主题模型 | 挖掘商品在线评论的主题特征(NLP方法)
今年“双十一”延续了去年烧脑的风格,复杂的优惠规则既考验数学功底又考验阅读理解能力,但这仍然没能浇灭剁手党的热情,“集能量组战队”的玩家们依旧打得火热。

微博@茶茶系少女
你的微信上最近是否也经常收到求赞的消息?

据说过几天大家的状态会是这样子的:
抢到心仪的商品时的你

刷新物流信息时的你

收快递时的你

拆快递时的你

你是否也在网购时不小心买到过那么几样让人怀疑人生的商品?


言归正传,回到我们今天要讨论的话题。在网上购物时,为了避免踩雷,我们会在下单之前翻看商品的评论,商品评论的重要性不言而喻。如何从海量的在线评论中提取出我们需要的信息,验证商品是否货真价实——这是我们在买买买之前要考虑的问题,同时也是一个试验和应用NLP(自然语言处理)技术的好机会。
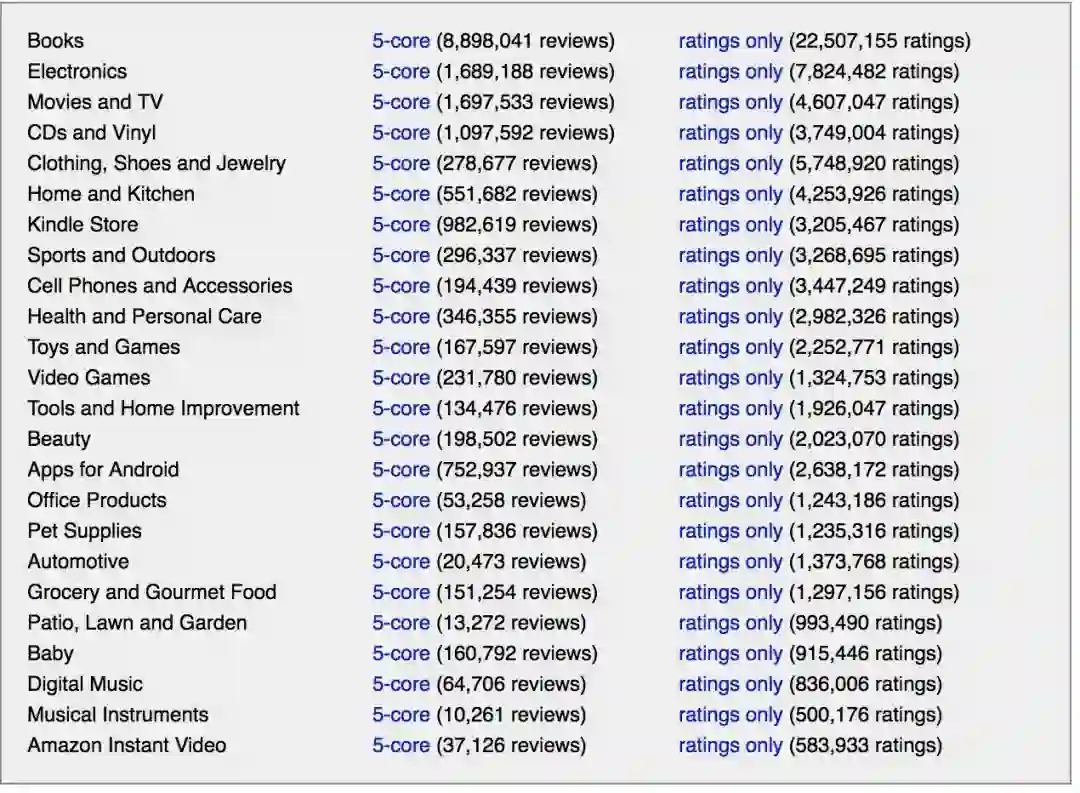
我们选择了使用亚马逊购物网站的“办公产品”类别的商品评论数据集来完成这个任务,类似的商品评论数据也可以在此下载:
http://jmcauley.ucsd.edu/data/amazon/
主题模型
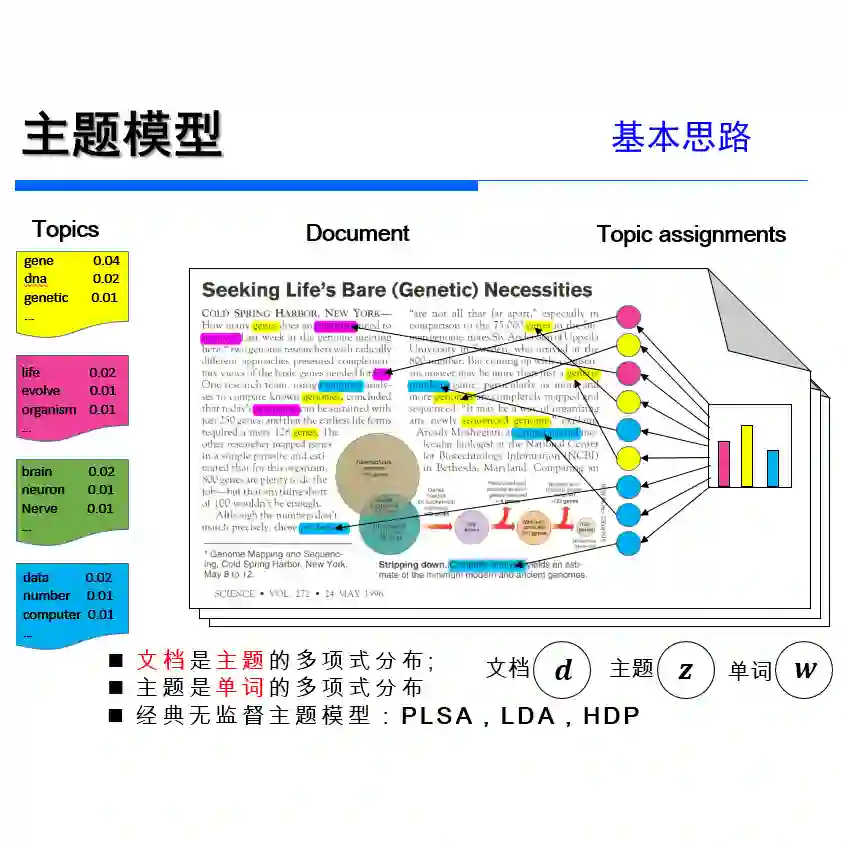
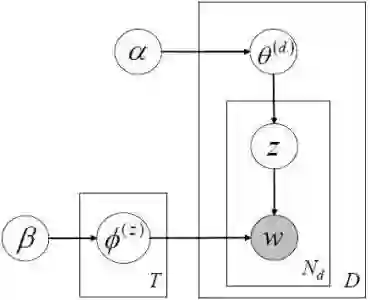
