Kaggle亚马逊比赛冠军专访:利用标签相关性来处理分类问题

近日,Kaggle Blog上刊登了对「Planet: Understanding the Amazon from Space」比赛冠军的专访,在访问中,我们了解到了冠军选手bestfitting的一些基础信息,他在比赛中所用的一些技术细节,以及给大家的建议。
AI研习社将采访原文编译整理如下:
在最近举办的「Planet: Understanding the Amazon fromSpace」比赛中,主办方Planet为了更好地追踪和了解到森林被砍伐的原因,想要让Kaggle上的参赛选手为亚马逊盆地中的卫星图像打上标签。
主办方提供40000多张训练图像,每张图像都涵盖多个标签,标签总体分为如下几组:
大气情况:晴朗、局部多云、多云、起雾
常见的土地覆盖和使用类型:雨林、农业、河流、城镇/城市、道路、耕地、裸地
罕见的土地覆盖和使用类型:砍伐并燃烧、选择性砍伐、种植、传统采矿、手工采矿、吹毁。

近日,我们采访到本次比赛的冠军选手bestfitting,在访谈中,他为我们详细讲述了他是如何集成11个精细调节的卷积网络以及怎样利用标签相关性结构的,此外,他也谈到为了避免过拟合的一些想法。
基础信息
能谈下你参加比赛之前的专业背景吗?
我的专业是计算机科学,有超过十年的Java编程经验,目前工作方向是大规模数据处理、机器学习和深度学习。
在这次比赛中,你用到了之前的哪些经验和专业知识呢?
今年我参加了kaggle上的不少关于深度学习的比赛,在比赛中获得的经验和直觉让我受益匪浅。
你开始在Kaggle上参加比赛是基于什么契机?
从2010年开始,我就在看很多关于机器学习、深度学习的书和论文了,但是很难将我学习到的算法应用到那些可用的小数据集上。而与此同时,我发现Kaggle上有很多有意思的数据集、kernel以及不错的讨论,因此,就在去年,我迫不及待地参加了Kaggle上的“Predicting Red Hat Business Value”比赛。
参加这次比赛的原因是什么?
有两个原因。
一是我对自然保护很感兴趣,我认为要是自己的经验能让地球和人们的生活更加美好,这很酷。另外,亚马逊雨林经常在电影和故事中出现,我对它很感兴趣。
另外,我参加了kaggle上各种各样关于深度学习的比赛,比赛中都用到了分割和检测等算法,这次我希望能参加分类比赛,尝试一些不一样的东西。
技术讨论
能简单地介绍一下你的方案吗?
这是一场多标签分类比赛,并且标签是失衡的。
比赛竞争很激烈,因为这两年已经有很多使用比较广泛的图像分类算法,并且也出现了很多新算法,另外,也有很多极具经验的计算机视觉方面的参赛选手。
我尝试了很多种我认为可能会有用的流行分类算法,基于对标签关系和模型能力的认真分析,我构建了一种集成方法并赢得了比赛的第一名。
下面是模型结构:
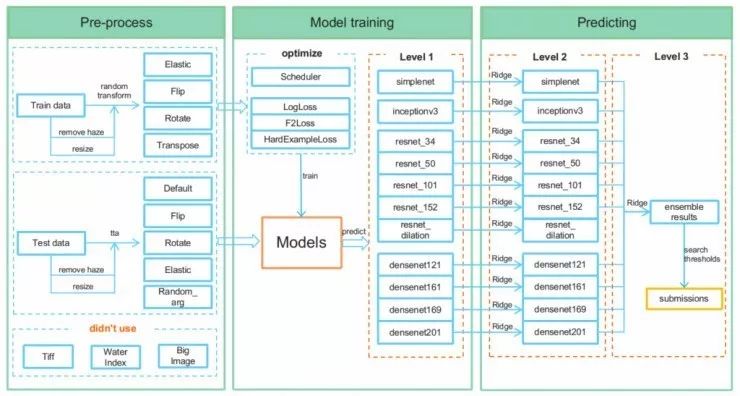
下一步,在模型阶段,我精细调节了11个卷积神经网络(CNN),得到每个CNN的类别标签概率。比赛中我用到了一些流行的、高性能的CNN,例如ResNets、DenseNets、Inception和SimpleNet等。
然后,我通过每个CNN的岭回归模型来传递类标签概率,这是为了利用标签相关性来调整概率。
最后,我利用另一个岭回归模型将这11个CNN集成到一起。
同样值得注意的是,这次比赛中,我没有使用标准log函数作为损失函数,而是使用了一个特殊的柔性F2损失函数(special soft F2-loss),这是为了得到更高的F2分数。
在预处理和特征工程阶段,你具体做了哪些操作?
预处理和数据增强步骤如下:
首先是调整图像大小。
另外,在训练集和测试集中我也做了一些数据增强,例如对图像进行翻转、旋转、置换以及一些弹性变换等。
我也用到了一种去雾技术,这种技术可以让网络“看到”更清晰的图像。关于这项技术,在论文Single ImageHaze Removal using Dark Channel Prior中有详细描述。
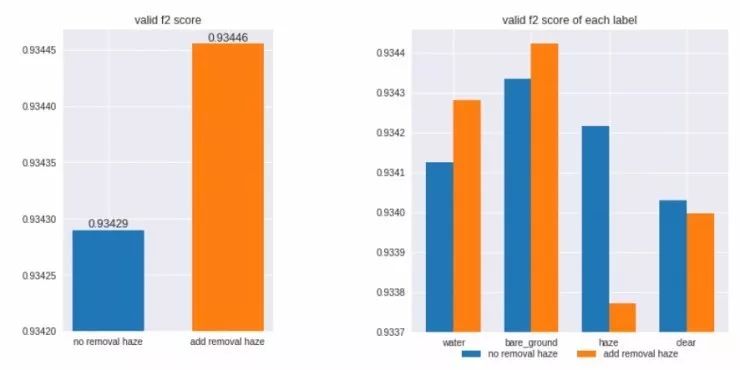
下面是在数据集中进行去雾处理的一些实例:

