基础|Word2vec的原理介绍

-欢迎加入AI技术专家社群>>
一,词向量的概念
将 word映射到一个新的空间中,并以多维的连续实数向量进行表示叫做“Word Represention” 或 “Word Embedding”。自从21世纪以来,人们逐渐从原始的词向量稀疏表示法过渡到现在的低维空间中的密集表示。用稀疏表示法在解决实际问题时经常会遇到维数灾难,并且语义信息无法表示,无法揭示word之间的潜在联系。而采用低维空间表示法,不但解决了维数灾难问题,并且挖掘了word之间的关联属性,从而提高了向量语义上的准确度。
二,词向量模型
a) LSA矩阵分解模型
采用线性代数中的奇异值分解方法,选取前几个比较大的奇异值所对应的特征向量将原矩阵映射到低维空间中,从而达到词矢量的目的。
b) PLSA 潜在语义分析概率模型
从概率学的角度重新审视了矩阵分解模型,并得到一个从统计,概率角度上推导出来的和LSA相当的词矢量模型。
c) LDA 文档生成模型
按照文档生成的过程,使用贝叶斯估计统计学方法,将文档用多个主题来表示。LDA不只解决了同义词的问题,还解决了一次多义的问题。目前训练LDA模型的方法有原始论文中的基于EM和 差分贝叶斯方法以及后来出现的Gibbs Samplings 采样算法。
d) Word2Vector 模型
最近几年刚刚火起来的算法,通过神经网络机器学习算法来训练N-gram 语言模型,并在训练过程中求出word所对应的vector的方法。本文将详细阐述此方法的原理。
三,word2vec 的学习任务
假设有这样一句话:今天 下午 2点钟 搜索 引擎 组 开 组会。
任务1:对于每一个word, 使用该word周围的word 来预测当前word生成的概率。如使用“今天、下午、搜索、引擎、组”来生成“2点钟”。
任务2:对于每一个word,使用该word本身来预测生成其他word的概率。如使用“2点钟”来生成“今天、下午、搜索、引擎、组”中的每个word。
两个任务共同的限制条件是:对于相同的输入,输出每个word的概率之和为1。
Word2vec的模型就是想通过机器学习的方法来达到提高上述任务准确率的一种方法。两个任务分别对应两个的模型(CBOW和skim-gram)。如果不做特殊说明,下文均使用CBOW即任务1所对应的模型来进行分析。Skim-gram模型分析方法相同。
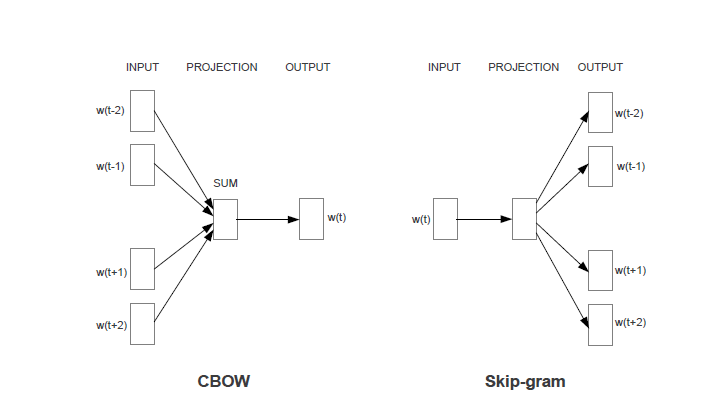
四,使用神经网络来训练
此图是原始的未经过优化的用于训练上节提到的任务的神经网络模型。该模型有三层结构,输入层(投影层),隐藏层,输出层。
其中输入层和传统的神经网络模型有所不同,输入的每一个节点单元不再是一个标量值,而是一个向量,向量的每一个值为变量,训练过程中要对其进行更新,这个向量就是我们所关心的word所对应的vector,假设该向量维度为D。该层节点个数为整个语料库中的不同word的个数,设为V。
隐藏层和传统神经网络模型一样,使用激活函数为tanh 或sigmoid均可。假设该层节点个数为H。
输出层同样和传统神经网络模型一样,节点个数为整个语料库中的不同word的个数,即V。另外如果你认认真真的学过神经网络稀疏自编码的知识就会知道,如果将输入层和输出层之间再构建一层传递关系,更有利于提高该模型的准确度。
时间复杂度分析,对于上一节中所举得例子,我们知道输入是N个word,输出是“2点钟”。它所对应的时间复杂度为N * D + N * D * H + N *D * V + H * V。其中D和H大约在100和500之间,N是3到8,而V则高达几百万数量级。因此该模型的瓶颈在后面两项。接下来我们要讨论的问题就是如何解决这个时间复杂度的问题。
