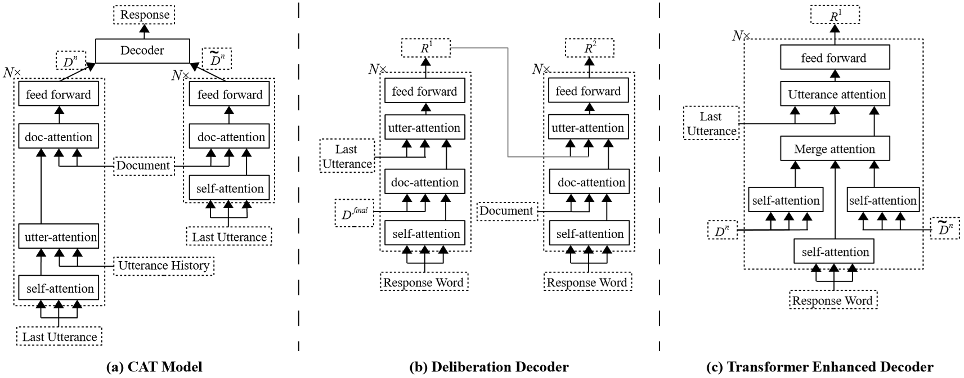
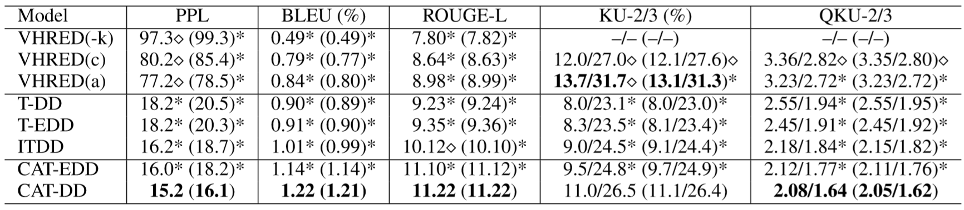
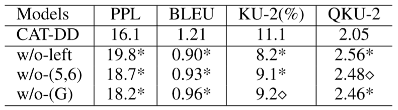
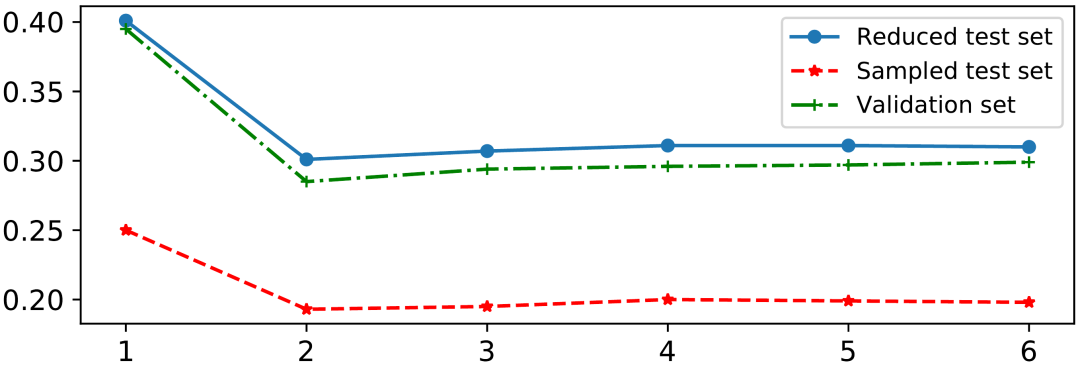
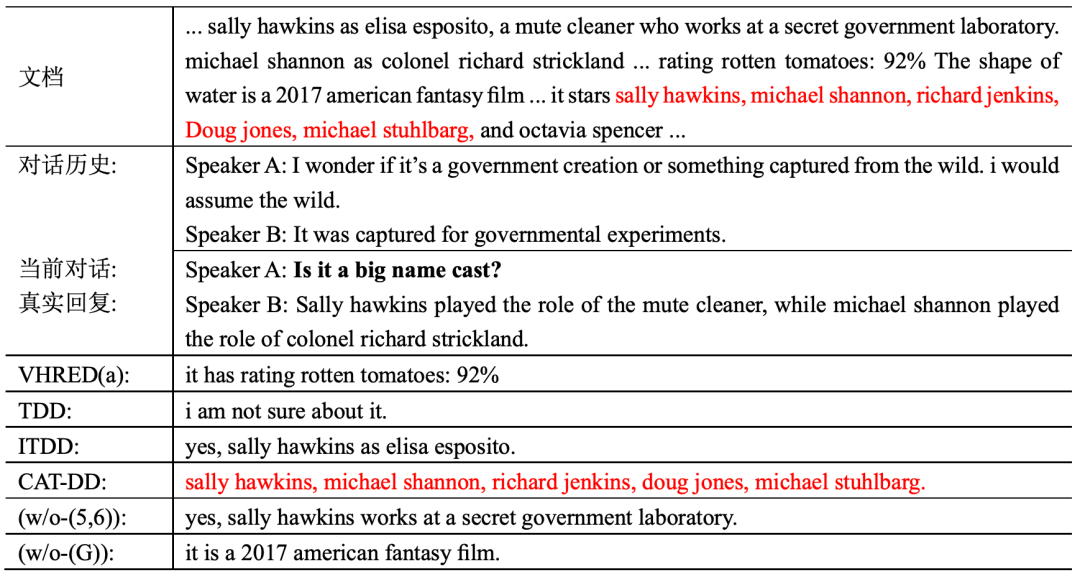
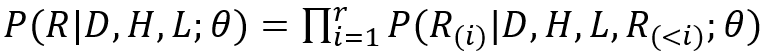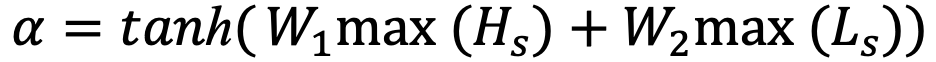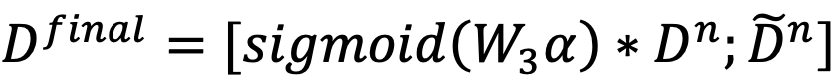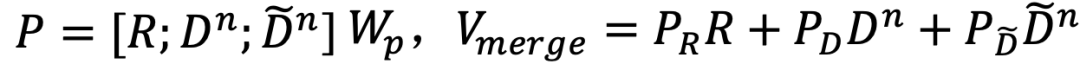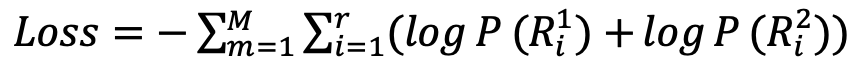如表2所示,我们从Sampled测试集中随机选取了一个例子,以较为直观地观察模型的生成效果。首先可以看到当前对话“Is it a big name cast?”与对话历史的相关度较低,只存在it之间的指代关系。我们对比了多个不同模型的生成,VHRED(a)和(w/o-(G))模型给出了无关回复;TDD给出了通用回复;ITDD给出了相对合理的回复但缺少足够的文档信息;(w/o-(5,6))的回复被对话历史影响了语义连贯性;只有CAT-DD的生成同时满足信息度和连贯性。但同时也存在明显的缺陷,CAT-DD只是正确的从文档中筛选出了信息,并没有将信息进行进一步的加工,生成符合人类对话的语句。这说明模型仍然有很大的改进空间,例如使用更能区分双层解码器输出的损失函数,或者设计单独的组件对筛选信息后的文本进行再次加工。表2. Sampled测试集中基于文档的对话示例
[1] Sankar C, Subramanian S, Pal C, et al. Do Neural Dialog Systems Use the Conversation History Effectively? An Empirical Study[C]//Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. 2019: 32-37. [2] Satoshi Akasaki, Nobuhiro Kaji: Conversation Initiation by Diverse News Contents Introduction. NAACL-HLT (1) 2019: 3988-3998 [3] Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[C]//Advances in neural information processing systems. 2017: 5998-6008. [4] Zhou K, Prabhumoye S, Black A W. A Dataset for Document Grounded Conversations[C]//Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. 2018: 708-713. [5]Li Z, Niu C, Meng F, et al. Incremental Transformer with Deliberation Decoder for Document Grounded Conversations[C]//Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. 2019: 12-21.本期责任编辑:张伟男本期编辑:钟蔚弘