赛尔原创 | 对话系统评价方法综述
本文已发表于《中国科学-信息科学》2017年08期,作者 张伟男,张扬子,刘挺
1 对话系统发展概述
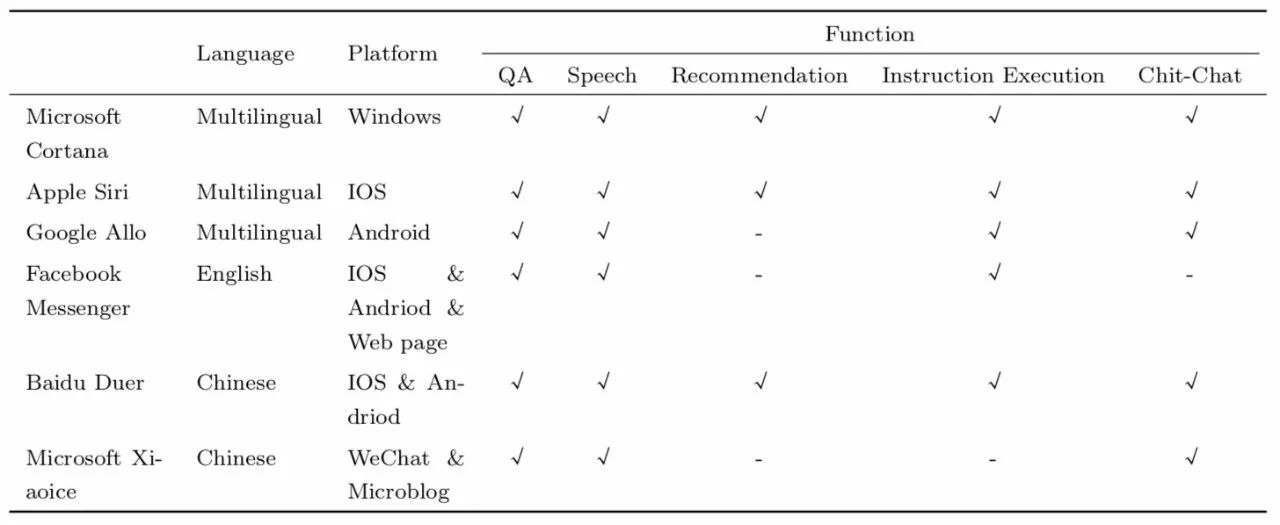
1950年,图灵在哲学刊物“思维”上发表“计算机器与智能”的文章[1],提出了后来被奉为经典的图灵测试——交谈能检验智能,即如果一台计算机能像人一样对话,它就能像人一样思考。图灵也由此获称“人工智能之父”的称号。从此之后,人类就一直在研究能让机器与人进行无障碍对话的方法: 1966 年的ELIZA是历史上出现的第一个人机对话系统 (简称对话系统) , 1964-1966年间由Joel Weizenbaum在Massachusetts Institute of Technology (MIT) 编码完成,主要用于在临床治疗中模仿心理医生对患者提供咨询服务。1988年出现的UC机器人用于帮助用户学习使用UNIX操作系统。1999年出现的YAP是用于查询英国电话黄页的机器人。 2004年的CSIEC,Sofia等都是以完成特定任务为目的的对话系统,CSIEC是一个外语学习伴侣,Sofia帮助教师进行数学教学, 与用户互动的同时连接 Mathematica软件实时为用户解决代数问题。早在1994年就出现了第一个以娱乐闲聊为目的的开放域对话系统 (也称聊天机器人) A.L.I.C.E, 科学家华莱士将这个聊天程序安装到网络服务器,然后观察网民与它的聊天行为。 近年来,对话系统由于其应用的广泛性受到了越来越多的关注,百度度秘,苹果Siri,微软小冰等对话系统的诞生更是将对人机对话的研究推向了前所未有的高度。表1给出了目前比较热门的6个对话系统样例,并根据支持的语言、搭载的平台以及具有的功能做了简单的比较。
表1 目前几种主流对话系统功能比较
随着神经网络和深度学习的快速发展,循环神经网络、深度强化学习等多种学习方法让对话系统在对话生成这个方向取得了很大的进展,但如何评价对话系统,一直都是对话系统相关研究的重点和难点,本文将从任务型对话系统和开放域对话系统这两个大方向上介绍目前对话系统评价的主流方法和思路。
2 任务型对话系统评价方法
随着任务型对话系统的诞生,与其对应的评价方法也逐渐成为了一个活跃的研究方向。 1997年,Walker 提出了一个将对话持续时间及其他许多特征融入线性方程的系统PARADISE用于推测用户的满意度[2],该系统主要采用的方法是用一个已标注用户满意度的对话数据集和一个客观评价的数据集,通过线性回归的方法对已标注的数据集求出一个可以用来表示用户满意度的权重指标,指标的决定因素是对话成功率和对话成本消耗(如对话时长、系统给出确认性质回复的次数等),再通过强化学习将这个指标变成一个损失函数作为网络的奖励(Reward),由于这个方法很好地考虑了对话系统的多个不同因素,这种方法后来也被用于对话策略学习[3]。由于实际操作中发现对话系统的成功率和对话的长度基本可以说是最重要的两个指标,后来的研究也往往将最大化成功率与最小化对话长度作为任务型对话系统评测的指标。
然而当系统真正与人进行交互的时候,任务完成的程度是很难界定的,不仅如此,生成模型理论上的有效性等一系列问题使得PARADISE的评价效果不尽如人意[4]。因此基于标注语料的数据驱动型对话评价模型成为了一个被广泛讨论的方向:2012年有研究者提出用协同过滤的方法来实现对用户反馈的表示[5];利用重塑反馈函数也可以起到加速对话策略学习的目的[6];Ultes与Minker等人的研究发现专家满意度对于对话系统的回复成功率有很大的影响[7]。所有的这些方法和尝试都表明,优质的训练数据对于对话系统的生成结果是至关重要的。 但是得到优质的标注数据是非常困难的, 耗费大量的专家资源来对数据进行系统完整的标注是非常不现实的,所以后续有研究者提出了用机器模拟人类标注数据的过程来标注数据,这样既可以减少人工消耗,也可以产生更多的可用数据。基于这个想法,有研究者提出了动态学习(Active Learning)的方法,为了减少标注误差而采用多种方式相结合的办法来对数据进行自动标注[8]。
Steve Young等人在2012年总结了任务型对话系统评价的基本情况[9]:数据驱动的自然语言处理(Natural Language Processing,NLP)任务有很多种评价方法,但由于多轮交互性的影响,对对话系统的评价难度要更大一些,尽管目前已经有很多针对不同指标的评价矩阵(即将客观指标用特征矩阵的方式进行表示,从而达到可运算的目的),但如何将他们很好的结合起来用于评价对话系统仍然是个难于解决的问题。事实上,对话系统评价的最终目标是测评用户的满意度,但总有许多因素造成我们无法将评价结果与用户的体验感受完全吻合,即使通过给出的人工制定的评价指标来对一个系统进行测试,也会造成不同程度的偏差,而且也很难将所有的特征罗列出来并加以对比达到全面的评价效果,因此现有的评价过程大都无法准确的满足用户的要求。 针对这些问题,文章提出了三个针对任务型对话系统评价的对策:1)通过构造某种特定形式的用户模拟系统进行评价;2)人工评价; 3)在动态部署的系统中进行评价[10]。
2.1 用户模拟
用户模拟是一种有效且简单的评价策略, 并且是最有可能覆盖最大对话空间的方法, 这是由于通过模拟不同情境下的对话,可以有效的在大范围内进行测试和评价[11,12,13]。然而这种方法的缺点也很明显,就是真实用户的反映与模拟器的反应之间潜在的差距,这个差距的影响大小某种程度上取决于用户模拟器的好坏。然而即使这个问题无法解决,用户模拟仍然是任务型对话系统评价中最常用的评价方法,曾被用于评价多种不同的基于部分可观察马尔可夫决策过程(Partially Observable Markov Decision Process,POMDP)的对话策略[14,15]。
