【速览】ICCV 2021 | 从2D到3D的虚拟试穿模型
学会“成果速览”系列文章旨在将图像图形领域会议期刊重要成果进行传播,通过短篇文章让读者用母语快速了解相关学术动态,欢迎关注和投稿~
◆ ◆ ◆ ◆
从2D到3D的虚拟试穿模型
通讯作者:梁小丹
◆ ◆ ◆ ◆
3D虚拟试穿能够为在线购物提供直观和真实的试衣体验,现有方法主要依赖于繁杂的 3D 人体标注或者衣服扫描模版,限制了它们在多样化真实场景下的使用。另一方面,与其相关的2D试穿模型提供了更快速的解决方案,但也缺失了丰富和真实的3D表示效果。本文提出了一种结合2D和3D两方面优势的虚拟试穿方案(简称M3D-VTON),通过高效整合2D信息并引入深度预测网络其映射到3D空间,M3D-VTON 首次尝试并成功实现了从单图输入重建三维试穿网格的任务。

图 1 M3D-VTON 试穿效果示意图
虚拟试穿是以人为中心的生成领域中十分具有商业价值的研究方向。近年来研究人员的目光已经逐渐从基于物理模拟 [1] 和动态捕捉 [2] 转向基于学习重建的三维试穿领域,即直接从多张2D图片重建3D人体从而避免昂贵的物理模拟或者三维感知设备。然而,大多数基于学习的三维试穿方法依赖于参数化的SMPL人体模型 [3] 或者一些预定义的衣服模版库 [4],限制了他们的泛化性能。而且由于参数化3D表示所带来的高计算复杂度,多数现有的3D试穿模型难以达到较快的推理用时。另一方面,基于图像的2D虚拟试穿研究因其结构简单,推理速度快并且训练集容易构建等特点而得到了更为广泛的研究。多数2D试穿工作通过TPS [5] 等非刚性形变方法实现了较高质量的平面试衣渲染结果,但遗憾的是它们忽略了潜在的3D人体信息,在最终的表现形式上也欠缺 3D 试穿的逼真视觉效果。
为了解决上述 2D/3D 试穿的瓶颈限制,我们提出了一个轻量且有效的单图到 3D 虚拟试穿网络(Monocular-to-3D Virtual Try-On Network),简称为 M3D-VTON。M3D-VTON 结合了 2D 虚拟试穿和人体深度图估计来重建出最终的 3D 试穿结果。同时,为了更准确地进行衣物和目标人物的几何对齐,我们设计了一个自适应的预对齐策略来缓解 TPS 变形的难度,形成的两阶段变形有效提高了输入特征匹配精度。另外,我们创新性地利用深度梯度损失来捕捉输入单图中所隐含的“影子”即亮度变化信息,引导网络恢复出深度图中复杂的细节几何变化。最后,我们构建了一个新的合成数据集 MPV-3D 来支撑本文的训练需求。
