图神经网络的新基准

作者 | 李光明
编辑 | 贾 伟

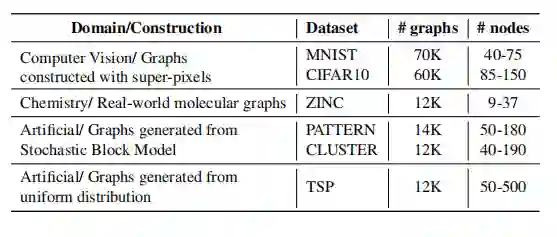
TU数据集上的图分类
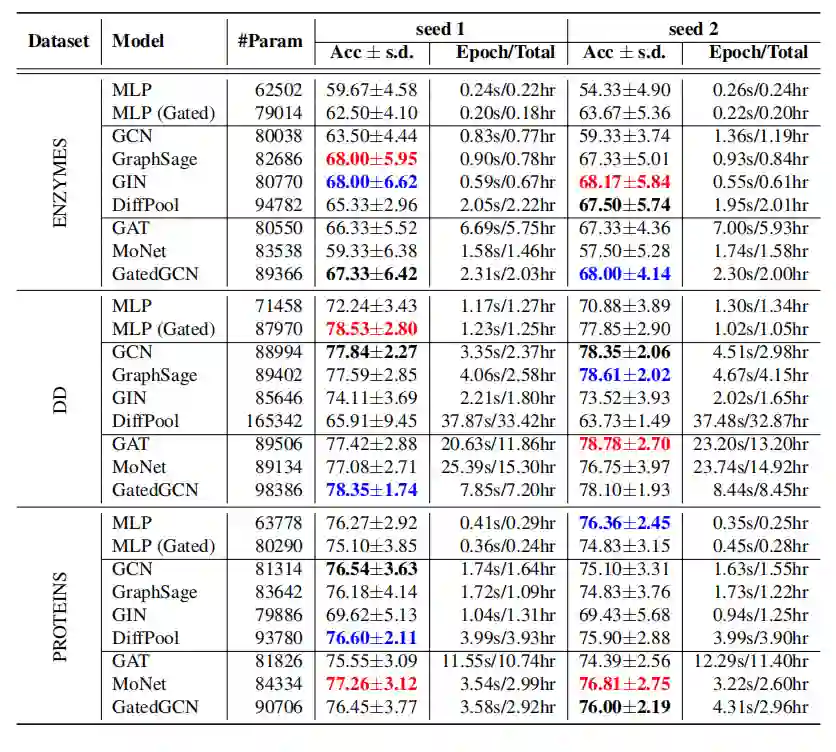
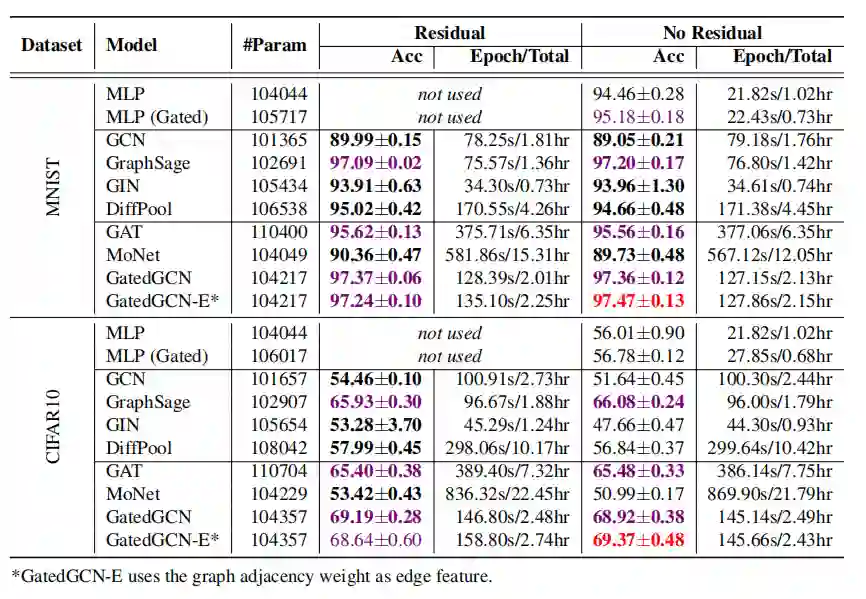
超像素数据集的图分类

