告别自注意力,谷歌为Transformer打造新内核Synthesizer

作者:舒意恒(南京大学硕士生,知识图谱方向)
今天给大家介绍一篇来自Google的最新论文《SYNTHESIZER: Rethinking Self-Attention in Transformer Models》[4],该论文重新探索了Transformer中注意力机制的必要性,并引入了新的attention计算方法Synthesizer。实验显示,即使不进行token之间的attention交互计算,synthesizer在翻译、语言模型、GLUE等任务上也可以达到很好的效果。
前言
什么是自注意力?
2017 年,Vaswani 等人 [1] 提出了 Transformer 模型,在众多领域取得了成功的应用,证明了它相比于自卷积模型和循环模型的优势。
Transformer 的关键在于 query-key-product 的点积注意力,token 被完全连接,能够对远距离的依赖关系进行建模。
Transformer 存在的问题
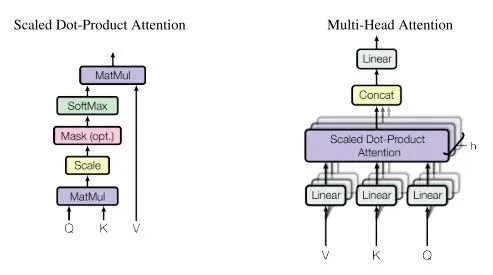
点积自注意力提供了强大的建模能力,但同时作者对点积自注意力提出了质疑,它的计算可能是不必要的。
点积的基本作用是确定单个 token 相对于序列中所有其他 token 的相对重要性。key、query、value 暗示自注意力模拟一个基于内容的检索过程,过程的核心是 pairwise 的交互。该文对整个过程进行了反思。
技术简介
Synthesizer 的关键思想
Synthesizer 的核心思想是用低复杂度的attention计算代替dot product式的注意力机制。传统 Transformer 的注意力机制需要进行 token 之间的两两交互,虽然可以获得更多的交互信息,但attention score会很依赖实例,难以保证模型学到更多的泛化特征。
因此,synthesizer提出了新的attention matrix学习方法,只通过简单的前馈神经网络即可得到注意力分数,完全省去了token之间的点积交互。
实现细节
Synthesizer 大体上可以理解为一个 Transformer,其中自注意力模块被 Synthetic Attention 模块替换。
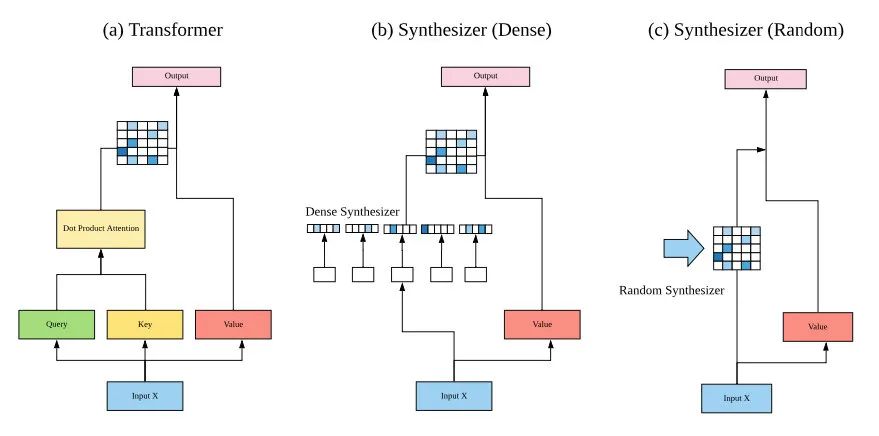
上图表示了 Transformer、Dense Synthesizer 和 Random Synthesizer 的关键思想。
Synthesizer 移除了 query-key-value 的概念,而直接合成一个对齐矩阵。具体而言,即去除了 、 、 ,而使用一个行和列大小等同于序列长度 的矩阵 来表示任意 token 之间的关系。作者提出了两类 synthesizer,分别是 Dense Synthesizer 和 Random Synthesizer。
Dense Synthesizer
给定模型的输入 ,表示了 个 token,每个 token 的维度为 . 该方法做如下的变换:
这可以理解为两个 Dense 层, 和 用于 Dense 层的计算。而最后模型的输出 ,由表示 token 间关系的矩阵 得到。
其中, 可类比为标准 Transformer 的 .
该思路并不复杂,但是,作者进一步描述了 Random Synthesizer。
Random Synthesizer
Dense Synthesizer 方法实际上是给定每个 token,然后映射到 维,而不是如同原生的 Transformer 对 token 间交互进行建模。Random Synthesizer 的方法中,注意力权重的初始化不是受任何输入 token 的影响,而是完全随机初始化。这些随机初始化的值可以被训练,或者保持固定。
以 表示一个随机初始化矩阵,则 Random Synthesizer 被定义为:
即 初始化的值是 . 该方法不依赖 token 对之间的交互或者任何单个 token 的信息,而是学习一个能跨实例有效的任务特定的对齐。作者表示这是最近固定自注意力方法 [2]的直接产物。
换句话说,作者认为,学习一个跨实例有效的模型意味着在初始化时不直接依靠任何 token 信息。
分解模型
Dense Synthesizer 为网络添加了大小为 的参数,用于映射;而 Random Synthesizer 添加了大小为 的参数。如果序列很长,将导致很大的参数量。因此,为了实践中更加可行,作者提出了分解模型,分别针对 Dense Synthesizer 和 Random Synthesizer 称为 Factorized Dense Synthesizer 和 Factorized Random Synthesizer。该方法的作用是减少参数量,并防止过拟合。
1. Factorized Dense Synthesizer
针对可能过大的序列长度 ,取两个整数 和 使得 ,分别按 Dense Synthesizer 算得两个矩阵记为 和 ,两矩阵大小分别是 和 . 然后将 中表示 token 的每个向量重复 次,将 中表示 token 的每个向量重复 次,再做元素积,即可从分解出的两个矩阵恢复到 . 参数量减小,同时模型的表征能力可能也受到了影响。
2. Factorized Random Synthesizer
类似地,随机矩阵也可被分解为两个低秩矩阵。
混合模型
上述所有提出的 synthetic 注意力变种都可以通过加和形式混合到一起。
其中, 表示一个 synthesizer 的函数,并且 , 是可学习的。
另外,类似于原生 Transformer 的 multi-head attention,Synthesizer 同样支持多个 head.
效果
作者在机器翻译、语言模型、文本生成、多任务自然语言处理等任务上进行了实验。
机器翻译与语言建模
作者采用常见的 WMT'14 英德(EnDe)和英法(EnFr)翻译测试。
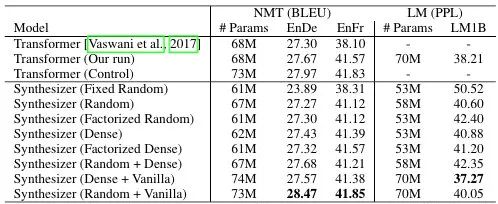
关于机器翻译任务,可以看到相同参数量的 Synthesizer(Random + Vanilla) 与其他模型拉开了一定差距,也比相同参数量的 Transformer (Control) 表现更好。值得注意的是,两个分解方法取得的提升并不如混合模型取得的提升更多,但在一定程度上减少了参数量。
关于语言建模任务,使用的数据集是 LM1B,取得最好效果的是 Synthesizer (Dense + Vanilla),它仍然是一个混合模型,同样是 Synthesizer 的各种设置中唯一超过 Transformer 的模型。
文本生成
评测使用 CNN/Dailymail 数据集的抽象摘要任务和使用 PersonaChat 数据集的对话生成任务。其中,Synthesizer 的各个模型表现不一。