M3D-VTON 主要包括三个模块,如图2所示,分别是(1)单图预测模块(Monocular Prediction Module,MPM),(2)深度优化模块(Depth Refinement Module,DRM)和(3)纹理融合模块(Texture Fusion Module,TFM)。整个框架的输入是一张目标衣服图像
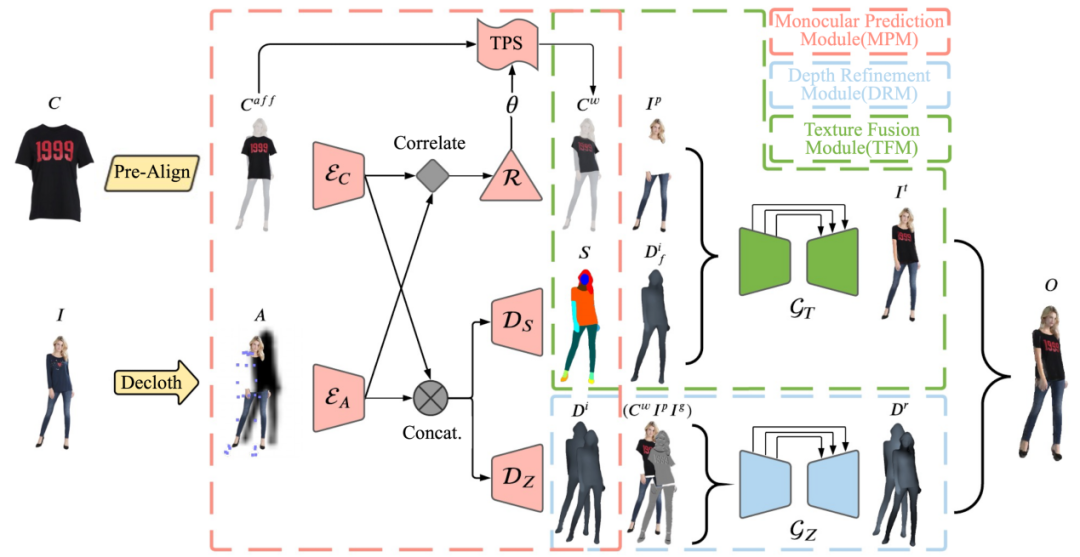
图 2 M3D-VTON 框架图
其中,MPM 在整个框架中起到基石作用,它为另外两个模块提供支持。具体地,MPM 通过一个多任务编码解码网络同时实现如下三个目标:(1)通过人体关键点和人体分割去除掉输入人物
从图3可以看出,由于目标衣服和参考人物之间的尺寸相差过大,导致直接回归两者之间的 TPS 变形参数变得十分苦难,因此我们提出了一个自适应的预对齐策略来缓解 TSP 的变形压力。具体地,该策略通过 (1) 式将目标衣服
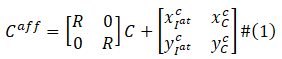
上式旋转因子
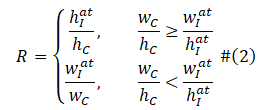
其中
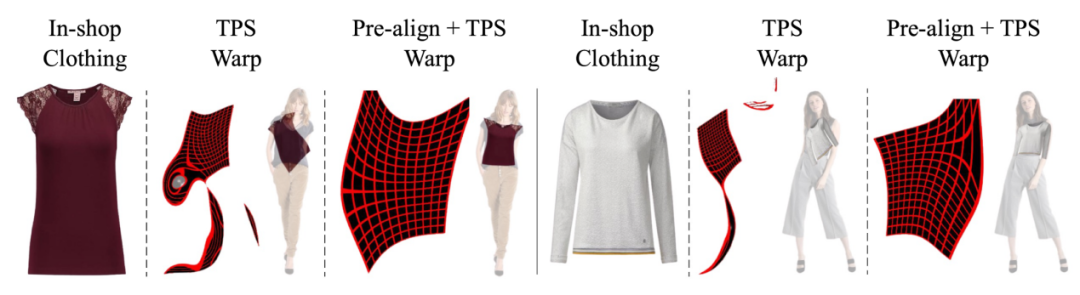
图 3 自适应预对其策略示意图
图3展示了自适应预对齐的可视化消融实验图,可见带有预对齐的 TPS 能够更容平滑且更准确地将目标衣服变形到参考人物相应位置上。
对于深度预测,传统的 L1 深度损失仅对z-轴方向敏感,且较多聚焦于低频损失分量, 因此我们在 DRM 中首先将 L1 深度损失修改为对数 L1 损失以引导网络关注近距离人体深度点,其具体形式如下式 (3) 所示:
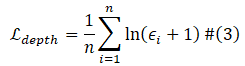
其中
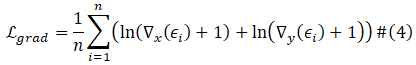
其中
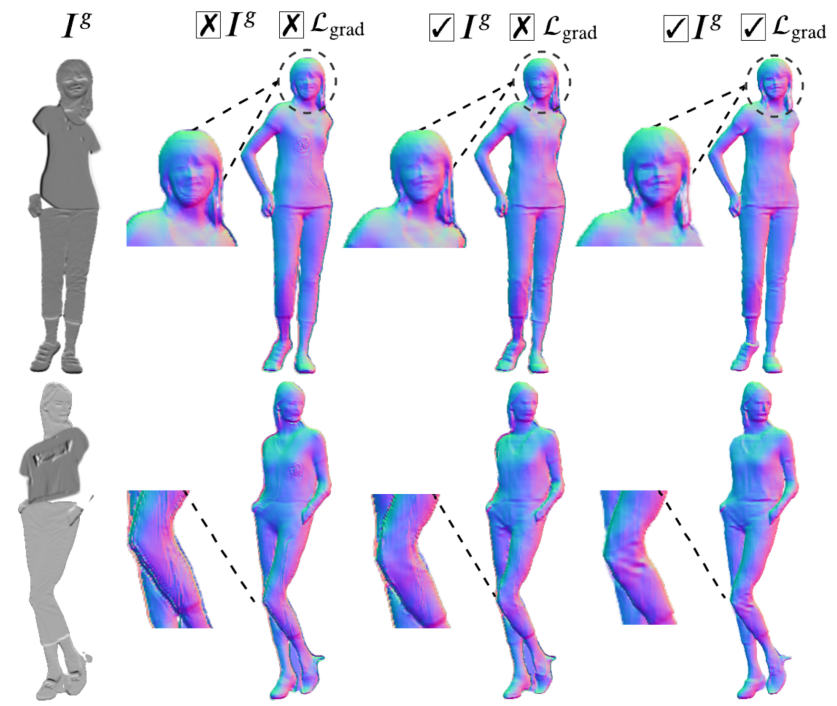