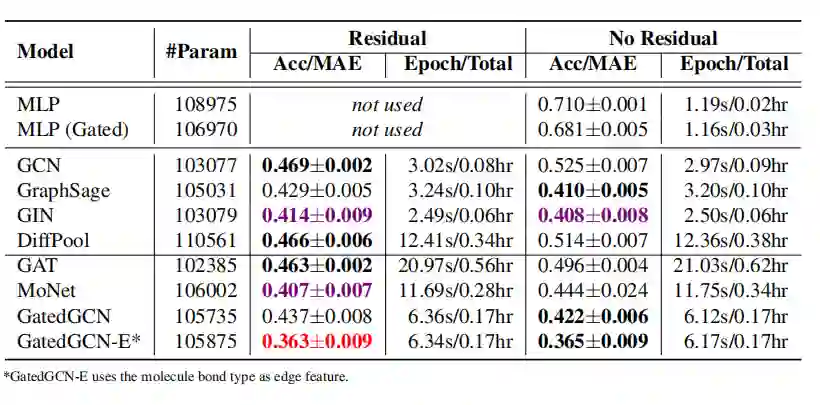
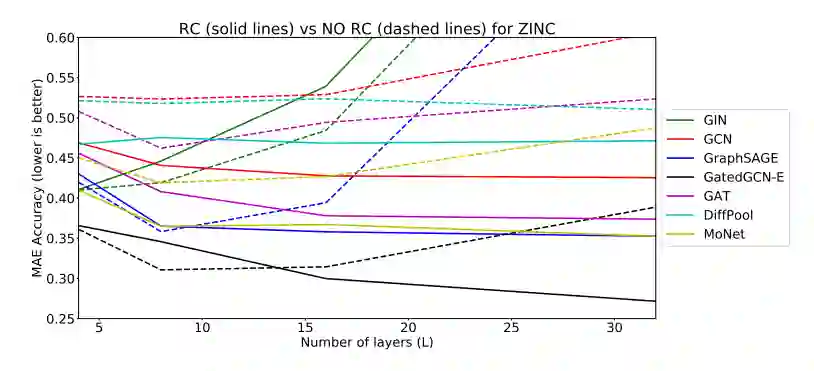
分子数据集上的图回归
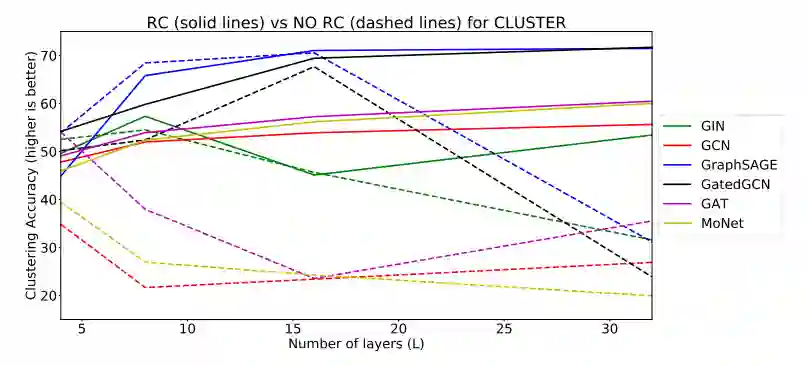
SBM数据集的节点分类
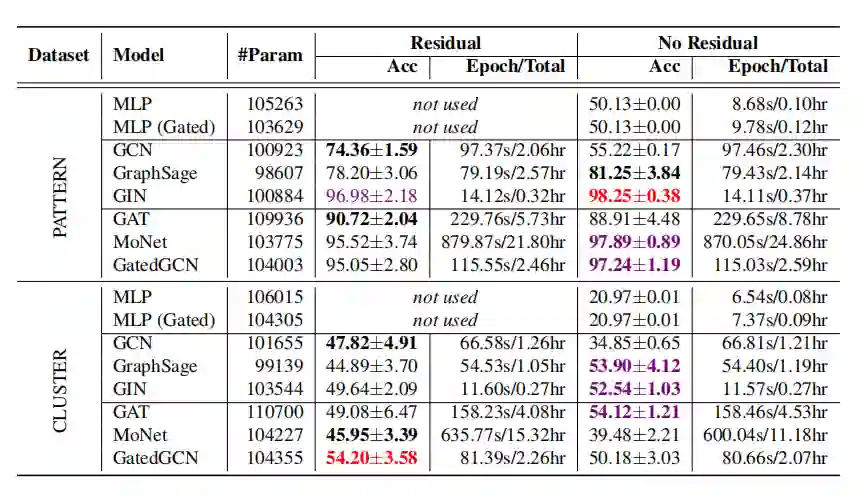
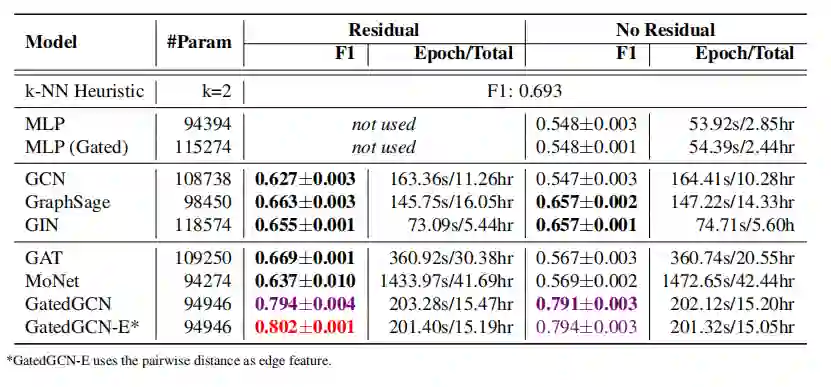
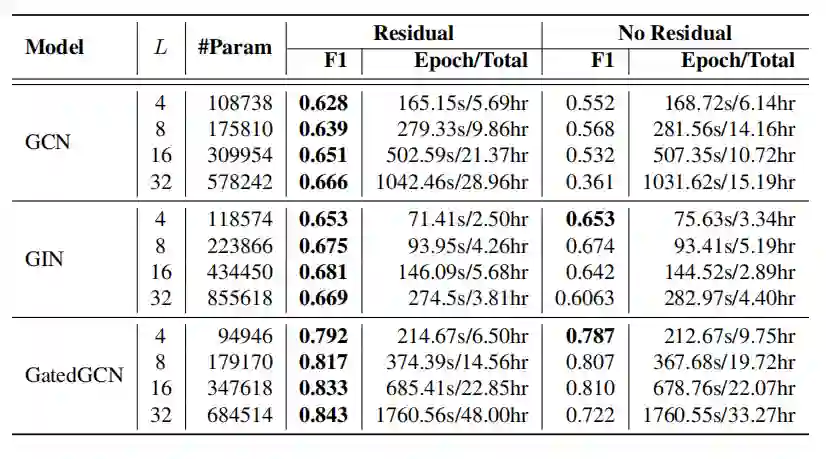
TSP数据集上的边分类
-
在小数据集上非图的NN(MLP)也可以得到较好的结果; -
在大数据集上,GNN表现远超非图NN; -
简单形式的GNN(如GCN)不会有太好的效果; -
各向同性的GNN在原始的GCN上有所改进,比如GraphSage, GIN以及DiffPool; -
各向异性的GNN也是有效的,比如门限图卷积网络,图注意力网络等; -
残差连接能够提升模型效果; -
正则化能够提升模型效果。

登录查看更多
相关内容
Arxiv
14+阅读 · 2019年3月5日




相关VIP内容
相关资讯
相关论文
Arxiv
14+阅读 · 2019年3月5日