主题模型(Topic Model)是一种统计模型,应用于机器学习和自然语言处理领域时它可以在一系列文档中发现隐含的主题。主题模型分为PLSA模型和LDA模型,PLSA主要使用的是EM(期望最大化)算法,LDA采用的是Gibbs sampling方法和狄利克雷分布。主题模型是一种可以帮助我们挖掘文本隐含信息的利器。
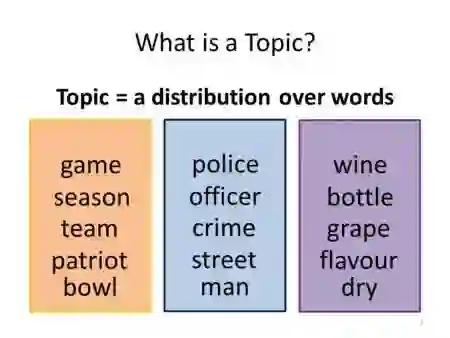
我们使用的数据是亚马逊“办公产品”类别中商品的评论,我们的任务是从成千上万条评论的文本中找到评论内容的主题,提取出重要的主题特征词。这样我们就可以得知评论中所谈论的主题是什么。
使用python实现
我们将使用jupyter notebook来执行我们的python代码,并进行数据的可视化。我们将使用LDA模型实现上述任务。
LDA(Latent Dirichlet Allocation)是一种文档主题生成模型。它是一种非监督机器学习技术,可以用来识别大规模文档集(document collection)或语料库(corpus)中潜藏的主题信息。它采用了词袋(bag of words)的方法,这种方法将每一篇文档视为一个词频向量,从而将文本信息转化为了易于建模的数字信息。
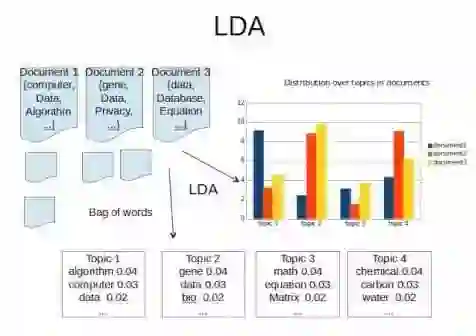
下面我们将介绍具体的python实现方法:
首先,我们加载本项目中所需要用到的python库