图 4 深度梯度损失优化深度图细节示意图
纹理融合过程中,我们首次引入了深度图作为先验信息,并通过它与人体语义分割图的联合指导来更好的融合变形衣服和参考人物。图2绿色虚线框中的 TFM 同时接受
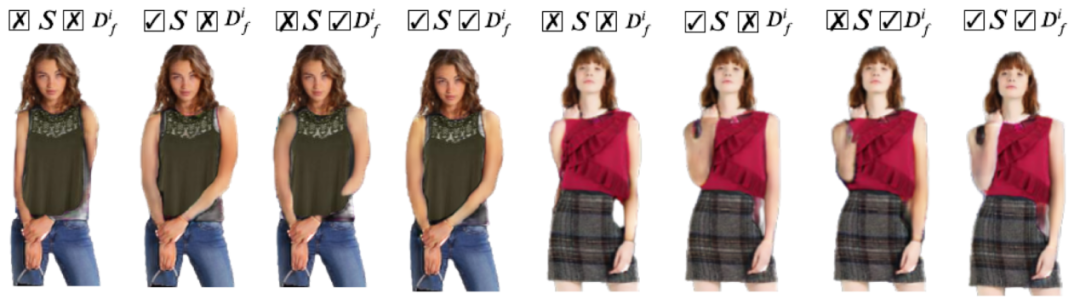
图6展示了 M3D-VTON 的纹理生成结果跟其他四个相关的 2D 虚拟试穿工作的定性可视化比较,我们的方法能够更准确的保留衣服的纹理细节并且有效解决了人体自遮挡问题,渲染出了高质量的 2D 试穿结果。

图 6 试穿纹理生成可视化比较结果
由于我们是第一个提出从单图到三维的试穿网络,所以并无可以直接比较的 3D 试穿工作,于是我们设计了二维试穿加三维人体重建的混合模型来进行比较。具体地,我们采用 CP-VTON [7] 作为二维试穿模型,将其试穿结果分别送入到 PIFu [8],NormalGAN [9] 和 Deephuman [10] 三个人体重建网络中得到相应的 3D 试穿结果。它们与 M3D-VTON 的可视化比较如图7所示:

图 7 M3D-VTON 与其他基线三维试穿模型结果可视化比较
进一步,表1和表2量化比较了 M3D-VTON 与上述 2D 和 3D 虚拟试穿工作的结果。可见 M3D-VTON 在定量指标上同样优于所比较的其他方法。
表 1 M3D-VTON 与基线二维虚拟试穿方法定量比较
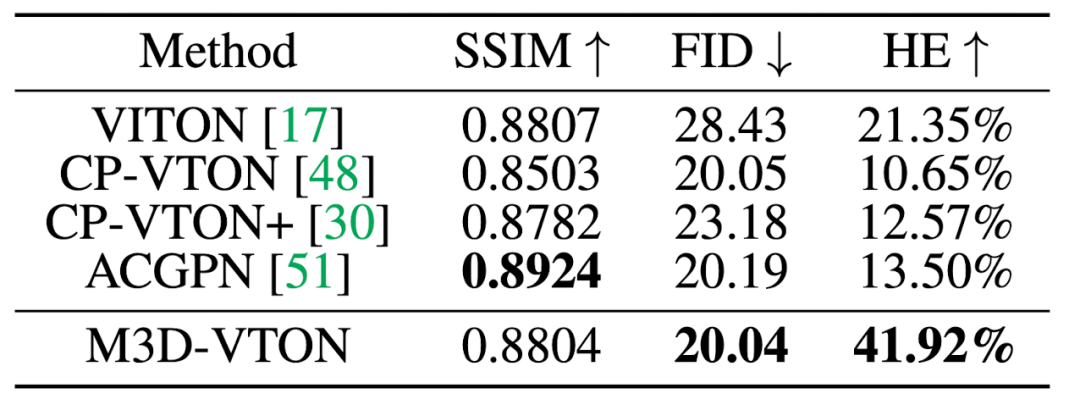
表 2 M3D-VTON 与基线三维虚拟试穿方法定量比较

上述提到 M3D-VTON 是第一个尝试解决从单图到三维的虚拟试穿问题,现有数据集并不能满足模型的训练需求。因此我们基于二维试穿数据集 MPV [11] 构建了一个新的合成数据集,称为MPV-3D。MPV-3D 在 MPV 的基础上对每个人物图像添加了相对应的正背面深度图
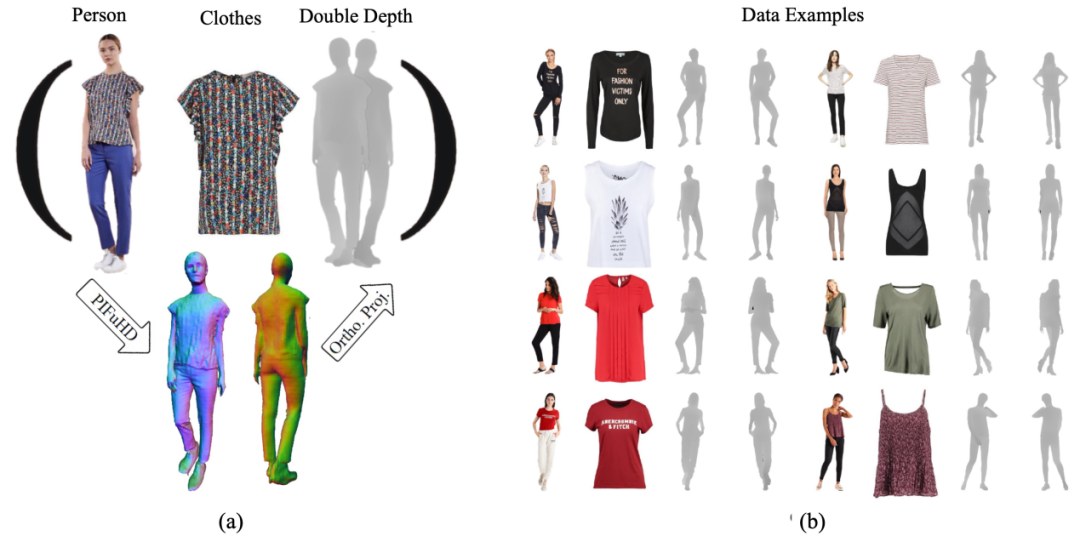
图 8 (a)MPV-3D 构建过程,(b)MPV-3D 数据集样例