实验对比了在不同噪声等级下,同一个用户模拟系统针对三个不同的对话管理器的评价结果(实验结果参看文献[9]的Figure.6), 其中HDC表示系统将人工选取出最像模拟器生成的结果作为输入,BUDS表示系统输入是非人工选择的,BUDS-HDC表示系统的输入是一个人工编码的对话策略产生的,BUDS-TRA表示系统输入是通过NAC这一策略进行训练之后得到的模型生成结果(NAC策略是一种强化学习策略,在文献[9]前文中提及,此处不做详解)。系统模拟的情境是一个自助旅游信息问询系统,用户可能会问到涉及一个虚拟小镇中的旅馆,餐馆,酒吧等多种娱乐信息的问题。评价方程定义为对话轮数的最大容忍值(即若在这个轮数内系统没有给出答案则认为此次对话失败,此处预先设定取值为20)与实际对话轮数的差值,图中的纵坐标Mean reward表示每一次对话之后评价方程的取值,横坐标Confusion rate被定义为对话管理器产生的语义结果与假设中给出的结果不相同的概率。图中可以清晰的看到不同输入会产生不同的结果特征,起初在低错误率的范围内每个对话系统的表现都很相近,而在高错误率的范围内,可以明显看出BUDS的系统鲁棒性要优于HDC,也就是说BUDS对于噪声的抵抗性要优于HDC。后续跟踪评价结果也发现,在多轮对话内容间产生如前后内容不一致,对话突然终止等冲突时,BUDS的处理能力也优于HDC。除此之外,将经过策略学习产生对话结果的BUDS-TRA与人工编码策略的BUDS-HDC相比较,可以发现BUDS-TRA后期的效果有较明显的提升,这表明了通过强化学习策略NAC进行的优化是有效的。
2.2 人工评价
第二个任务型对话系统评价方法是通过雇佣测试人员对对话系统生成的结果进行人工评价,这样做的好处是能够产生更多真实的评价数据,到目前来看,这种评价方法更多的出现在实验室等研究资源雄厚的环境中,测试人员在预定任务领域内对系统进行评测,通过一些预设的询问方式与系统进行对话,根据对话结果对系统的表现进行评分。通过POMDP进行对话策略学习的对话系统已经采用了人工评价的方法,并将结果应用于人工编码策略与MDP策略的结果提升任务中[15,16,17]。
然而这种评价方法最大的问题在于如何雇佣足够多的测评人员,很明显这需要大量的开销。后期出现的外包模式以及借助网络媒介延迟较小的特点在网络上进行实时评价等方法都可以尝试对这个问题进行解决,例如使用AMT(the Amazon Mechanical Turk)服务[18]: 给出预定义的任务以及基础的培训指令,雇佣评测员对指定的任务进行评测,评测员可以通过免费电话对对话系统进行评价,每次对话之后给出反馈信息。这个方法可以有效的产生大量对话系统与人的真实对话数据,从而产生大量的数据统计结果[19]。除开销巨大之外,这种评价方法还存在外包选择的评测人员是否真的能够代表所有用户的问题,事实上如果对实验集合没有很好的监控,人工评价的动机和目的就会成为最后评价结果的重要影响因素,也有事实证明人工评价并没有非常完整的表现出对话的效果特点[20]。
2.3 部署动态系统的评价
任务型对话系统评价的理想状态就是在真实用户群中检测用户的满意度,这种评价方法通常是在商业广告中植入对话系统或构建一个能够让公众主动去使用对话系统的服务设施。很明显这两种方法都是较难实现的。 Carnegie Melon University (CMU)的研究者曾提出过一个评价架构,称为对话系统挑战(Spoken Dialogue System Challenge): CMU首先开发了一个对宾夕法尼亚州匹兹堡的用户提供在线公交信息查询的对话系统,用户可以通过给这个对话系统打电话来查询公交信息(在此之前这项服务是在工作时间由人工完成的)。由于产生了非常真实的用户需求,通过提供这样一个全时间段自动化的查询服务CMU开发的对话系统成为了这项服务的一个标准,后期出现参与挑战的系统如果通过测试证明效果更好可以替换这个系统(例如在2010年的挑战中,就有学生给出了比原有系统鲁棒性更强的新系统并参与了挑战[21])。
3 开放域对话系统评价方法
目前对开放域环境下的聊天机器人评价的方法主流有两种思路,客观指标评价与模拟人工评分。本文对客观指标部分的介绍主要包括两方面: 一是以BLEU[22], METEOR[23]和ROUGE[24]为代表的词重叠评价矩阵;二是以Greedy Matching[25],Embedding Average[26],Vector Extrema[27]为代表的基于词向量的评价矩阵。模拟人工评分部分本文主要介绍了前沿的三种用神经网络模拟人工评分的方法: Google Brain的Anjuli Kanan和Google Deepmind的Oriol Vinyals等人2017年1月提出的一种类GAN结构的对抗评价模型;McGill大学Ryan等人提出的基于RNN的Automatic Dialogue Evaluation Model(ADEM)对话评价系统和基于ANN结构的对话评价系统。
3.1 基于客观指标的评价方法
3.1.1 基于词重叠率的评价矩阵
根据已有的NLP任务经验,当提到如何评价模型生成结果的质量时首先想到的就是根据生成的回复与标准答案之间的词重叠率来进行评价: BLEU和METEOR是在机器翻译任务中取得很好效果的两种评价方法; ROUGE也在文本的自动摘要任务中取得了不错的评价效果。在非对话系统领域内这些指标被普遍认为可以准确反映生成结果的部分特征,虽然还没有彻底的适应对话系统类型的任务,但也有了不少值得探讨的尝试。
下文将介绍几种不同的客观指标,若没有特殊说明,下文出现的公式中均用