将我们用到的数据集文件存放在jupyter notebook的工作目录下面,然后我们便可以导入并使用该数据了。

使用df.head输出查看数据的前五行:
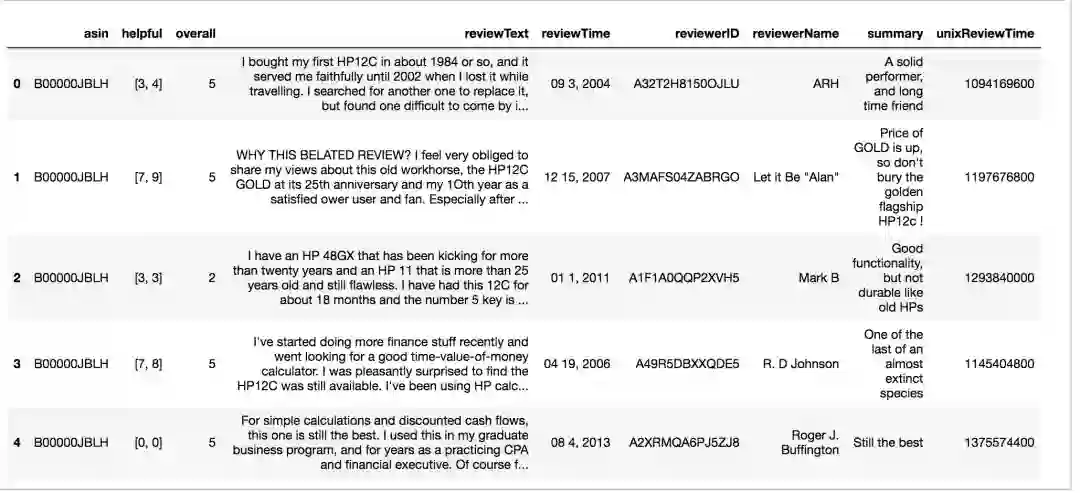

从输出的表中可以看到,数据包含53258条办公产品的评论,有9列的相关数据信息,分别为:
reviewerID – 评论者的ID
asin – 产品的ID
reviewerName – 评论者的姓名
helpful – 评论的智能排序
reviewText – 评论文本
overall – 产品评分
summary – 评论摘要
unixReviewTime – 评论日期(unix)
reviewTime – 评论日期
在我们的分析当中,我们将使用到“reviewText”即评论的文本这一列的数据。
数据预处理
数据预处理和清理是进行文本挖掘任务之前的重要步骤。
在这一部分,我们需要过滤掉标点符号、停用词并且将文本进行规范化的处理。为了检查我们数据处理的效果,我们在数据处理清洗步骤中使用函数绘制出词频较高的词汇。
构建函数并使用该函数显示我们原始数据中词频较高的词汇:
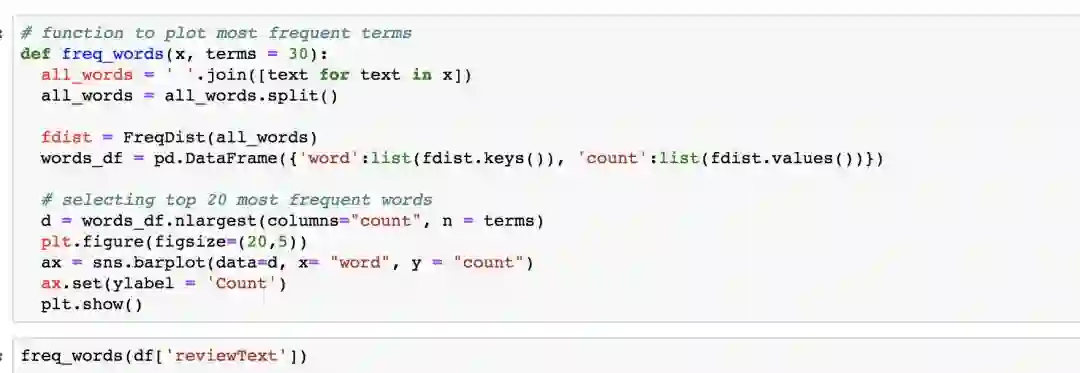
原始数据
可以看出,原始的评论数据中词频最高的为"the"、"to"、"a"等对我们的文本挖掘没有价值的词汇,我们会在数据预处理的过程中将它们过滤掉。
删除不必要的符号

