
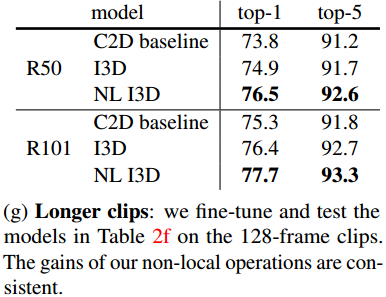
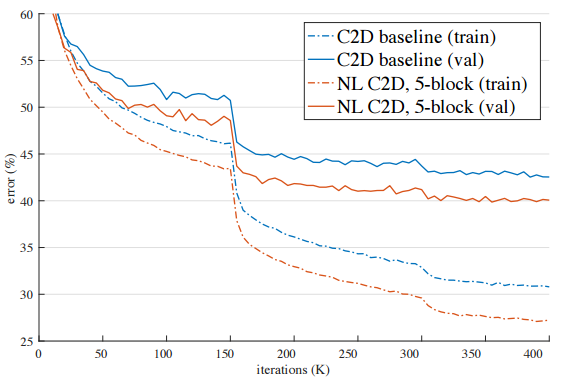
最后看一下总体实验结果和在res3阶段后加non-local模块计算的效果:

参考文献:
https://arxiv.org/pdf/1711.07971.pdf
https://github.com/facebookresearch/video-nonlocal-net
https://github.com/titu1994/keras-non-local-nets
https://www.zhihu.com/question/68473183
https://arxiv.org/pdf/1705.06950.pdf
https://deepmind.com/research/open-source/open-source-datasets/kinetics/
http://cvpr2018.thecvf.com/program/main_conference
https://medium.com/mlreview/a-guide-to-receptive-field-arithmetic-for-convolutional-neural-networks-e0f514068807
https://zhuanlan.zhihu.com/p/33345791
本文采用署名 – 非商业性使用 – 禁止演绎 3.0 中国大陆许可协议进行许可。著作权属于“David 9的博客”原创,如需转载,请联系微信: david9ml,或邮箱:yanchao727@gmail.com
*推荐文章*
CVPR 2018 | 无监督且多态的图片样式转换技术,康奈尔大学与英伟达新作MUNIT及其源码
CVPR 2018 | 腾讯AI Lab、MIT等机构提出TVNet:可端到端学习视频的运动表征
PS.极市平台正式启动了极市原创作者计划。欢迎各位的高质量的视觉方向的原创投稿文章,我们将不遗余力得在我们所有的平台上进行传播分享。更多详情请点击:活动 | 加入极市原创作者行列,实现一个小目标