本文提出一种从单图到三维的多模块虚拟试穿网络 M3D-VTON。M3D-VTON 将三维虚拟试穿问题解耦成一个深度估计问题和一个图像纹理生成问题,两者分别对应最终三维试穿网格的几何形状和纹理颜色。网络首先利用 MTM 模块学习互益特征,随后通过 TFM 和 DRM 模块将这些特征有效结合起来从而得到更加细化的三维试穿结果。同时我们也构建了一个新的合成数据集以期促进相关领域的发展。M3D-VTON 相比二维试穿在表现形式上更加丰富,同时比现有纯三维试穿方法更加快速轻量,提供了一种可行的三维虚拟试穿解决方案。
[1] Bridson, Robert & Marino, S & Fedkiw, R. (2003). Simulation of Clothing with Folds and Wrinkles. ACM SIGGRAPH/Eurographics Symposium on Computer Animation. 10.1145/1198555.1198573.
[2] Pons-Moll, G., Pujades, S., Hu, S., & Black, M.J. (2017). ClothCap: seamless 4D clothing capture and retargeting. ACM Trans. Graph., 36, 73:1-73:15.
[3] Loper, Matthew et al. “SMPL: a skinned multi-person linear model.” ACM Trans. Graph. 34 (2015): 248:1-248:16.
[4] Bhatnagar, Bharat Lal et al. “Multi-Garment Net: Learning to Dress 3D People From Images.” 2019 IEEE/CVF International Conference on Computer Vision (ICCV) (2019): 5419-5429.
[5] Bookstein, Fred L.. “Principal Warps: Thin-Plate Splines and the Decomposition of Deformations.” IEEE Trans. Pattern Anal. Mach. Intell. 11 (1989): 567-585.