删除停用词和字母个数小于2的词

再次绘制高频词汇来看一下经过我们处理过的文本

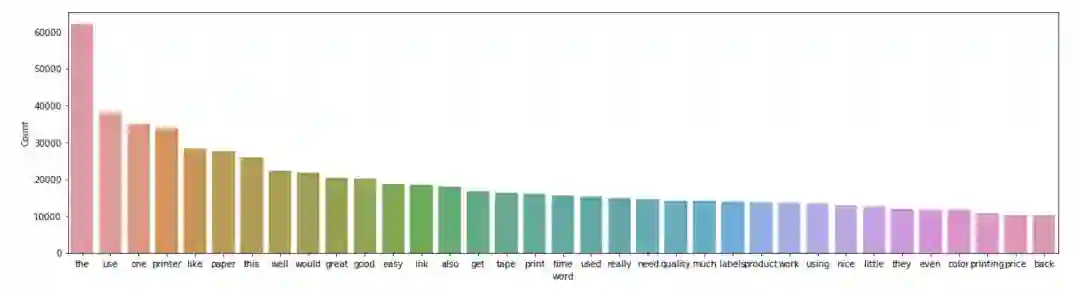
可以看到诸如printer、paper、price这样的与办公产品相关的词汇已经有所显现,这些词语是我们希望看到的,但是还存在着许多不相关的单词如the、this等,需要进一步过滤。
我们使用spacy库中的词形还原来进一步消除文本中的噪音。


对评论进行标记并且提取词汇主干



我们进行了词干提取,将形容词和名词过滤了出来,再次绘制高频词汇来查看处理的效果

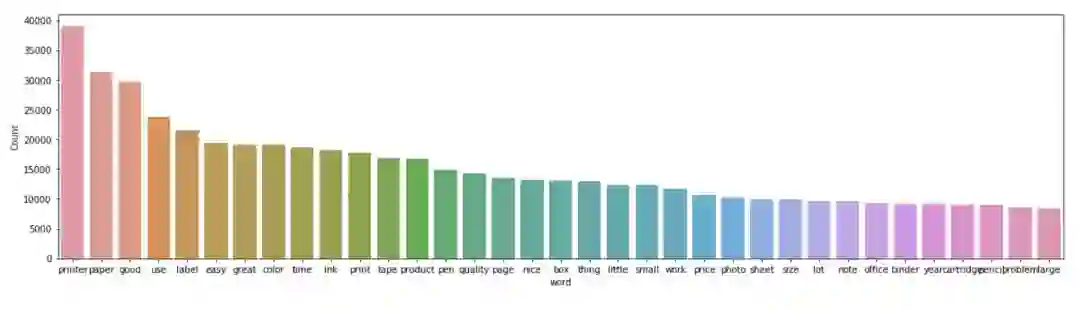
现在,大部分的单词像printer、paper、ink都与我们的主题是相关的,我们就可以继续进行下一步的操作——构建主题模型。
构建LDA模型
创建语料库的术语词典

然后,我们将使用上面准备的字典将评论列表(reviews_2)转换为文档术语矩阵。

在这里,我将主题参数指定为7,经过(很长)一段时间的代码运行时间就可以得到主题模型了。
输出这7个主题:


主题可视化
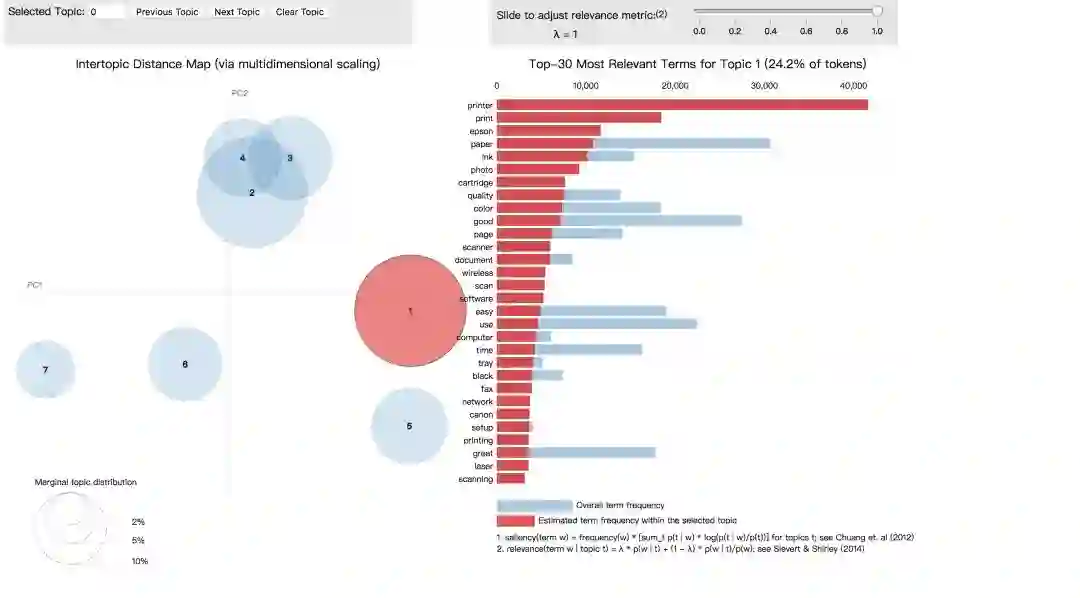
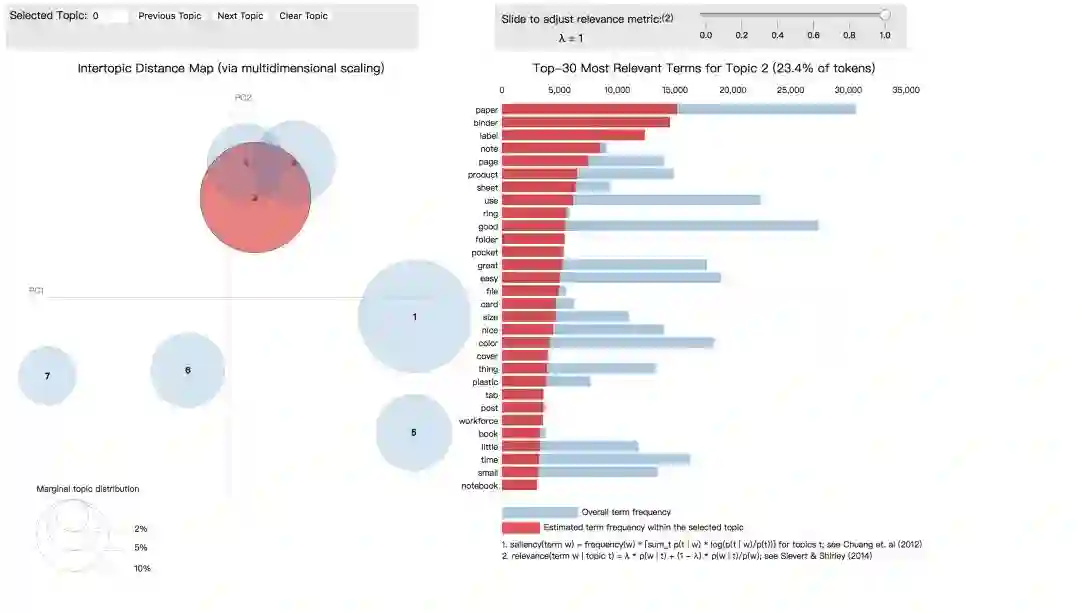
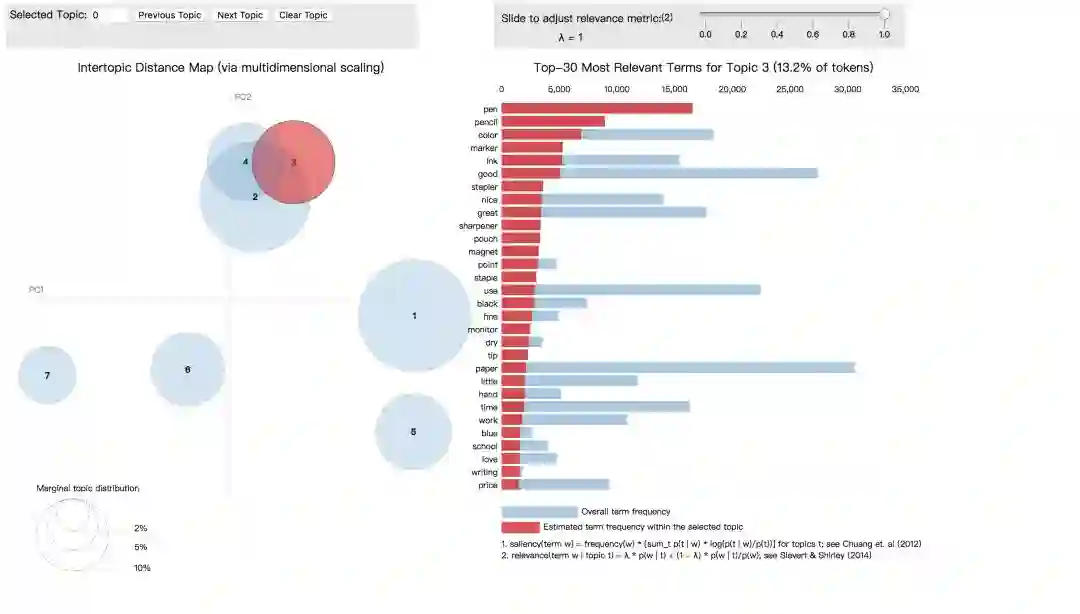