BLEU BLEU是一种对模型输出和参考答案的n-gram进行比较并计算匹配片段个数的方法。这些匹配片段与它们在上下文(Context)中存在的位置无关,这里仅认为匹配片段数越多,模型输出的质量越好。BLEU首先会对语料库中所有语料进行n-gram的精度(Precision)计算(这里假设对于每一条文本,都有且只有一条候选回复):

公式中






METEOR METEOR矩阵会在候选答案与目标回复之间产生一个明确的分界线(这个分界线是基于一定优先级顺序确定的,优先级从高到低依次是: 特定的序列匹配, 同义词,词根和词缀,释义)。有了分界线之后,METEOR可以把参考答案与模型输出的精度(Precision)与召回率(Recall)的调和平均值作为结果进行评价。具体的作法是: 对于一个模型输出








ROUGE ROUGE是一系列用于自动生成文本摘要的评价矩阵,记为ROUGE-L,它是通过对候选句与目标句之间的最长相同子序列(Longest Common Subsequence, LCS)计算F值(F-measure)得到的,LCS是在两句话中都按相同次序出现的一组词序列,与n-gram不同的是,LCS不需要保持连续(即在LCS 中间可以出现其他的词)。公式中






、
3.1.2 基于词向量的评价矩阵
除了词重叠率外,另一种考量回复效果的思路是通过了解每一个词的意思来判断回复的相关性,词向量是实现这种评价方法的基础。依据语义分布,采用Word2Vec[28]等方法,给每一个词分配一个向量用于表示这个词,这种表示方法通过计算这个词在语料库中出现的频率来近似的表示这个词所表达的含义。所有的词向量矩阵通过向量连接就可以近似为句子级的句向量,通过这种方法可以分别得到候选回复句与目标回复句的句向量,再通过余弦距离进行比较,就可以得到二者的相似度。
Greedy Matching 贪婪匹配方法是基于词级别的一种矩阵匹配方法,在给出的两个句子





