贝叶斯分析助你成为优秀的调参侠:先验和似然对后验的影响

学习内容
举例:扔硬币实验
扔硬币实验的先验
扔硬币实验的似然函数与后验分布
先验与测量如何影响后验分布
使用 MCMC 算法从后验分布抽样

举例:扔硬币实验
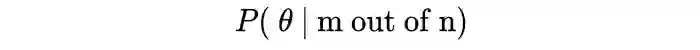
m out of n 表示实验数据
-
表示模型参数,待定
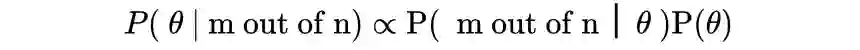

扔硬币实验的先验
上面式子中 表示先验(a prior)。
先验指一个人根据过去经验,脑海中对某事件发生的概率估计(或信仰 Belief)。
对于一枚硬币,估计大部分人会认为正面向上的概率为 50%, 即 或写成:
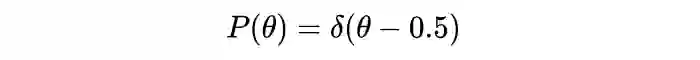
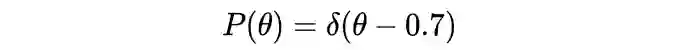
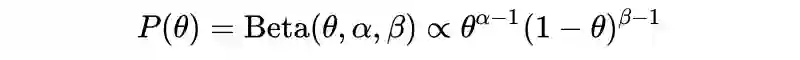
from scipy.stats import beta
import numpy as np
import matplotlib.pyplot as plt
# 需要安装 SciencePlots 库:
# pip install SciencePlots
plt.style.use(['science', 'ieee'])
def plot_beta_dist(axis, a=1, b=1):
'''plot the Beta distribution function
:a: parameter $\alpha$ in Beta distribution
:b: parameter $\beta$ in Beta distribution'''
x = np.linspace(0, 1, 10000)
y = beta.pdf(x, a, b)
axis.plot(x, y)
axis.set_ylabel(r"$P(\theta)$")
axis.set_xlabel(r"$\theta$")
axis.set_title(r"$\alpha=%.1f, \beta=%.1f$"%(a, b))
# Let's investigate how does Beta distribution change with alpha and beta
# parameters in 2 rows, 3 columns
params = [[(1, 1), (0.6, 0.6), (10, 10)],
[(0.3, 1.0), (10, 1), (1, 10)]]
fig, ax = plt.subplots(nrows=2, ncols=3, figsize=(9, 6))
for i in range(2):
for j in range(3):
plot_beta_dist(ax[i][j], *params[i][j])
plt.tight_layout()

扔硬币实验的似然与后验
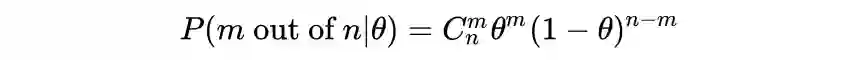
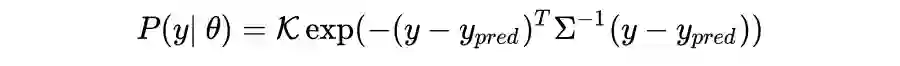
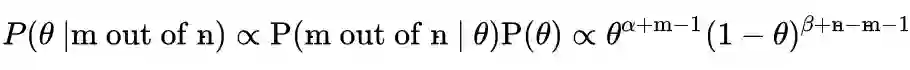