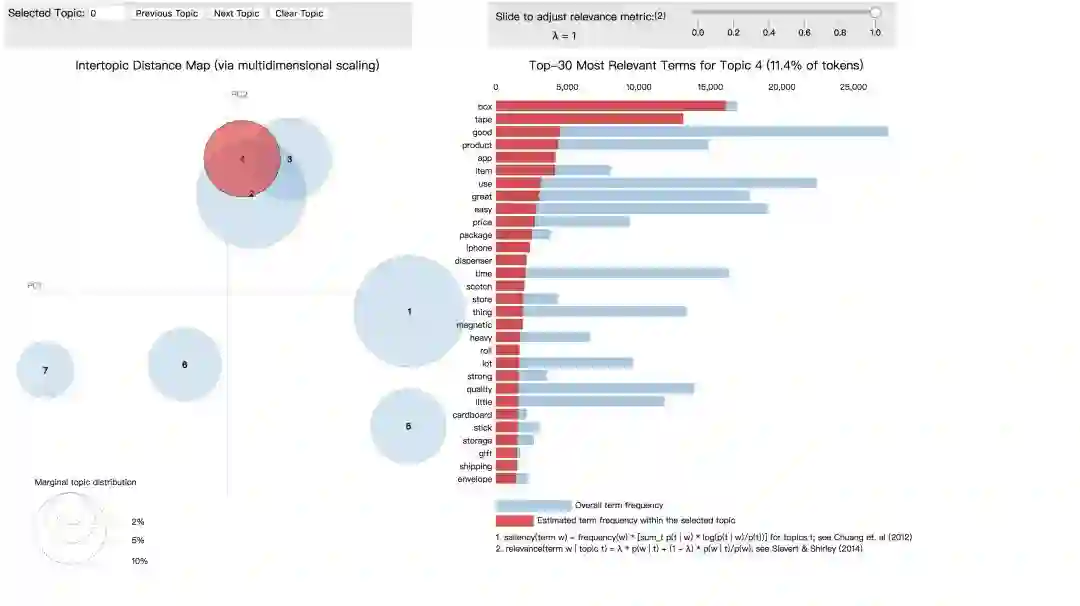
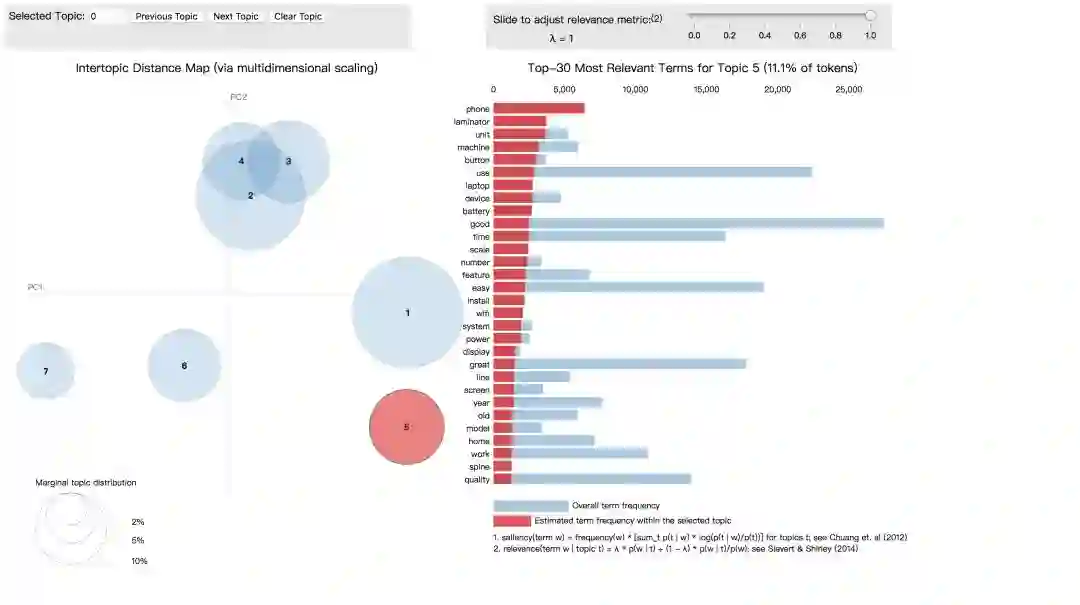
