LibRec 每周算法:Kaggle竞赛利器之xgboost
xgBoost[1]作为GBM(Gradient Boosting Machine,或称为Boosted Tree、GBDT、GBRT或LambdaMART等)类算法的一种有效优化和高性能系统实现,使其成为Kaggle竞赛冠军选手的最常用工具,而且由于其效果好,计算复杂度不高,使其也在工业界中有大量的应用。
从使用模型的数量上,监督学习算法可分为单模型算法和集成学习(多模型)算法。GBM是集成学习中的一类算法,即通过Boosting的思想集成多个算法(分类器)的效果。如前所述,xgBoost本身是GBM算法类中的一种,所以在学习xgBoost之前,需要先搞清楚GBM算法的一般设计思路。
1. GBM解析
理解一个监督学习算法,主要要搞清楚三个重要构成部件:模型(包括参数)、目标函数和求解方式。下面也从这三个方面解析GBM算法。
1.1 GBM模型
如前所述,GBM是属于集成学习的一种,而每一个集成学习算法都有自己的基分类器,其中GBM的基分类器一般为回归树,也称为CART(Classification And Regression Trees)[2]。回归树的本质为把输入样本根据该样本的特征分配到回归树的各个叶子节点上,而每个叶子节点上面都会对应一个预测的实数分值。回归树可看为决策树的一个扩展,从简单的分类优化为预测分值,这样就可以使其用于解决除分类之外的概率预测和排序等问题。
1.2 GBM的目标函数
一般机器学习模型的目标函数设计会包含两部分:损失函数(loss function)和正则化项。其中,损失函数鼓励模型尽量去拟合训练数据,而正则化项则用于使得到的模型更加简单和随机性比较小,不容易过拟合。
GBM的目标函数可表示为:
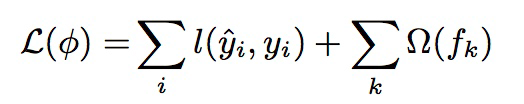
等号右边的第一项即为损失函数,第二行即为正则项,这两项都是可以自己设计的,比如在此处正则项可以设计为回归树的复杂度,而不是最常用的L1或L2正则等。需要说明的是在xgBoost中也支持自定义损失函数,只要其满足二阶可导即可。另外,
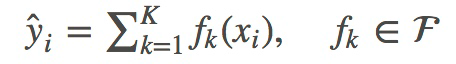
每个函数fk对应了函数空间(F)里的一个函数(比如回归树),同时可以将F简单理解为回归树的集合(tree ensemble)。
1.3 GBM的求解方式
求解方式可以高大上的称为模型训练或者模型学习等,此处之所以称为求解方式,是为了便于大家理解,就像求解一元二次方程的最值一样,当然其本质都是运筹学中的优化问题,只是难度略有不同。
言归正传,谈到模型学习,大家首先想到的应该是SGD(及其各种变种)或者MCMC等,但这些学习方式不适用于boosting类集成学习,因为其训练参数已从参数空间变为函数空间,或者简单理解为由训练一组变量变为训练一组函数(比如回归树)。
此时我们会采用一种叫做additive training的方式,即每一次保留原来的训练模型(回归树)不变,加入一个新的模型到原来的模型中。其中,数学表示如下:

代入到GBM的目标函数,得到:
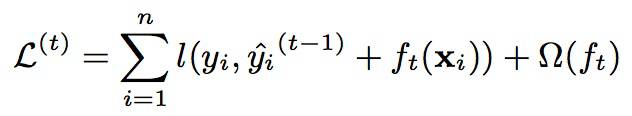
所以,这时我们只需要找到当前使目标函数值降低最大的模型(回归树)就可以了,但不幸的是这是个NP难问题,所以GBM在枚举所有不同树结构的时候会采用贪心法的思路,求得局部最优解。具体如何获得每一轮迭代的fk呢?下面通过xgBoost的实现方式具体介绍一下。
2. xgBoost的优化设计
2.1 目标函数推导
xgBoost的整个推导过程是比较精彩的,大体思路是:首先将上面GBM的目标函数通过泰勒公式二阶展开,然后基于树型函数的特点,将目标函数转化为简单的一元二次函数以求近似最小值的问题。
1. 目标函数泰勒公式展开:
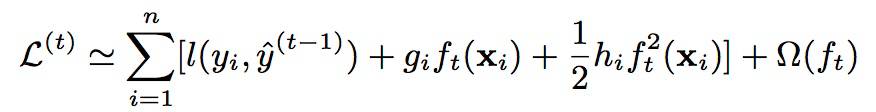
其中:
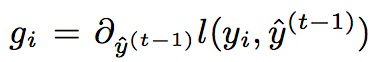
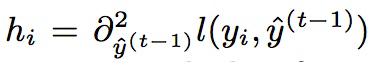
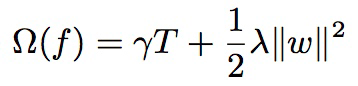
2. 转化为一元二次函数求最值:
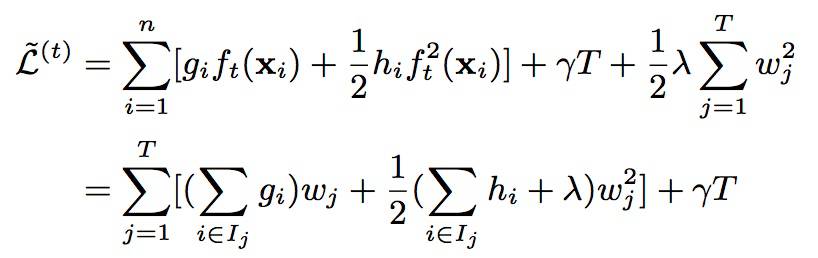
3. 求解目标函数,得到其取最小值时的表达式:
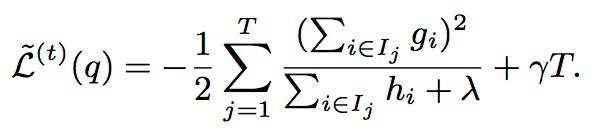
进而可简化表示为:
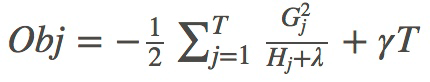
其中,
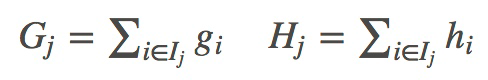
到此步,整个推导过程就结束了。当然上面的推导相对粗糙,只是罗列了关键步骤,主要是因为网上相关文章已经很多,在此不想过多赘述。(推荐陈天奇自己的一篇blog[3]。)
得到了目标函数的最小值表达式有什么用呢?它的作用就是判断当前回归树的好坏和是否需要继续分裂树节点的依据,因为通过该公式我们可以给每一颗回归树打分,称为结构分数(structure score)。举例如下:
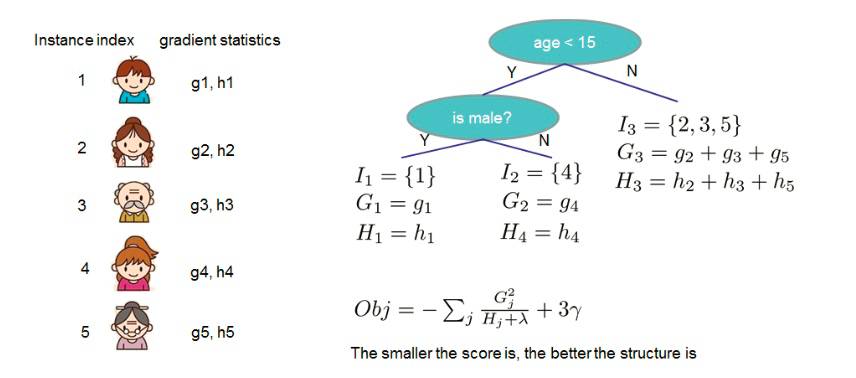
由上图可知,只要loss function确定后,通过计算每个样本的gi和hi值,进而计算每个叶节点的Gj和Hj值,就可以得到一个回归树的结构分数。
2.2 树节点分裂方法
众所周知,针对节点分裂的方法,ID3算法采用信息增益、C4.5算法采用信息增益率和CART采用Gini系数,而xgBoost是基于结构分数设计的,对于特定的节点分裂方案,其增益计算公式如下:
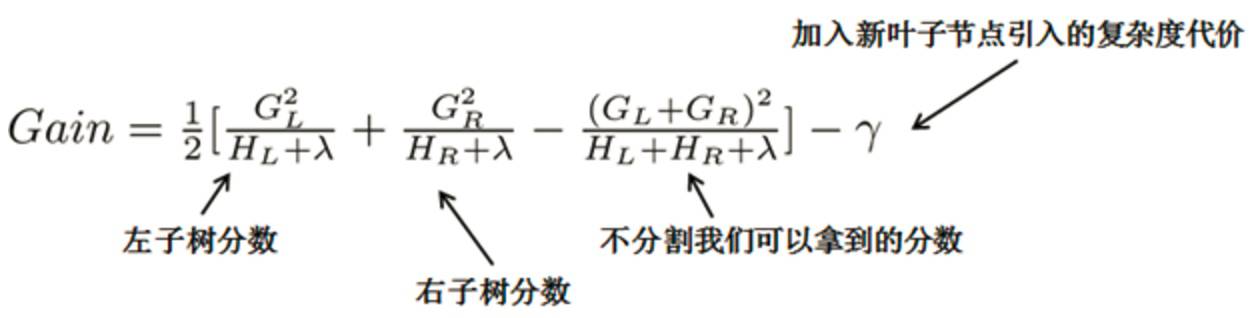
此时我们就可通过设置一个阈值,当增益大于该阈值时,才可进行节点分裂,否则我们就剪掉这个分割,即剪枝。
每一次确定当前回归树的分裂方案,我们需要枚举当前所有的叶子节点(特征)和每个叶子节点中的所有特征值的增益,进而选取最大增益对应的分割,xgBoost也给出了枚举方案:

同时,由于上述暴力枚举的复杂较高,xgBoost也设计了近似分裂方案:针对每个树(global),选取候选分裂结点,针对每个特征(local),只枚举特定分位数对应的特征值。 具体如下:

最后,xgBoost在缺省值分裂方式、行/列抽样、学习速率(Shrinkage)等算法设计方面也做了一些工作,效果良好。
2.3 系统实现优化
xgBoost在系统实现上做了一些并行方面的优化:
特征粒度并行:对于每次分裂,针对每个样本的gi和hi,xgBoost只需要计算一遍,排序后存入到一个block结构中,之后所有的特征分割方案只需取出相关样本,计算Gj和Hj,代入增益计算公式,并行计算即可。
近似直方图算法:针对数据无法一次载入内存或者分布式计算的情况,xgboost提出了一种可并行的近似直方图算法,用于快速生成候选分割点。
3. xgBoost的使用
因为xgBoost的core是C++写的,从源码编译的话需要安装一些工具,比如cmake、clang和openMP(可选)等,然后打包jvm-packages需要maven,具体可参考官方教程[4],当然编译或打包过程中你可能会遇到一些bugs,google掉它即可。
同时,xgBoost提供了基于jvm的实现版本xgBoost4j[5],并且基于Rabit使其可以运行在Spark/Flink等分布式计算平台上。下面是Spark版本的代码片段:

4. 总结
本文主要从算法设计的角度介绍了xgBoost算法的实现过程,包括GBM解析和xgBoost的优化设计,最后简单介绍了一些xgBoost的系统实现优化和基于Spark的分布式使用。文中不妥之处,欢迎大家纠正和交流。
LibRec(https://github.com/guoguibing/librec)是领先的推荐系统Java开源库,旨在提高推荐算法的分享和应用,进一步促进推荐系统的发展,为学习和研究推荐系统的人士提供一个开放交流的平台。
猜你喜欢
LibRec 每周算法:FTRL原理与工程实践 (by Google)
参考文献
1. Tianqi Chen and Carlos Guestrin. XGBoost: A Scalable Tree Boosting System. In KDD 2016.
2. Breiman, L., Friedman, J., Stone, C. J., & Olshen, R. A. (1984). Classification and regression trees. CRC press.
3. http://www.52cs.org/?p=429
4. https://xgboost.readthedocs.io/en/latest/build.html
5. http://dmlc.ml/2016/03/14/xgboost4j-portable-distributed-xgboost-in-spark-flink-and-dataflow.html





