

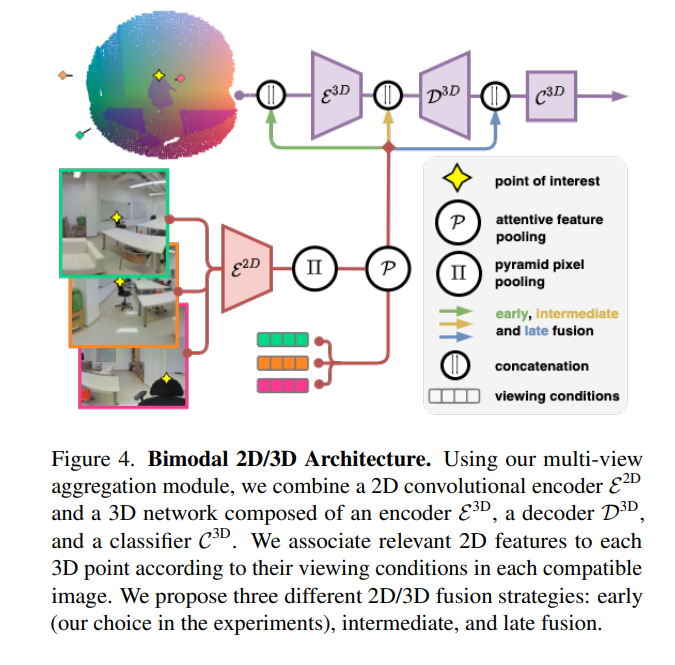
最近关于3D语义分割的工作提出利用图像和点云之间的协同作用,通过一个专用的网络处理每个模态,并将学习到的2D特征投影到3D点上。合并大规模点云和图像提出了几个挑战,如构建点和像素之间的映射,以及在多个视图之间聚合特征。目前的方法需要网格重建或专门的传感器来恢复遮挡,并使用启发式选择和聚集可用的图像。相反,我们提出了一个端到端可训练的多视图聚合模型,利用3D点的观看条件来合并在任意位置拍摄的图像的特征。我们的方法可以结合标准的2D和3D网络,在不需要着色、网格化或真实深度地图的情况下,优于彩色点云和混合2D/3D网络上运行的3D模型。我们在S3DIS (74.7 mIoU 6-Fold)和KITTI360 (58.3 mIoU)上设置了大规模室内外语义分割的最新技术。我们的流程可以访问 https: //github.com/drprojects/DeepViewAgg,只需要原始3D扫描和一组图像和姿势。
成为VIP会员查看完整内容
相关内容

Arxiv
0+阅读 · 2022年6月8日
Arxiv
0+阅读 · 2022年6月7日
Arxiv
23+阅读 · 2021年9月29日

相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2022年6月8日
Arxiv
0+阅读 · 2022年6月7日
Arxiv
23+阅读 · 2021年9月29日