对于输入层到输出层的网络,我们可以直接将其剔除掉,实验证明,该措施并不会带来很多效果上的下降,反而省去了大部分计算时间。之所以隐藏层到输出层计算量最大是因为我们对于每一个输出的word均要进行验证并使用梯度下降更新。正确的word所对应的节点为正例,其他为反例,从而达到快速收敛的目的。下两节将介绍两种不同的方法来解决此问题。
五,Hierarchical Softmax
如果我们将字典中的词分成2类,则在预测的时候我们可以先预测目标词所在的类别,这样就将直接去掉一半的测试,如果再在剩下的一半中再分成两类,则又可以去除一半的测试,一直分下去直到元素个数达两个为止。聪明的你,肯定想到了完全二叉树这个数据结构。没错!我们可以对字典建立一颗完全二叉平衡树,内部节点为分类节点,叶节点为代表每个词的节点。其中叶节点无需保存,没有实际意义,只需要保存V-1个内部节点,因为叶节点是由内部节点所确定的。
更有意思的是,我们无需根据某些语义上的区别来分类每一个词,而是随意的进行分类,神经网络模型会自动的挖掘各个类别所代表的属性。
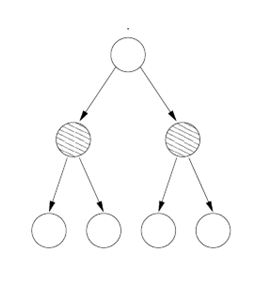
因此,我们可以记录每个词到根节点的路径,然后每次只需对路径上的节点进行预测,并采用梯度下降的算法对神经网络的参数进行更新,就可以将复杂度从原来的H*V变为H*log(V)。如果考虑词频,适用Huffman 编码,则效率可再提升2到3倍。
六,Negative Sampling
首先,有一个非常重要的定理叫Noise Contrastive Estimation,是由Gutmann 和Hyvarinen等人提出,之后被Mnih和The等人应用到语言模型中来。该定理的推倒证明已经超出本文所讲内容,有兴趣的读者可以自行阅读。
应用到这里,只需要将各个词按照其对应的TF大小来随机选取并进行反例的更新。具体如下:将各个词的TF累和设为S,算出每个词的TF所占的比例,将长度为1的区间进行划分。之后随机产生一个数r(0<r<1),对应到长度为1的区间中,取出对应的word,并进行反例更新。
总结起来就是,除了更新正确的word所对应的节点外,不在更新其他的所有反例节点,而是只选取几个反例节点进行更新。一般是10个左右。即复杂度变为10 * H。
七,退变为多个logistic regression或Softmax模型
Google research 等人又对上述模型进行改进,去除了隐藏层,重新拾起输入层到输出层的网络,并将原来的输入层起名投影层(projection layer),而且所有节点共享同一个投影层。重新加入原始的标量输入层节点表示每一个word。之后形成的神经网络和传统的神经网络几乎相同,唯一不同的是投影层没有激活函数,只有输出层有激活函数。同样使用上两节所用到的优化算法,我们可以得到以下模型。摘自网络
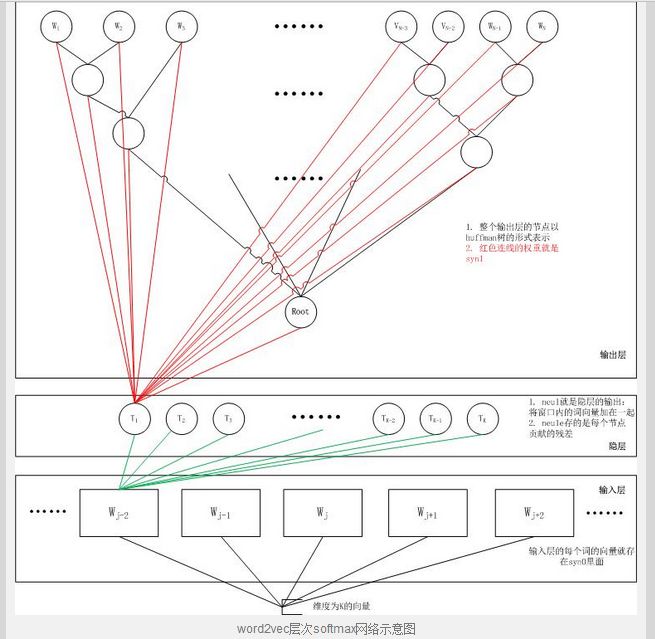
八,加速方法总结
a) 删除隐藏层
b) 使用Hierarchical softmax 或negative sampling
c) 去除小于minCount的词
d) 根据一下公式算出每个词被选出的概率,如果选出来则不予更新。此方法可以节省时间而且可以提高非频繁词的准确度。
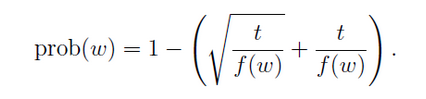
其中t为设定好的阈值,f(w) 为w出现的频率。
e) 选取邻近词的窗口大小不固定。有利于更加偏重于离自己近的词进行更新。
f) 多线程,无需考虑互斥。
九,特性
Vectors(man) – vectors(woman) + vectors(daughters) = vectors(son)
LDA等其他模型无此性质。
博客链接:http://blog.sina.com.cn/s/blog_4bec92980102v7zc.html

↓ 点击阅读原文,进入“机器学习和深度学习(深圳班)”报名