多任务 NLP
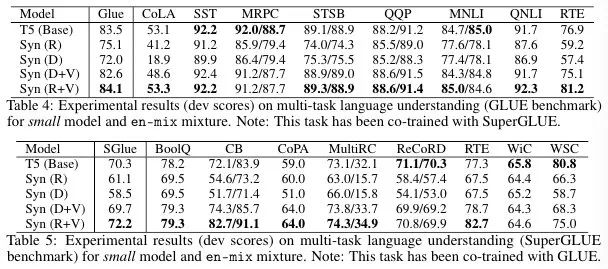
在多任务 NLP 上,作者遵循 T5 [3] 所使用的使用 GLUE 和 SuperGLUE 评测方法,并在多项指标超过了 T5(base)。在众多测试中,仍然是加上 Vanilla 的 Synthesizer 取得较好效果。
总结
该文提出了 Synthesizer,一个新的 Transformer 模型,它采用了合成注意力(Synthetic Attention)。作者试图更好地理解和评估全局对齐和局部、实例对齐(独立 token 和 token 到 token 的对齐)在自注意力中的效用。
在机器翻译、语言建模和对话生成等多个任务上,合成注意力与原有自注意力相比,表现出有竞争力的性能,点积自注意力的作用与效率值得怀疑与进一步研究。此外,在对话生成任务上,token 之间的交互信息实际会损害性能。
实际上,Synthesizer 的不同设置没有绝对的优劣,也和具体的任务相关。个人认为为何在各种任务中 Synthesizer 的表现存在明显差异、它与点积注意力分别适合于哪些任务,以及背后的成因是值得深究的。
[1] Attention Is All You Need. arXiv preprint arXiv:1706.03762, 2017.
[2] Fixed encoder self-attention patterns in transformer-based machine translation. arXiv preprint arXiv:2002.10260, 2020.
[3] xploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. arXiv preprint arXiv:1910.10683, 2019.
[4] Tay Y, Bahri D, Metzler D, et al. Synthesizer: Rethinking Self-Attention in Transformer Models[J]. arXiv preprint arXiv:2005.00743, 2020.

推荐阅读
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
太赞了!Springer面向公众开放电子书籍,附65本数学、编程、机器学习、深度学习、数据挖掘、数据科学等书籍链接及打包下载
数学之美中盛赞的 Michael Collins 教授,他的NLP课程要不要收藏?
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,点个在看吧👇