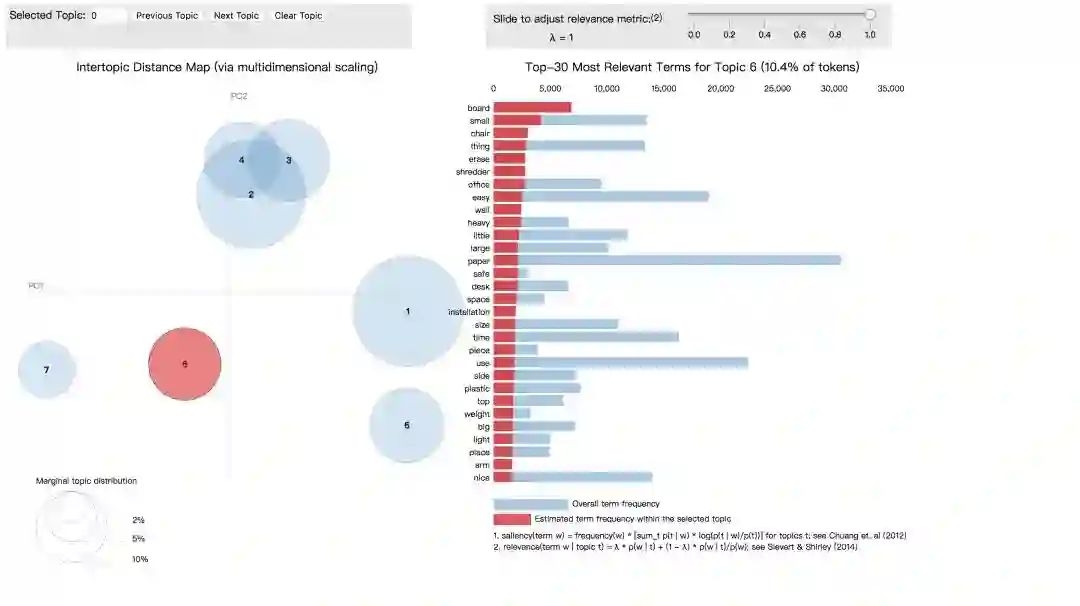
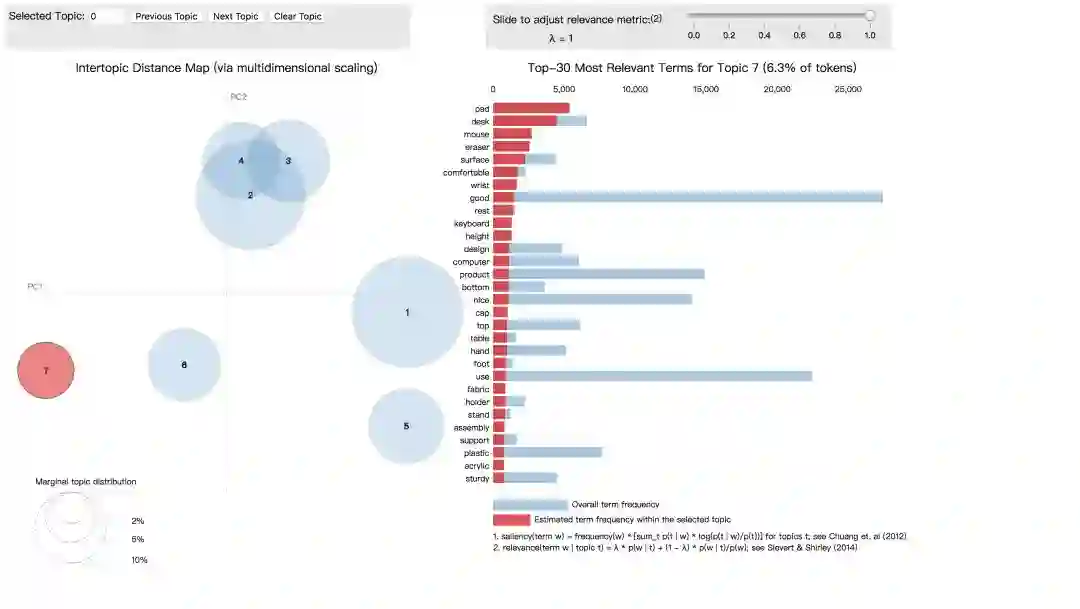
最后,我们利用pyLDAvis库进行主题可视化,以交互式的方式显示我们得到的商品评论主题及其相关的单词。