从下图中可以看到,进行去雾处理后,一些标签(例如水、裸地)的F2分数会升高,但同时另一些标签的F2分数(例如雾天和晴天等)会降低。不过不用担心,集成操作能为每个标签选择最强大的模型,总的来说去雾处理会让整体分数得到提升。
你用了哪些监督学习方法?
比赛模型集成了包括11种当前流行的卷积网络:融合了不同数量的参数、层数的ResNet和DenseNet,另外还有Inception和SimpleNet模型。在替换了最后的输出层以满足比赛的输出之后,我微调了这些预训练过的CNN的所有层,并且没有冻结任何层。
训练集包括4万多张图片,这个量足够满足我从头开始训练一些CNN的架构,例如resnet_34和resnet_50。不过我发现,对预训练过的网络的权重进行微调会得到更好的表现。
为了让F2分数更高,你有用到一些特别的技巧吗?
主办方会评估提交结果的F2分数,这个分数结合了精确度和召回率,有点类似于F1分数,但召回率的权重比精确度要高。因此,我们不仅要训练模型来预测标签概率,还要选择出最佳阈值,通过标签的概率值来决定是否给图片打上这个标签。
最初,和许多其他参赛者一样,我使用的是log损失作为损失函数,但如下表所示,F2分数不会随着log损失值的降低而升高。

这意味着需要找到另一种损失函数,将模型的注意力更多的集中在优化标签的召回率上。从比赛论坛的代码上受到启发,我写了一个柔性F2损失函数(Soft F2-Loss function)。
这个函数确实提高了整体F2分数,对农业、多云和耕地这三个标签的作用尤为明显。

我分析了标签之间的相关性,发现某几个标签经常共存,但其他标签没有这种情况。例如,晴朗、局部多云、多云和起雾这几个标签不会共存,但是住所和农业标签经常出现在一起。这意味着使用这种关联结构可能会使模型得到改进。
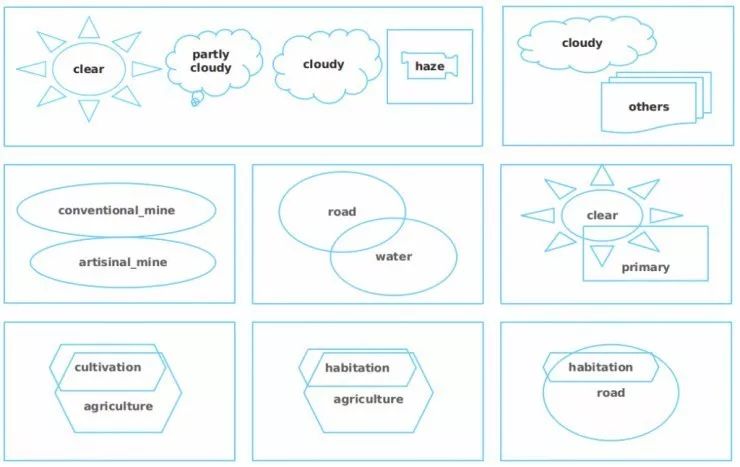
举个例子,来看一下resnet-101模型,它会预测出17个标签中每一个出现的概率。为了能利用到标签相关性,我增加了另外一个岭正则化层,来重新校准所有模型中每一个标签的概率。
换言之,为了预测晴朗这个标签的最终概率(利用resnet-101模型),有一个特殊的晴朗岭回归模型会接收resnet-101模型对所有17个标签的预测情况。

