Word2Vec还可以这样图解
Word2Vec的含义
一个单词,神经网络理解不了,需要人转换成数字再喂给它。最naive的方式就是one-hot,但是太过于稀疏,不好。所以在改进一下,把one-hot进一步压缩成一个dense vector。
word2vec算法就是根据上下文预测单词,从而获得词向量矩阵。
预测单词的任务只是一个幌子,我们需要的结果并不是预测出来的单词,而是通过预测单词这个任务,不断更新着的参数矩阵weights。
预测任务由一个简单的三层神经网络来完成,其中有两个参数矩阵V与U,V∈RDh*|W|,U∈R|W|*Dh。
V是输入层到隐藏层的矩阵,又被称为look-up table(因为,输入的是one-hot向量,一个one-hot向量乘以一个矩阵相当于取了这个矩阵的其中一列。将其中的每一列看成是词向量)
U是隐藏层到输出层的矩阵,又被称为word representation matrix(将其中的每一行看成是词向量)
最后需要的词向量矩阵是将两个词向量矩阵相加 =V+UT,然后每一列就是词向量。
两种实现方法
2.1. Skip-Gram
训练任务:根据中心词,预测出上下文词
输入:一个中心词(center word,x∈R|W|*1)
参数:一个look up table V∈RDh*|W|,一个word representation matrix U∈R|W|*Dh

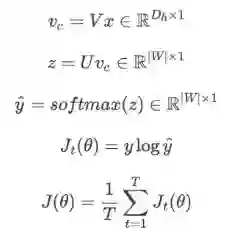
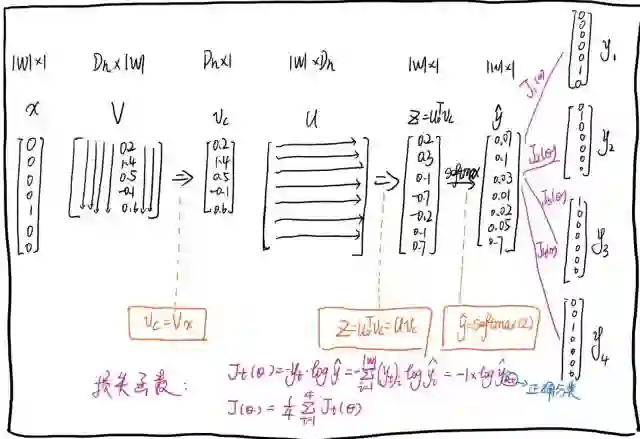
Skip-Gram步骤图:
2.2. CBOW
与Skip-Gram相反,是通过完成上下文词预测中心词的任务来训练词向量的。

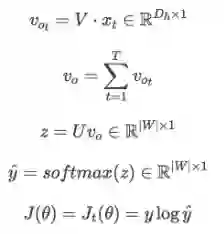
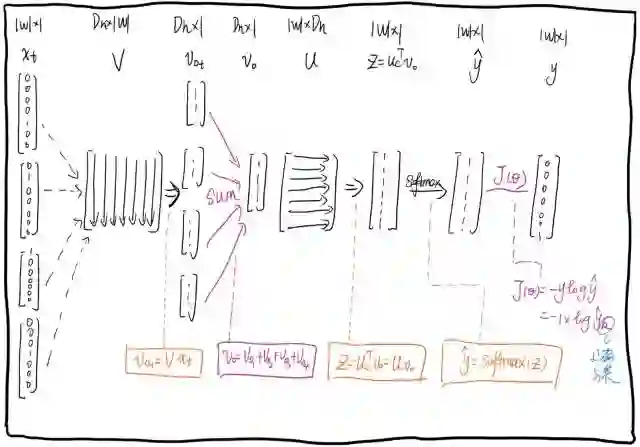
CBOW步骤图:

CSDN AI热衷分享 欢迎扫码关注
登录查看更多
相关内容

Arxiv
5+阅读 · 2020年6月10日


相关VIP内容
相关资讯
相关论文
Arxiv
5+阅读 · 2020年6月10日