由于上面的计算公式是不对称的,所以需要在各个方向上都对
Embedding Average 向量均值法是通过句子中的词向量计算一个句子特征向量的方法,通过对句子中每一个词的向量求均值来计算句子的向量。这种方法在除对话系统之外的很多NLP领域内都应用过(例如计算文本相似度的任务),公式中

对比
Vector Extrema 另一种在句子级向量上计算相似度的方法是向量极值法。通过筛选词向量的每一维来选择整句话中极值最大的一维作为这个句子的向量表示:
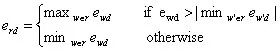
公式中


3.2 基于评分模拟的评价方法
3.2.1 GAN结构
生成式对抗网络(Generative Adversarial Networks, GAN)自2014年由Ian Goodfellow提出至今,不仅催生了很多理论论文,也带来了层出不穷的实际应用,已经成为人工智能学界一个热门的研究方向。Google Brain的Anjuli Kanan 和Google Deepmind的Oriol Vinyals 等人2017年1月提出了一种类GAN结构的对抗评价模型,并设计了一种类GAN的网络结构,用于直观评价生成器(Generator)产生的回复结果与人类回复的相似程度。
受到GAN在图像生成任务上的成果启发,Anjuli等人的工作也是采用了GAN的基本生成器-分类器(Generator-Discriminator)结构,通过训练得到的Generator用于生成回复,Discriminator用于区分人的回复与Generator生成的结果。
与传统GAN的基本结构不同,模型的 Generator是一个序列对序列(Sequence to Sequence,Seq2Seq)模型,包含一个完整的循环神经网络(Recurrent neural Network, RNN ) Encoder + Decoder 结构,而Discriminator虽然也是一个RNN,但采用的是Encoder加一个二元分类器的结构。
训练时将数据集中的信息对





对于Discriminator,训练时输入的信息为





实验的数据集



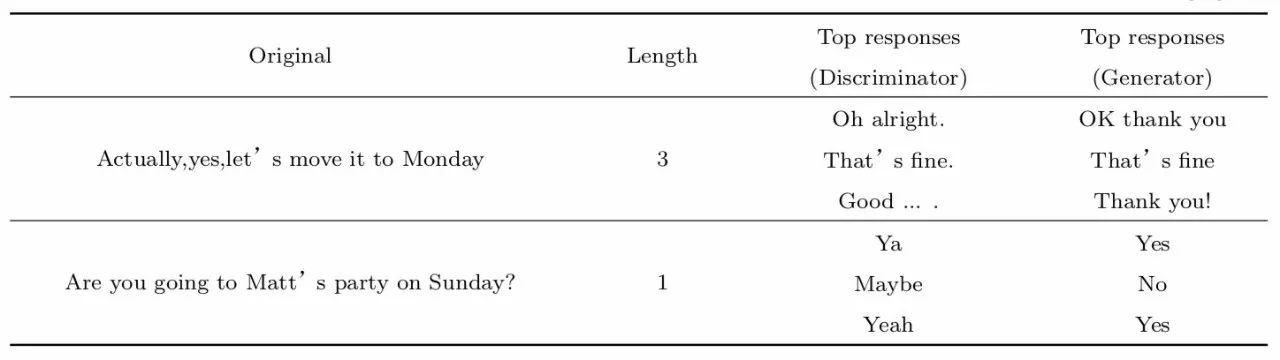
通过实验结果可以清晰的看出Discriminator的区分效果与回复的长短有很大的关系(参看文献[30]的 Figure.1),图像很清晰的展示了实验的效果,左图表示的是分数与回复长度的关系,横坐标表示回复的长度,纵坐标表示Discriminator给出的分数,随着回复长度的增加,分数在逐渐变高,即回复的长度越长,Discriminator越容易区分。右图也展示了召回率与精度的关系,随着训练次数的迭代,精度越来越高的同时召回率也在减小,即Generator产生的结果与原始数据越来越相近,意味着Discriminator就越来越难区分回复来自于Generator还是来自训练数据。表2也列举了一些回复结果的实例,根据例子可以发现长度较短的一些生成结果要更贴近真实的回复[30]。
表2 对于同一问题Discriminator与Generator的相同长度的回复的对比结果[30]
3.2.2 RNN结构
McGill大学的Ryan等人2016年6月的研究发现,传统的客观评价指标都具有一定的局限性,无法很完整的表示评分与人类评价的相关度,于是尝试使用RNN的方法进行自动评分模型的训练,并提出了一个对话系统自动评价模型(ADEM, Automatic Dialogue Evaluation Model)用于预测回复的人工评价结果,同时也将ADEM的评分结果与传统指标BLEU,ROUGE进行了对比,证明了自动评价系统的可行性。
ADEM是一个通过半监督性学习方法训练得到的多层RNN结构的评价模型,使用了多层编码器(Encoder)来将训练语料中文本转化为向量,训练阶段的输入为对话文本

