更深层次的模型有助于更好地表达特性;
在计算机视觉以及分本分类任务上,已经有成功案例。
但是在机器翻译领域,目前标准的Transformer模型,仅仅有6层。
论文《Very Deep Transformers for Neural Machine Translation》将标准的Transfomer模型encoder加深至60层,decoder加深至12层。
这些深层模型比基线模型的性能更优,并在WMT14 EnglishFrench和WMT14 EnglishGerman上达到了SOTA。
论文地址:https://arxiv.org/pdf/2008.07772.pdf
项目地址:https://github.com/namisan/exdeep-nmt
预备知识
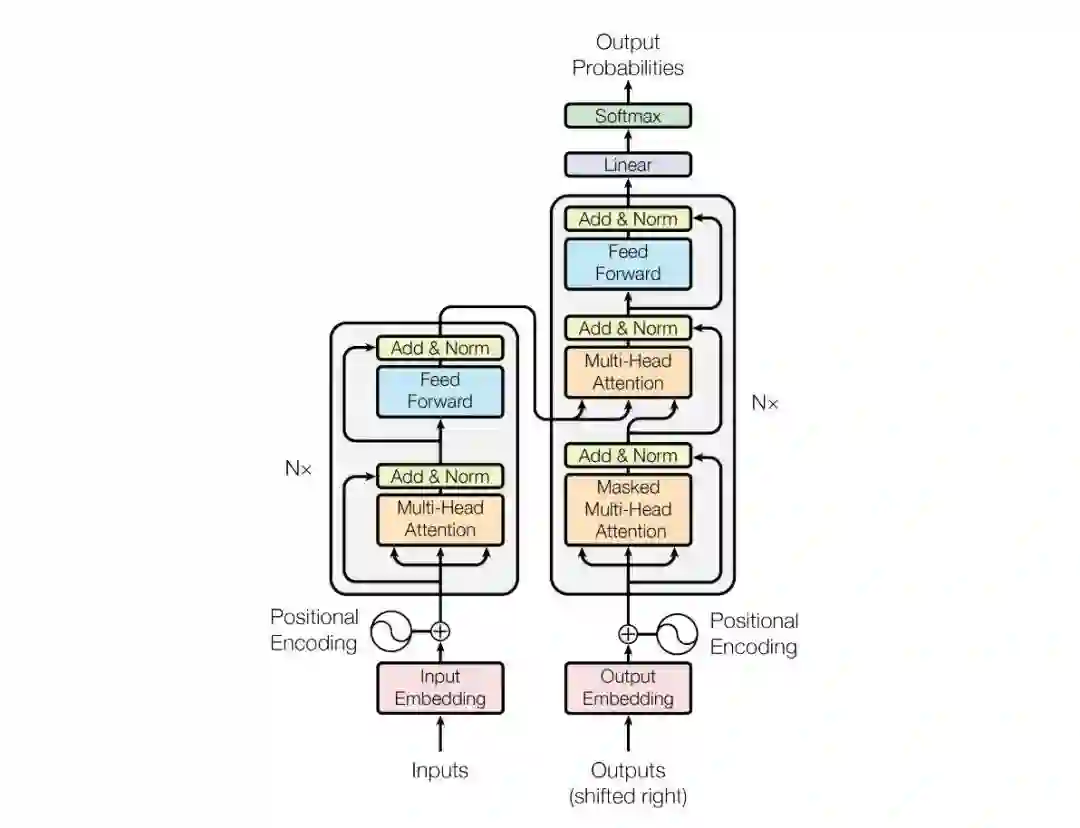
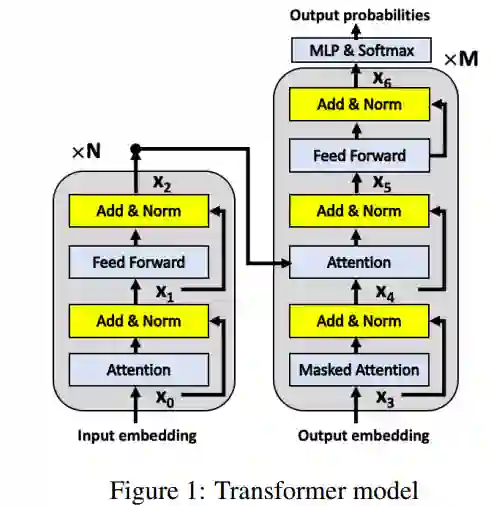
![]() Transformer模型包含N层Transformer layer。每个Transformer layer包含两个部分:Multi-Head Attention (MHA) 和Position-wise Feed-Forward Network (FFN)。用论文中的公式表示,分为两步:
Transformer模型包含N层Transformer layer。每个Transformer layer包含两个部分:Multi-Head Attention (MHA) 和Position-wise Feed-Forward Network (FFN)。用论文中的公式表示,分为两步:
MHA层和FFN层之间,以及FFN层之后包含一个残差连接和LN层,详细可见文献1。以上两个公式,可以统一表达为以下公式:
其中
![]() 代表ATT注意力层和FNN层,i下标表示第i层。
代表ATT注意力层和FNN层,i下标表示第i层。
方法
越深层的网络,越难训练。因为训练网络时,容易出现梯度消失问题,即使layer normalization缓解了此问题,但是依然存在。在机器翻译中,解码器和编码器下层之间缺少梯度流动尤其成问题。文献2提出将交换
![]() 和
和
![]() 的位置,即先进行layer normalization, 再进行self-attention或者feed-forward network(Pre-LN), 公式如下:(Transofmer中标准形式称为Post-LN):
将Transofmer的encoder增加到30层,并且改变了上一层信息传递到下一层的方式,该方法也被96层的GPT-3 采用。
论文在不改变Transformer结构的基础, 加深模型。主要参考了论文作者自己的一篇文献3 :该文献指出,Pre-LN比Post-LN训练更加稳定,但是Post-LN比Pre-LN有更大的潜力达到更好的效果;并且对比分析Post-LN训练不稳定的原因在于:Post-LN对于残差输出部分(非直接连接部分)进行LN次数少于其他部分,因此权重较大。因此提出Adaptive Model Initialization(Admin)方法来使得Transformer模型更加稳定,并且能够达到原有的效果。主要公式如下:
引入了一个额外的向量
的位置,即先进行layer normalization, 再进行self-attention或者feed-forward network(Pre-LN), 公式如下:(Transofmer中标准形式称为Post-LN):
将Transofmer的encoder增加到30层,并且改变了上一层信息传递到下一层的方式,该方法也被96层的GPT-3 采用。
论文在不改变Transformer结构的基础, 加深模型。主要参考了论文作者自己的一篇文献3 :该文献指出,Pre-LN比Post-LN训练更加稳定,但是Post-LN比Pre-LN有更大的潜力达到更好的效果;并且对比分析Post-LN训练不稳定的原因在于:Post-LN对于残差输出部分(非直接连接部分)进行LN次数少于其他部分,因此权重较大。因此提出Adaptive Model Initialization(Admin)方法来使得Transformer模型更加稳定,并且能够达到原有的效果。主要公式如下:
引入了一个额外的向量
![]() ,
,
![]() 与输入
与输入
![]() 的维度相同,对应元素相乘。分为两个阶段:
(1)Profiling:初始化
的维度相同,对应元素相乘。分为两个阶段:
(1)Profiling:初始化
![]() 为元素全为1的向量,即保持原有Transformer中的公式计算,进行前向操作,计算每层
为元素全为1的向量,即保持原有Transformer中的公式计算,进行前向操作,计算每层
![]() 方差。
(2)Initialization: 在训练阶段,固定
方差。
(2)Initialization: 在训练阶段,固定
![]() 按照上述公式进行前向操作,并更新参数。训练完成之后,重新参数化模型,例如最简单的操作,移除
按照上述公式进行前向操作,并更新参数。训练完成之后,重新参数化模型,例如最简单的操作,移除
![]() 。文献3附录中给出了更多重新参数化的方式,这里不再说明。
使用Admin初始化方法,可以有效训练稳定性,即使在深层的网络中使用。
。文献3附录中给出了更多重新参数化的方式,这里不再说明。
使用Admin初始化方法,可以有效训练稳定性,即使在深层的网络中使用。
实验
随着层数加深到60层encoder,12层decoder,如果不用Admin初始化方法,模型不再收敛;使用Admin方法后,模型收敛并且BIEU相比标准的Transformer模型提升了2.5. 说明加深标准的Transformer训练是可行并且有效的。值得注意的是,在标准的Transformer的基础上使用Admin初始化方法也带来了一定的提升。
Table2列出了当前一些最好的机器翻译的模型的效果,可以看出ADMIN深层Tansformer在以上两个数据集上也达到了最好的效果。
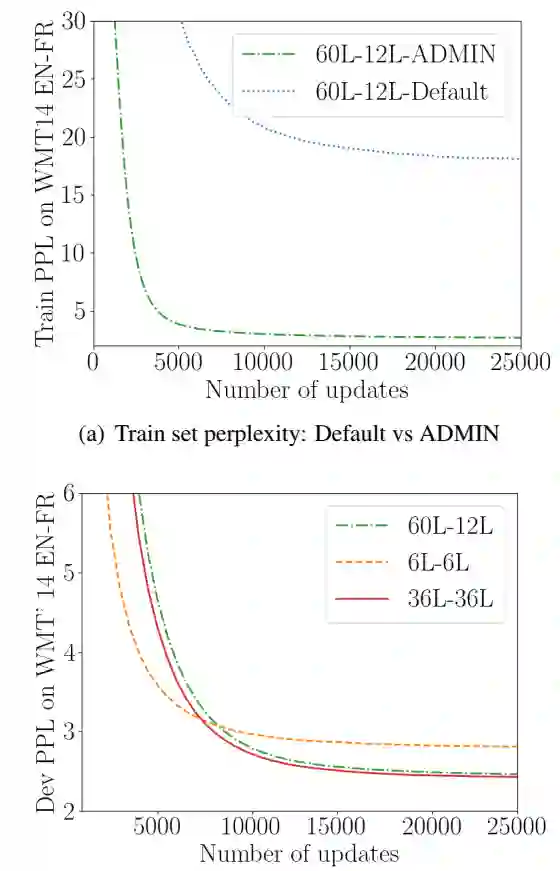
