赛尔原创 | 基于文本蕴含识别的答案验证技术研究
作者:哈工大SCIR硕士毕业生赵得志
本文分别提出了基于文本蕴含识别的答案验证方法,针对问答系统返回的词汇级、句子级、段落级等不同级别的答案,取得了实际可用的效果且对问答系统的性能有较大提升。
正文共:6065字 7图
预计阅读时间:16分钟
1. 前沿
近年来随着人工智能的火热,自动问答技术得到了广泛的关注。问答系统和传统搜素引擎的根本不同在于问答系统可以返回给用户精确的答案,而不是候选列表。为了确保答案的准确,问答系统在返回答案给用户前需要对返回结果进行验证,如何应用文本蕴含识别的方法进行答案验证即为本课题的主要研究内容。
因为缺乏大规模的中文蕴含语料,为了应用基于深度学习的文本蕴含识别方法,本课题首先采用百度翻译将英文SNLI语料翻译为中文,构建中文的蕴含语料。然后我们根据翻译的中文蕴含语料训练文本蕴含识别的模型。本课题分别训练了三种基于匹配编码的文本蕴含识别模型,应用于后面答案验证技术的研究。
问答系统的返回结果主要分为词汇级和句子级的答案,本课题针对词汇级和句子级的答案分别进行研究。针对词汇级的答案,答案可能来自于知识库、百度知道,我们采用知识库三元组拼接、知道问句和答案改写成陈述句做为蕴含前件,问题和答案改写为陈述句做为蕴含后件判断蕴含进行答案验证。针对句子级的答案,答案可能来自百度知道和百度百科,采用答案作为蕴含前件判断蕴含、由答案生成问题再判断问句间的蕴含关系进行答案验证。
此外,有些问答系统返回的答案既不是词汇也不是句子,而是更长的段落,同时进行段落级答案验证的研究。因为段落一般较长,难于建模,所以采用基于文本蕴含识别对齐和关键词的方法进行段落级的答案验证。
在评价方面,需要构建词汇级和句子级的答案测试集,基于哈尔滨工业大学社会计算与信息检索研究中心(哈工大SCIR)问答组的深度问答系统构建。同时使用哈工大SCIR问答组的在线问答系统构建评价段落级答案验证的测试集。根据测试集,评价文本蕴含识别应用于答案验证的效果以及对问答系统的提升效果。
2. 实验方法
2.1 词汇级答案验证方法
针对问答系统返回的词汇级的答案,答案可能来自于知识库(比如infobox)、问答社区(比如百度知道)。针对不同的答案来源,我们进行不同的处理,以便由答案和答案来源构成一个陈述句蕴含前件,由答案和问题构成一个陈述句蕴含后件来判断蕴含关系,进行答案验证。
具体来说,如果答案来自于知识库,则直接拼接知识库返回答案的三元组作为蕴含前件。比如对于“中国位于哪个时区?”这个问题,哈工大SCIR的深度问答系统将返回“东八区”这个答案,“东八区”这个答案即来自百度百科infobox知识库。针对这种答案来自于知识库的情况,我们拼接知识库的主体“中华人民共和国”,关系“时区”以及答案“东八区”为蕴含前件“中华人民共和国时区东八区”;同时基于规则改写问题为陈述句“中国位于东八区”做为蕴含后件,如表1所示。然后我们采用上一小节介绍的基于匹配编码的文本蕴含识别模型判断构造出的两个陈述句间的蕴含关系,进行答案验证:如果关系判断为蕴含,则认为问答系统返回的是正确答案;如果关系判断为不蕴含,则认为问答系统返回的是错误答案。
表1 词汇级答案来自知识库改写陈述句例子

如果答案来自于问答社区(在哈工大SCIR深度问答系统中即为百度知道),则利用答案基于规则改写对应的百度知道问题为陈述句以后作为蕴含前件。比如对于“周杰伦的妻子是谁?”这个问题,深度问答系统返回的是“中国人”,其来自于百度知道,对应的问题为“周杰伦是谁”。我们使用答案“中国人”和百度知道问句“周杰伦是谁”基于规则改写知道问句为陈述句“周杰伦是中国人”做为蕴含前件;同时使用答案“中国人”和问题“周杰伦的妻子是谁?”基于规则改写问题为陈述句“周杰伦的妻子是中国人”做为蕴含后件,然后即可采用文本蕴含识别模型判断构造出的两个陈述句间的蕴含关系,进行答案验证。如表 2所示:
表2 词汇级答案来自问答社区改写陈述句例子

2.2 句子级答案验证方法
针对问答系统返回的句子级的答案,因为答案是一个句子,无法像词汇级答案一样通过把答案和问题合并转化成一个陈述句以后再判断蕴含。因此采用的方法是直接拿系统返回的句子级答案做为蕴含前件,问题做为蕴含后件,使用上一章介绍的三种文本蕴含识别模型进行答案验证。
同时受文献启发,在其提到的文本蕴含识别技术应用于问答系统方面,其指出可以通过判断答案生成的问句q’和原始问题q之间的蕴含关系来辅助问答系统返回正确的答案。据此,我们提出了一种基于序列到序列模型的句子级答案验证方法:首先使用句子级答案做为蕴含前件,问题做为蕴含后件,采用三种文本蕴含识别模型进行蕴含关系的判断,得到答案和问题间的蕴含得分r1,然后使用序列到序列模型根据答案进行问句生成,再采用文本蕴含识别模型判断原始问题q和生成问句q’间的蕴含关系,得到蕴含得分r2,最后我们综合r1与r2进行答案验证的判断。
2.3 段落级答案验证方法
针对问答系统返回的段落级答案,因为段落级答案都比较长,结构复杂,建模困难,所以我们采用了基于文本蕴含对齐和关键词的答案验证方法:对于一个候选段落中的每个词w,在问句中找到和它最相似的词(词向量的余弦相似度最高),计算余弦相似度并用这个词w的关键词权重加权,相加每个词的结果并除以这个候选答案的总词数,得到的结果为这个候选段落的答案验证打分。对于每个段落级答案,希望把答案段落每个词与问句的蕴含程度相加,进而作为整个答案段落与问句的蕴含程度。蕴含程度的计算采用词向量之间的余弦相似度,但因为可能两个词的余弦相似度很高,但这个词并不重要,比如“的”。所以还需要对余弦相似度进行加权,权重就是候选段落中每个词成为关键词的可能性,作为这个词的重要程度。这样把结果相加就是整个候选段落与问句的蕴含程度。同时除以总词数对短文本有利,也符合直觉上较短的答案段落更可能是正确答案。(因为段落检索模块认为较短的段落却包含和较长的段落一样多的信息,直觉上较短段落的信息更与问题相关)
3. 实验与分析
3.1 词汇级答案验证方法实验结果与分析
我们在三种文本蕴含识别模型上进行了词汇级答案验证的实验,同时为了说明我们进行问句-陈述句转化的必要性,我们进行了不进行陈述句转化的对比实验,具体结果如表3所示。其中DecompAtt代表分解注意力模型,ESIM代表增强序列推断模型,DR-BiLSTM代表依赖阅读双向LSTM模型。
表3 词汇级答案验证实验结果
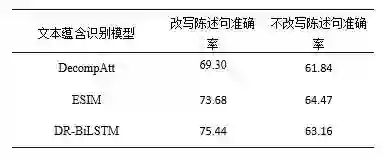
可见在进行改写陈述句的情况下,依赖阅读双向LSTM模型的词汇级答案验证准确率达到了75%以上,达到了实际可用的水平。同时对比不进行陈述句改写的对比实验发现,不进行陈述句改写相对于改写陈述句的方法准确率都有将近10%的明显下降,验证了我们进行陈述句改写操作的必要性。
比如针对“肯德基哪年创立”这个问题,答案为“1952年”,来自infobox,蕴含前件为三元组拼接“肯德基成立时间1952年”,如果改写陈述句,则蕴含后件为“肯德基1952年创立”,模型可以正确地判断出蕴含前件“肯德基成立时间1952年”和蕴含后件“肯德基1952年创立”的蕴含关系;然而如果不改写陈述句,则蕴含后件为“肯德基哪年创立”,因为其中缺少时间信息,所以判断为不蕴含,错误。
