听说你还没读过 Bert 源码?
作者:老宋的茶书会
知乎专栏:NLP与深度学习
研究方向:自然语言处理
前言
前几天面试,有面试官直接拿 bert 的源码让我分析,emm, 有点厉害呀。还好老宋底子可以, 之前看过 Transformer 的实现,自己也用 Transformer 写了一下文本分类任务,没有难住我,哈哈哈哈。
不过,看来,如今,面试官们已经不满足仅仅只问原理了, 倒也是,如何看出一个人的代码能力,看看他读源码的能力就能看得出来。
因此,老宋觉得各位真的要看一看 Bert 的源码了, 于是,我花了一个下午,屡清楚各个代码,并且对关键地方做了注释, 大家可以看一看我的仓库:BERT-pytorch (https://github.com/songyingxin/BERT-pytorch)
1. 整体描述
BERT-Pytorch 在分发包时,主要设置了两大功能:
bert-vocab :统计词频,token2idx, idx2token 等信息。对应
bert_pytorch.dataset.vocab中的build函数。bert:对应
bert_pytorch.__main__下的 train 函数。
为了能够调试,我重新建立了两个文件来分别对这两大功能进行调试。
1. bert-vocab
python3 -m ipdb test_bert_vocab.py # 调试 bert-vocab其实 bert-vocab 内部并没有什么重要信息,无非就是一些自然语言处理中常见的预处理手段, 自己花个十分钟调试一下就明白了, 我加了少部分注释, 很容易就能明白。
内部继承关系为:
TorchVocab --> Vocab --> WordVocab2. 模型架构
调试命令:
python3 -m ipdb test_bert.py -c data/corpus.small -v data/vocab.small -o output/bert.model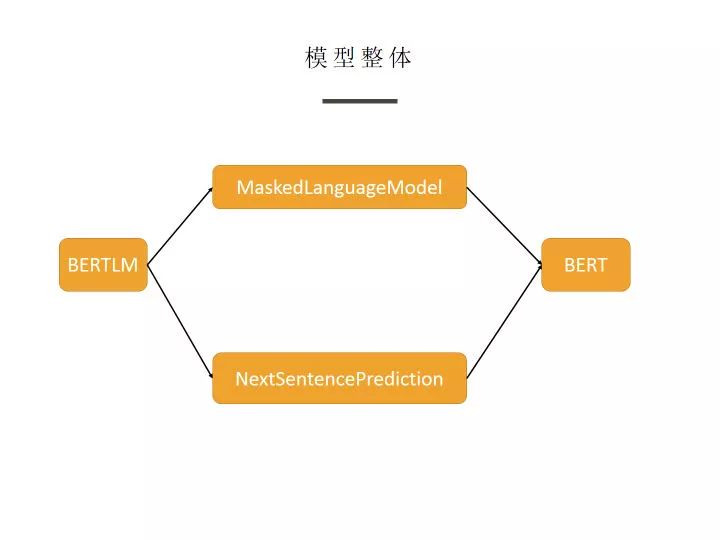
从模型整体上看, 分为两大部分: MaskedLanguageModel 与 NextSentencePrediction ,并且二者都以 BERT 为前置模型,在分别加上一个全连接层与 softmax 层来分别获得输出。
这段代码相对很简单,十分容易理解,略过。
1. Bert Model
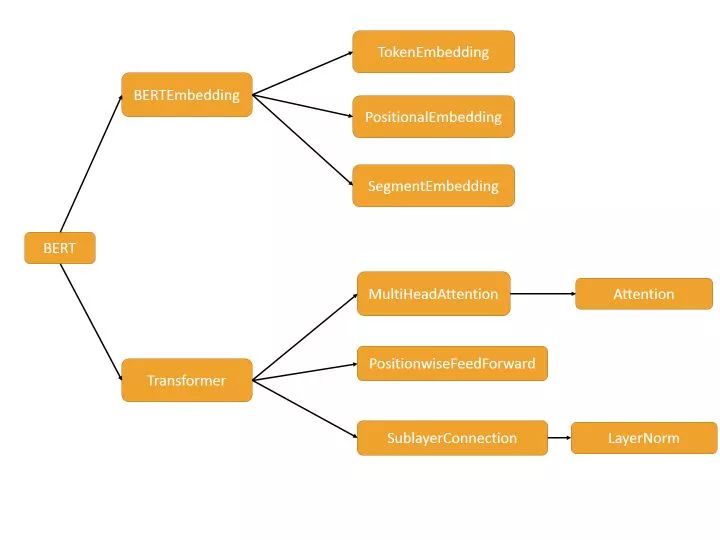
这部分其实就是 Transformer Encoder 部分 + BERT Embedding, 如果不熟悉 Transformer 的同学,恰好可以从此处来加深理解。
这部分源码阅读建议可先大致浏览一下整体, 有一个大致的框架,明白各个类之间的依赖关系,然后从细节到整体逐渐理解,即从上图看,从右往左读,效果会更好。
1. BERTEmbedding
分为三大部分:
TokenEmbedding :对 token 的编码,继承于
nn.Embedding, 默认初始化为 :N(0,1)SegmentEmbedding: 对句子信息编码,继承于
nn.Embedding, 默认初始化为 :N(0,1)PositionalEmbedding: 对位置信息编码, 可参见论文,生成的是一个固定的向量表示,不参与训练
这里面需要注意的就是 PositionalEmbedding, 因为有些面试官会很抠细节,而我对这些我觉得对我没有啥帮助的东西,一般了解一下就放过了,细节没有抠清楚,事实证明,吃亏了。
2. Transformer
这里面的东西十分建议对照论文一起看,当然,如果很熟的话可以略过。我在里面关键的地方都加上了注释,如果还是看不懂的话可以提 issue, 这里就不赘述了。
最后
我个人觉得 Google 这个代码写的真的是漂亮, 结构很清晰, 整个看下来不用几个小时就能明白了, 推荐采用我的那种调试方式从头到尾调试一遍,这样会更清晰。
觉得不错,点个赞可好。
本文由作者授权AINLP原创首发于公众号平台,点击'阅读原文'直达原文链接,欢迎投稿,AI、NLP均可。