先验和测量如何影响后验分布
from ipywidgets import interact
import ipywidgets as widgets
print_to_pdf = False
def plot_posterior(m, n, a, b):
theta = np.linspace(0.0001, 1, 100, endpoint=False)
#poster = theta**(a + m - 1) * (1 - theta)**(b + n - m - 1)
ln_poster = (a +m - 1) * np.log(theta) + (b + n - m - 1) * np.log(1 - theta)
poster = np.exp(ln_poster)
prior = beta.pdf(theta, a, b)
plt.axvline(m/n, color='c', label='frequency')
plt.plot(theta, poster/poster.max(), label="posterior")
plt.plot(theta, prior/prior.max(), 'k--', label="prior")
plt.legend(loc='best', fontsize="small")
plt.xlabel(r"$\theta$")
if print_to_pdf:
plot_posterior(m=35, n=162, a=0.6, b=10)
else:
interact(plot_posterior,
m=(10, 100), n=(20,200),
a = (0, 10.0, 0.2), b = (0, 10.0, 0.2))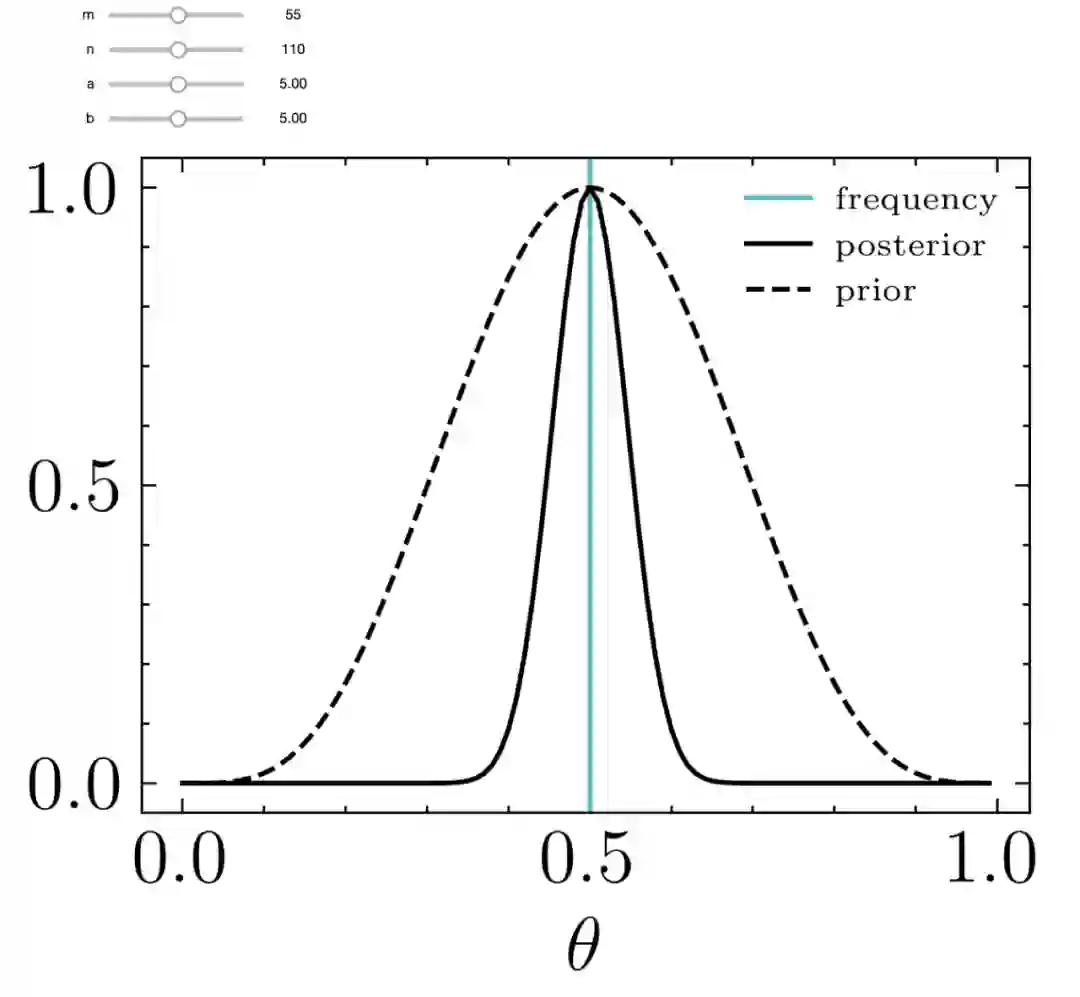
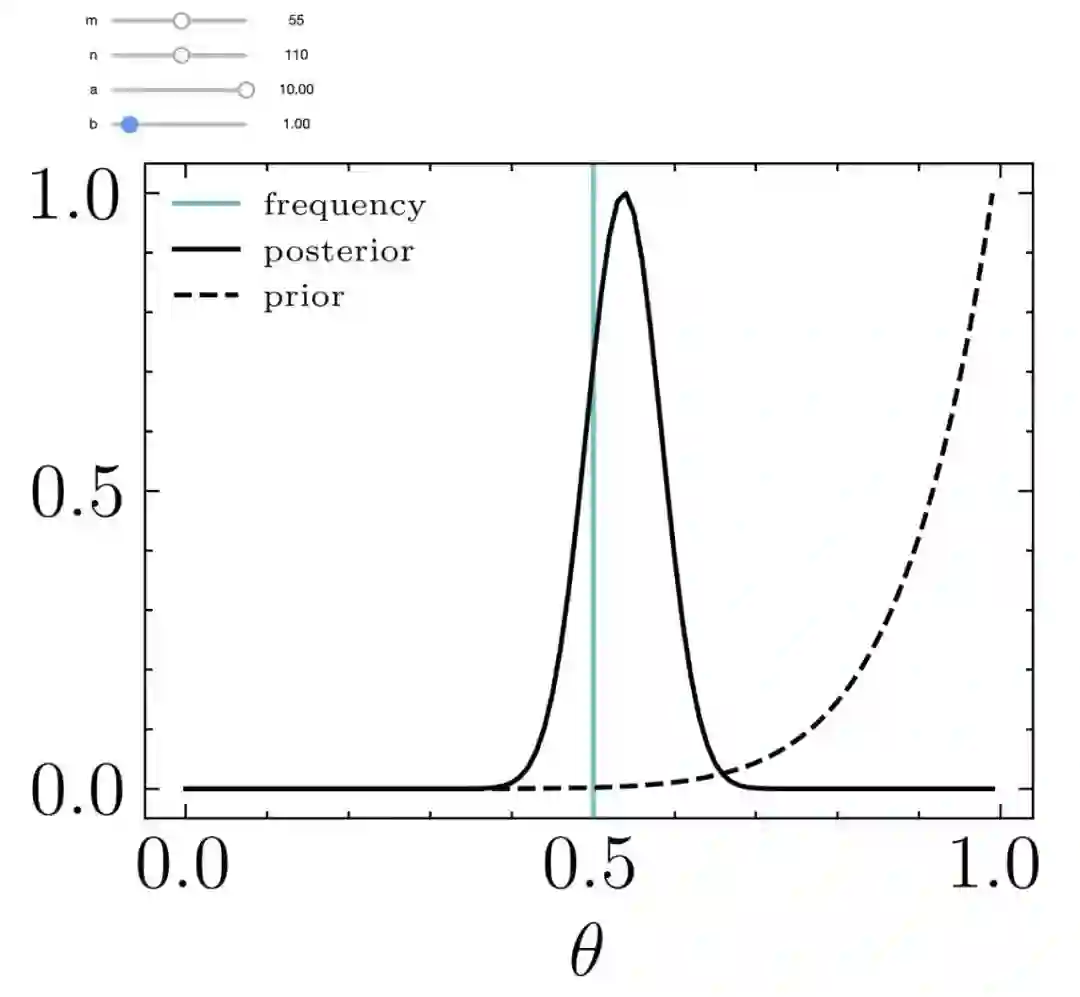
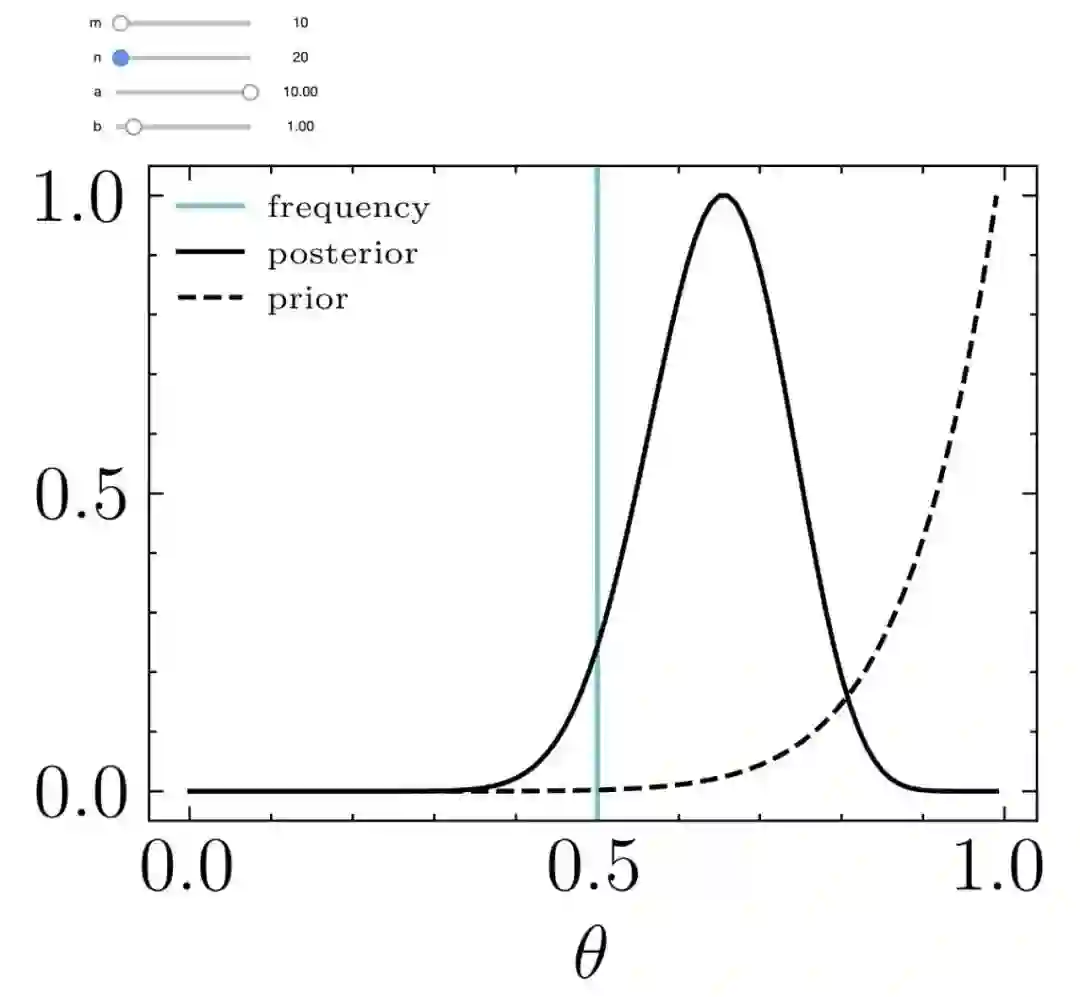
后验分布的中心一般在先验和频率之间
测量次数少时,先验对后验的影响比较大
测量次数很多时,先验的影响可忽略不计