下面是可视化的输出结果

可以看到主题1里出现的高频词汇为“printer”“ink” “paper”等,这似乎是在谈论与打印有关的主题。
主题4有“price”“quality”“heavy”等词汇,可能是与商品质量有关的主题。
后期可以通过调整模型参数优化我们的结果。
接下来要做什么?
我们在本次项目中使用的数据集为亚马逊的英文数据集,我们还需要进一步解决对中文文本进行主题建模的任务。
此外,利用主题模型的方式可以使我们得到评论中所提到的重要主题,但是我们仍然无法判断这些评论是正面还是负面,我们在购物之前需要参考评论中的哪些意见。我们不仅需要得到评论的主题,还需要进行情感分析,这是我们下一步需要解决的问题。
网购就是这样,时常会失望,偶尔被戳心,每天游走在退换货的路上。

还是那句话,网购有风险,剁手需谨慎。大家双十一买买买的时候一定要理智消费,不要冲动啊 (划掉), 祝大家双十一剁手愉快!
参考资料:
[1]LDA文档主题生成模型.百度.2015-1-10
[2]Python中的主题建模初学者指南:https://www.analyticsvidhya.com/blog/2016/08/beginners-guide-to-topic-modeling-in-python/
[3]使用主题建模挖掘在线评论的NLP方法:
https://www.analyticsvidhya.com/blog/2018/10/mining-online-reviews-topic-modeling-lda/
下一步:我们应该抓取中文评论来实现主题模型和可视化!
沈浩老师
大数据挖掘与社会计算实验室主任
中国市场研究行业协会会长
欢迎关注沈浩老师的微信公共号




欢迎关注:灵动数艺
——数艺智训