公式中的






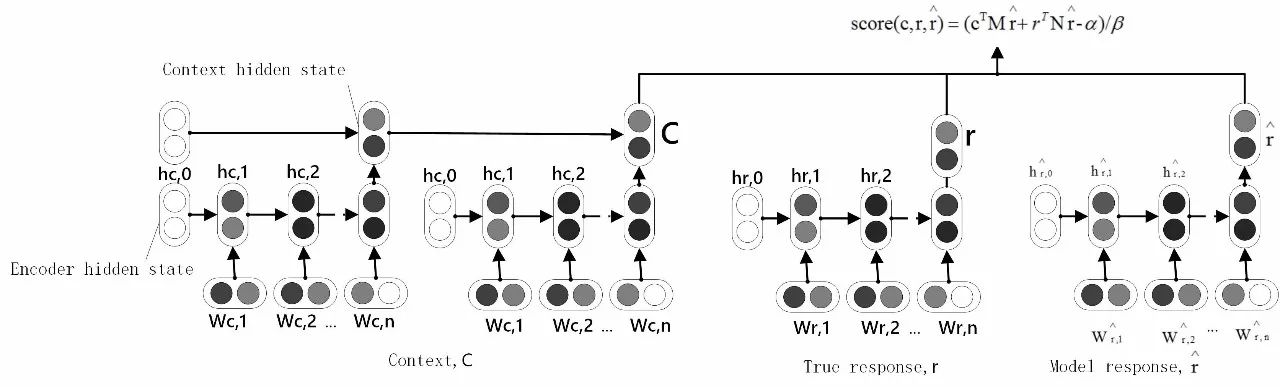
图1 ADEM的基本结构
图1出自文献[31],通过ADEM结构可以看出,ADEM采用的复合RNN Encoder结构包括两层,底层用于将文本中的词变为词向量,上层则是根据词向量产生整个上下文(Context)的向量表示。ADEM采用的这种RNN的结构与对话系统所使用的RNN结构最大的区别在于ADEM将参考回复作为一个变量参与训练,从而在训练的过程中,可以随时将模型生成的结果与参考回复做对比,大大降低了对比两种答案的难度。
由于人工标注数据费时费力,实验希望在训练过程能够用更少的标注数据达到更准确的预测效果,所以采用了预训练的方法学习Encoder的参数,实验采用的预训练方法是将原模型中的Encoder产生的结果当作输入送入一个独立的RNN,然后经过对这个RNN的训练产生特定条件下对特定Context的回复,并把这些数据当作原RNN的训练数据。 这样一来,同一句Context就可以产生许多句不同的回复,从而可以得到更多的训练数据。
实验使用了Twitter数据集,在开始实验之前,作者先通过Amazon Mechanical Turk的志愿者对数据集中给出的不同问题的不同回复进行评分,并且对人工评价的分数做了分析,根据人工评价得到的分数特点结合现有的Context与回复,再通过上文提到的预训练方法生成大量数据加入到实验数据集中。
表3 自动评价指标结果与人工判断结果的相关性[31]
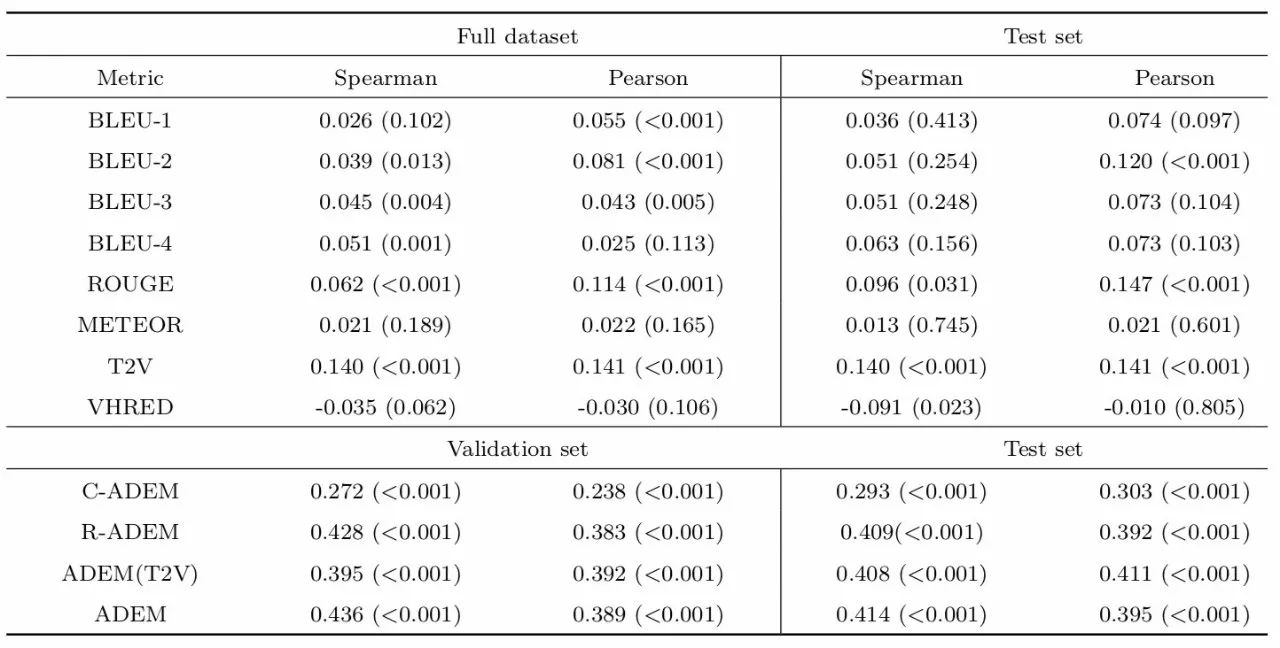
实验将ADEM的评价结果与METEOR,BLEU-N (N=1,2,3,4)的结果在Spearman与Pearson两个指标上进行比较,结果展示在表3中。表格中的T2V代表ADEM 仅使用Twitter数据集作为训练数据集,VHRED代表的是训练数据集为Twitter数据集加上预训练得到的数据;C – ADEM代表模型训练时生成回复结果仅与Context进行对比,R – ADEM代表结果仅与参考回复进行对比。同时也通过拟合图像的方式展示了实验的结果(参看文献[31]的Figure.3)。直观上看,与人工评分的结果分布相比,ADEM的分数要比简单的BLEU与ROUGE拟合程度更好一些,即认为ADEM的效果要好于BLEU和ROUGE[31]。
3.2.3 基于神经网络结构的其他评分模拟
训练数据的匮乏一直是开放域对话系统领域面临一个重大难题,基于数据处理的难度和数据标注消耗巨大的现状,Ryan的团队认为应该从大量未标记数据中寻找训练对话系统的方法,由此提出了用下文回复分类(NUC, Next Utterance Classification)作为从文本数据中训练对话系统的一个开端[32]。
实验为了比较人工评价的结果与人工神经网络(ANN, Artificial Neural Network)产生结果的差别,在训练阶段采用了Dual Encoder(DE)来训练数据,DE由带有长短期记忆模型(LSTM, Long Short-Term Memory)的RNN组成,用于将Context 