下图(a)对比了模型在训练过程中的曲线,表明Admin方法可以有效改善深层Transformer模型不收敛的问题。(b)图在验证集上,不同设置层数,Admin + Transfomer模型的perplexity随着训练步数的变化,可以发现在越深层的模型可以达到更小的perplexity值。
结论
1. 论文证明加深Transformer进行训练是可行的。并且使用Admin初始化方法将Transformer模型的encoder加深至60层,decoder加深至12层,在两个机器翻译的数据集上Bleu大约提高了2个点。
2. 为深层transformer模型的研究开辟了方向。
1. Vaswani, Ashish, et al. "Attention is all you need." Advances in neural information processing systems. 2017.
2. Wang, Qiang, et al. "Learning deep transformer models for machine translation." arXiv preprint arXiv:1906.01787 (2019).
3. Liu, Liyuan, et al. "Understanding the Difficulty of Training Transformers." arXiv preprint arXiv:2004.08249 (2020).
AI科技评论联合博文视点赠送周志华教授“森林树”十五本,在“周志华教授与他的森林书”一文留言区留言,谈一谈你和集成学习有关的学习、竞赛等经历。
AI 科技评论将会在留言区选出15名读者,每人送出《集成学习:基础与算法》一本。
活动规则:
1. 在“周志华教授与他的森林书”一文留言区留言,留言点赞最高的前 15 位读者将获得赠书。获得赠书的读者请联系 AI 科技评论客服(aitechreview)。
2. 留言内容会有筛选,例如“选我上去”等内容将不会被筛选,亦不会中奖。
3. 本活动时间为2020年8月23日 - 2020年8月30日(23:00),活动推送内仅允许中奖一次。
阅读原文,直达“ KDD”小组,了解更多会议信息!

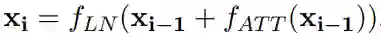
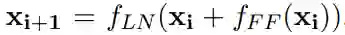
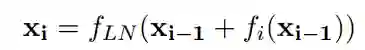
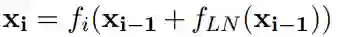

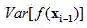 方差。
方差。
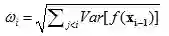 按照上述公式进行前向操作,并更新参数。训练完成之后,重新参数化模型,例如最简单的操作,移除
按照上述公式进行前向操作,并更新参数。训练完成之后,重新参数化模型,例如最简单的操作,移除