使用 MCMC 算法从后验分布抽样
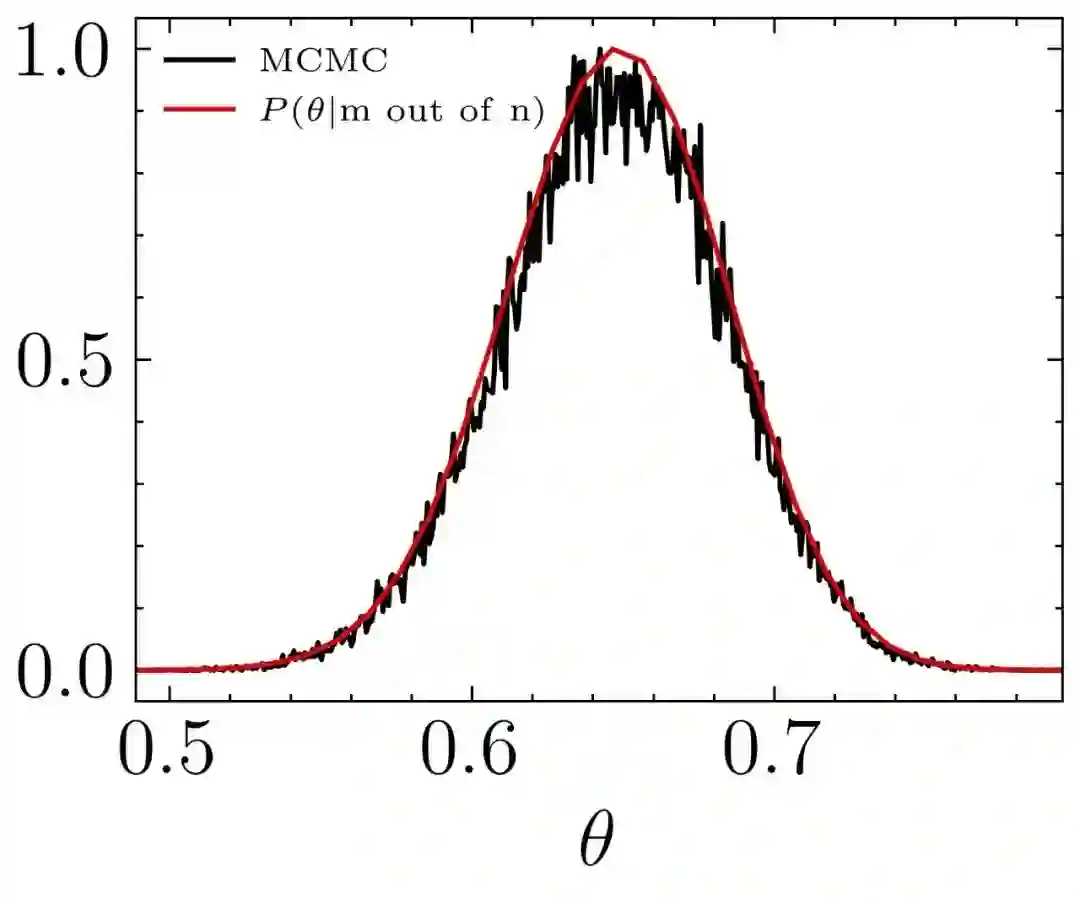
def draw_posterior(m, n, a, b, nsamples=1000000):
def poster(theta, m=m, n=n, a=a, b=b):
ln_poster = (a +m - 1) * np.log(theta) \
+ (b + n - m - 1) * np.log(1 - theta)
poster = np.exp(ln_poster)
return poster
samples = mcmc(poster, np.array([[0.0001, 0.9999]]),
n=nsamples, warmup=0.1, thin=10)
# compute the distribution of these samples using histogram
hist, edges = np.histogram(samples.flatten(), bins=100)
x = 0.5 * (edges[1:] + edges[:-1])
theta = np.linspace(0.0001, 0.9999, 100)
y = poster(theta)
plt.plot(x, hist/hist.max(), '-', label="MCMC")
plt.plot(theta, y/y.max(), '-', label = r"$P(\theta | \rm m\ out\ of\ n)$")
plt.legend(loc='best', fontsize='small')
plt.xlabel(r'$\theta$')
plt.xlim(x[0], x[-1])
draw_posterior(m=100, n=150, a=10, b=10, nsamples=2000000)

总结

参考文献
[1] https://github.com/keweiyao/BayesExample
[2] http://lgpang.gitee.io/mlcphysics/htmls/bayes_analysis.slides.html#/
更多阅读




#投 稿 通 道#
让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。