为了确定一个回复

其中
实验的数据集有三部分组成: 1.Ubuntu数据集: 从Ubuntu上的开放聊天平台IRC中提取出的对话数据[33];2.Twitter数据集: Twitter提供的大量Twitter 用户的对话数据[34];3.The SubTle数据集中电影部分[35]: 一些已标记对话结束位置的电影对白。人工评分参考的数据是145名在AMT上找到志愿者(志愿者包括不同性别,年龄,不同学历,不同工作等多种类型)进行评分的结果,具体志愿者的信息可以参看文献[32]中提供的表4,可以看出这些志愿者对不同数据集中的数据都进行了评分,用于最终的ANN模型生成结果的参考。
表4 145名AMT评测人员信息统计[32]
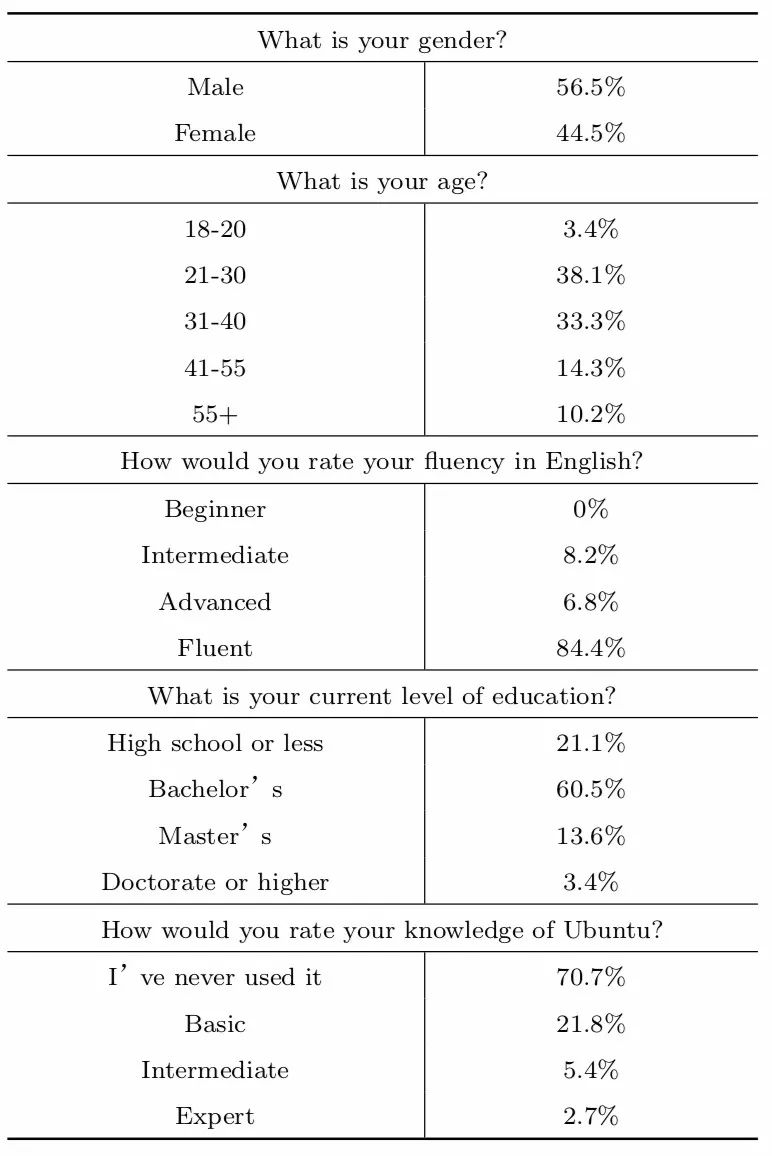
表5出自文献[32],是实验的最终结果。实验结果将召回率作为评价指标,R@k表示在排序生成的前k个结果中出现正确答案的比例,把实验提出的ANN结构与人工评分结果进行对比。不难发现在三个数据集上,ANN的表现都低于人类评分,在Twitter与Ubuntu数据集中,R@2与人工评价结果较为接近。
表5 每个数据集中的平均得分[32]
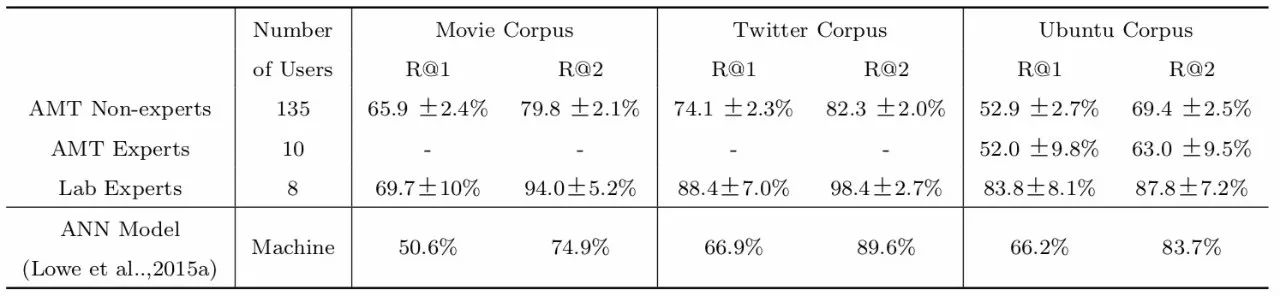
通过表5我们可以发现,人类在对回复进行分类的时候有明显的规律,随机情况只占极少数,对于不同领域不同知识层次的人,分类也有不同的结果,这是有规律可循的。此外,这项研究还发现,在对话自动生成的任务中,机器的实验结果与人类幼儿的回复结果非常相近,但与专家级别的回复结果差距较大,所以可以认为对话系统仍很大的进步空间。
4 未来趋势
基于对话系统现有的两种不同分类方法,研究者们有针对性地提出了各种不同的评价方法,对话系统评价这个领域也在近两年有了飞速的发展,各种各样的评价方法层出不穷,对于任务型对话系统可以利用任务完成程度当作硬性的评价指标进行评价,对于开放域的对话系统,通过对客观指标进行评分,可以很好的根据每个指标对对话系统模型进行修改和提高;通过模拟人工评分的结果,可以对评价这件事有一个整体的宏观的认知,这些都是对话系统评价领域内非常好的研究思路。
根据上文所述,对于任务型对话系统的评价仍然需要继续提高与人工评价结果的拟合程度;对于开放域对话系统,客观指标和模拟评分这两种方法都有各自的优缺点,如何利用二者不同的特点来提高评价的效率和准确率是未来研究的重点。如何能够减轻模型比较和选择的负担,增强评价系统的可扩展性,实现一种可迁移到不同数据集中进行评价任务的评价方法,是未来要重点关注的研究方向。
5 总结
本文通过介绍目前两种对话领域的主流评价思路,总结了目前在对话评价领域内的研究成果。对于任务型人机对话系统,主流评价思路仍然是以人工评价结果为目标不断进行探索。对于开放域的人机对话系统,目前的研究从切入点来区分主要有两个大方向: 客观指标与模拟评分,客观指标主要包括词重叠评价矩阵和基于词向量的评价矩阵。模拟人工评分主要是通过神经网络的训练方法,用机器来模拟人的打分过程,从而实现对对话系统的评价。