当得到所有N个模型的预测之后,我们有了来自于N个不同的模型对晴朗标签的概率。我们可以利用这些概率,通过另一个岭回归来预测最终晴朗标签的概率。
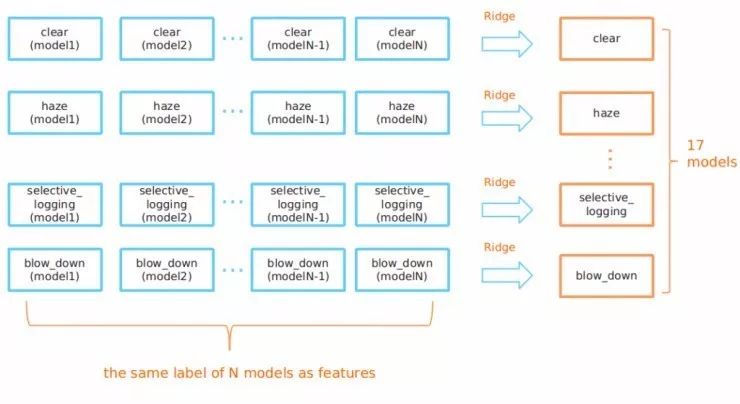
这种两层岭回归有两个作用:
一是它能让我们利用不同标签之间的关联信息。
二是它能让我们选择最强的模型来预测每个标签出现的概率。
你有哪些让自己也吓一跳的发现吗?
即使我已经预知到排行榜最后的大变动(公共排行榜和私人排行榜的分数有很大的不同),但我仍然感到惊讶。
在比赛的最后阶段(离结束还有10天),我发现公共排行榜上分数都非常接近,但我在交叉验证和分数上完全不能取得任何优化和提升了,因此我告诫自己要小心,避免在可能只是噪音标签的情况下出现过拟合。
为了在最后阶段不出错,我用不同的随机种子,选择了训练集中一半的图片作为新的训练集,来模拟出公共和私人排行榜。
我发现随着种子的改变,我模拟的公共排行榜分数和私人排行榜分数之间的差距可能会扩大到0.0025。但在公共排行榜上,第一名和第十名的差距比这一数值要小。

这意味着在比赛中可能会发生非常大的变动。
经过仔细分析后,我发现这种差异出现在一些比较有难度的图片上,人们也极易对图片中的标签产生混淆,比如一张图是该被标记为雾还是多云,道路还是积水,种植或是选择性砍伐。
正因为如此,我说服自己公众排行榜的分数并不能完美的衡量模型能力。
这是意料之外的:因为公共测试集中包含4万多张图片,看起来排行榜应该是相当稳定的。
因此,我调整了目标,只是让自己能保持在前10名之内,并决定在最后一周不用关心自己在公开排行榜上的确切名次。此外,我试图找到一种最稳定的方式来进行模型集成,我丢弃掉了任何可能导致过拟合的模型,最后我使用了投票制和岭回归。
为什么用这么多模型?
答案很简单:多样性。
我认为模型数量不会引发大的问题,原因如下:
首先,如果我们想要一个简单的模型,可以只从这些模型中选择1-2个,并且仍然可以在公共和私人排行榜上都获得不错的分数(排名前20)。
其次,这次比赛有17个标签,不同模型对标签的识别能力也不同。
另外,这个解决方案可以用来替换或简化人工标记工作。由于计算资源相对来说比人力成本要便宜,我们可以通过使用强大的模型来预测未标记的图像,修正被错误预测的图像,然后使用扩展后的数据集不断迭代,训练出更强大、更简单的模型。
你用了什么工具?
Python 3.6、PyTorch、PyCharm
硬件设置呢?
配置4个英伟达GTX TITAN XMaxwell GPU的服务器。
经验之谈
这次比赛你有哪些收获?
正如上面提到的,我发现使用柔和F2损失函数(soft F2-loss function)、增加去雾算法、应用两层岭回归对取得高分至关重要。
另外,由于会有噪音标签,我们必须对自己的交叉验证方法充满信心。
对刚刚开始进行数据科学研究的人来说,你有哪些建议?
从一些优秀的课程中学习,例如斯坦福CS229和CS231n。
从Kaggle比赛、kernel和starter script中学习。
参加kaggle比赛,在比赛中得到经验和收获。
每天坚持阅读论文,对于一些论文中的方法,可以着手实践下。


新人福利
_____________
关注 AI 研习社(okweiwu),回复 1 领取
【超过 1000G 神经网络 / AI / 大数据,教程,论文】
分分钟带你杀入Kaggle Top 1%
▼▼▼