虽然每种评价方法都有自己的优势,如对于开放域对话系统的评价,客观指标可以更有针对性的发现对话系统的问题,根据不同的指标可以有的放矢的提高对话系统的性能; 模拟评分则采用了更加宏观的角度,抛开细枝末节直接对整体进行模拟,从而契合人工评价的结果,而且通过模拟还可以产生更多的标注语料,减少人工功耗。但是它们也都有自己的不足,如评价矩阵更多的是用于非对话系统的其他NLP任务中,还没有针对人机对话任务进行很好的整合迁移; 而直接抛开细节的评分模拟,很可能也忽略了重要的因素所以效果不是非常出众。基于这样的现状,对于对话系统评价的研究还有很大的空间可以供我们探索。
参考文献
1 Alan M Turing. Computing machinery and intelligence. Mind, 1950, 59(236):433-460.
2 Marilyn A. Walker, Diane J. Litman, Candace A, et al. PARADISE: A framework for evaluating spoken dialogue agents. In:Proceeding of EACL, European, 1997, 271-280.
3 Verena Rieser,Oliver Lemon. Learning and evaluation of dialogue strategies for new applications: Empirical methods for optimization from small data sets. Computational Linguistics, 2011,153-196.
4 L.B,Larsen.Issues in the evaluation of spoken dialogue systems using objective and subjective measures. In IEEE ASRU, 2003, 209-214.
5 Zhaojun Yang,G Levow, Helen Meng. Predicting user satisfaction in spoken dialog system evaluation with collaborative filtering. IEEE Journal of Selected Topics in Signal Processing,2012, 6(99):971–981.
6 Layla El Asri, Romain Laroche,Olivier Pietquin.Task completion transfer learning for reward inference.In:Proceeding of MLIS, 2014.
7 Stefan Ultes,Wolfgang Minker.Quality-adaptive spoken dialogue initiative selection and implications on reward modelling.In Proceeding of SigDial, 2015,374-383.
8 Pei-Hao Su,Milica Ga

9 Steve Young, Milica Ga
10 L.Hirschman,H.S.Thompson.Overview of evaluation in speech and natural language processing.IEICE transactions on information and systems, New York City, 1997, 409–414.
11 T. Watambe, M. Araki,S. Doshita. Evaluating Dialogue Strategies under Communication Errors Using Computer-to-Computer Simulation. IEICE Transactions on Information and Systems, 1998,vol. E81-D, no. 9, 1025–1033.
12 H. Ai, F. Weng. User simulation as testing for spoken dialog systems. In:Proceedings of SIGDIAL, Columbus, Ohio, 2008, 164 – 171.
13 J. Schatzmann.Statistical user and error modelling for spoken dialogue systems. Ph.D. dissertation,University of Cambridge,2008.
14 J. Williams. Applying POMDPs to Dialog Systems in the Troubleshooting Domain.In :Proceedings of the HLT/NAACL Workshop on Bridging the Gap: Academic and Industrial Research in Dialog Technology, Rochester, New York, 2007, 1–8.
15 B. Thomson, S. Young. Bayesian update of dialogue state: A POMDP framework for spoken dialogue systems. Computer Speech and Language, 2010, vol. 24, no. 4, pp. 562–588.
16 J. Henderson, O. Lemon,K. Georgila.Hybrid reinforcement supervised learning for dialogue policies from Communicator data.In: Proceedings of the IJCAI Workshop on Knowledge and Reasoning in Practical Dialog Systems, Edinburgh, United Kingdom, 2005,68–75.
17 M. Ga
18 F. Jur
19 I. McGraw, C. Lee, L. Hetherington, et al. Collecting Voices from the Cloud.In:Proceeding International Conference on Language Resources and Evaluation, Malta, 2010, 1576 – 1583.
20 M. Ga
21 A. Black, S. Burger, A. Conkie,et al. Spoken dialog challenge 2010: Comparison of live and control test results. in Proceedings of SIGDIAL, Portland, Oregon, 2011,2–7.
22 K. Papineni, S. Roukos, T. Ward,et al. BLEU: a method for automatic evaluation of machine translation. In Proceedings of the 40th annual meeting on Association for Computational Linguistics (ACL),2002a.
23 S. Banerjee, A. Lavie. METEOR: An automatic metric for mt evaluation with improved correlation with human judgments. In Proceedings of the ACL workshop on intrinsic and extrinsic evaluation measures for machine translation and/or summarization,2005.
24 C.-Y. Lin. Rouge: A package for automatic evaluation of summaries. In Text summarization branches out: Proceedings of the ACL-04 workshop, 2004.volume 8.
25 V. Rus, M. Lintean. A comparison of greedy and optimal assessment of natural language student input using word-to-word similarity metrics. In Proceedings of the Seventh Workshop on Building Educational Applications Using NLP, Stroudsburg, PA, USA. Association for Computational Linguistics,2012, pages 157–162,.
26 J. Wieting, M. Bansal, K. Gimpel, et al. Towards universal paraphrastic sentence embeddings. CoRR, abs/1511.08198,2015.
27 G. Forgues, J. Pineau, J.-M.Larcheveque, et al. 2014. Bootstrapping dialog systems with word embeddings.
28 T. Mikolov, I. Sutskever, K. Chen,et al. Distributed representations of words and phrases and their compositionality. In Advances in neural information processing systems,2013,3111–3119.
29 Laurent Charlin, Joelle Pineau. How NOT To Evaluate Your Dialogue System: An Empirical Study of Unsupervised Evaluation Metrics for Dialogue Response Generation. arXiv:1603.08023v2 [cs.CL] 3 Jan 2017.
30 Anjuli Kannan, Oriol Vinyals. Adversarial Evaluation of Dialogue Models.arXiv:1701.08198v1 [cs.CL] 27 Jan 2017.
31 Ryan Lowe, Michael Noseworthy, Iulian V. Serban, et al. TOWARDS AN AUTOMATIC TURING TEST:LEARNING TO EVALUATE DIALOGUE RESPONSES.ICLR 2017.
32 Lowe R, Serban I V, Noseworthy M, et al. On the Evaluation of Dialogue Systems with Next Utterance Classification[J]. 2016.
33 Lowe, N. Pow, I. Serban, J. Pineau. The ubuntu dialogue corpus: A large dataset for research in unstructured multi-turn dialogue systems. In:Proceedings of SIGDIAL.2015a.
34 Ritter, C. Cherry, B. Dolan. Unsupervised modeling of twitter conversations. In North American Chapter of the Association for Computational Linguistics (NAACL).2010.
35 R. E. Banchs. Movie-dic: A movie dialogue corpus for research and development. In Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics: Short Papers ,2012,Volume 2.
本期责任编辑: 赵森栋
本期编辑: 蔡碧波
“哈工大SCIR”公众号
主编:车万翔
副主编: 张伟男,丁效
责任编辑: 张伟男,丁效,赵森栋,刘一佳
编辑: 李家琦,赵得志,赵怀鹏,吴洋,刘元兴,蔡碧波
长按下图并点击 “识别图中二维码”,即可关注哈尔滨工业大学社会计算与信息检索研究中心微信公共号:”哈工大SCIR” 。