类似的,对于问题“哈尔滨在哪”,答案拼接后为“哈尔滨地理位置中国东北平原,黑龙江省中南部”,改写后“哈尔滨在中国东北平原,黑龙江省中南部”可以判断正确,不改写判断错误。同时还存在将不蕴含判断为蕴含的情况,比如对于问题“浙江的省会是哪里”,答案拼接后为“浙江下辖地区2副省级市、9地级市、35区、55县(市)”,因为答案中包含“副省级市”和问题的“省会”很相关(一般副省级市即为省会),所以会判断为蕴含;然而改写陈述句后,蕴含后件变为“浙江的省会是2副省级市、9地级市、35区、55县(市)”,直接说省会是“2副省级市、9地级市、35区、55县(市)”,与“下辖地区”矛盾,可以正确判断为不蕴含。
3.2 句子级答案验证方法实验结果及分析
我们亦采用词汇级答案验证使用的三种文本蕴含识别模型进行句子级答案验证的实验,同时为了验证我们采用的利用问句生成辅助句子级答案验证的有效性,我们进行了不融入生成问句和融入生成问句的对比实验,具体结果如表 4所示。其中DecompAtt代表分解注意力模型,ESIM代表增强序列推断模型,DR-BiLSTM代表依赖阅读双向LSTM模型,DR-BiLSTM+生成问句代表依赖阅读双向LSTM模型融入生成问句和原始问句间蕴含关系的结果。
表4 句子级答案验证实验结果

由表中结果可见,融入生成的问句和原始问句间的蕴含关系后,蕴含识别的准确率明显提高。比如对于“英伟达老总是谁?”这个问题,问答系统返回的答案是“老总,指对旧军人、军队高级领导人、总编辑、总工程师、总经理等的尊称。”,为介绍“老总”的一段话,本来不应该被判断为和问题蕴含,然而因为问题问的是“是谁”,正确答案也有可能是介绍“英伟达老总”的一段话,形式和返回的答案类似,所以模型把这个答案判断成了蕴含问题,判断错误;而问句生成模型根据“老总,指对旧军人、军队高级领导人、总编辑、总工程师、总经理等的尊称。”这个答案生成的问句是“老总是什么意思”,就和原始问句“英伟达老总是谁?”差距很大了,所以判断两者间不蕴含,综合考虑答案-问题、生成问句-问题间的蕴含关系后,模型可以正确的判断出非蕴含关系。
类似的,针对“姚明有多高”这个问题,系统返回的是“姚明,1980年生于上海市徐汇区,祖籍吴江震泽,前中国职业篮球运动员,司职中锋。”,亦被判断成了蕴含;而根据答案生成的问句是“姚明是谁”,也和原始问句差距很大,综合后可以正确的判断成不蕴含。
同时除了可以帮助模型判断出错误的答案,生成的问句亦可以帮助模型判断正确的答案,比如说对于“干眼症有什么治疗方法?”这个问题,答案是“干眼症的治疗需要一段时间的治疗,医生已给了相应的药物,坚持用一段时间,同时减少他用眼的时间,多做一些户外活动”,模型会错误的判断为不蕴含;而这个答案生成的问题是“干眼眼怎么治疗”,会被正确的识别成和原始问题蕴含,且因为和原始问题很相似,分数很高,最后综合后正确的判断出了答案和问题的蕴含关系。
3.3 段落级答案验证方法实验结果与分析
我们使用哈工大SCIR的在线问答系统进行段落级答案验证的评价,具体实验结果如表 5所示。其中“蕴含+答案选择”表示我们在系统中应用基于文本蕴含对齐和关键词的段落级答案验证以后问答系统返回答案的准确率,“仅答案选择”代表不使用段落级答案验证方法,仅在系统中进行答案选择的准确率。
表5 段落级答案验证实验结果
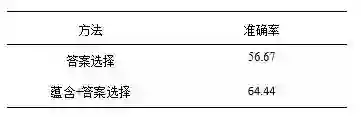
可见应用基于文本蕴含对齐的段落级答案验证技术后,显著提高了在线问答系统的性能。比如针对“中国奥运会的吉祥物是啥”这个问题,不加入段落级答案验证的问答系统返回的答案是“吉祥物又叫萌物,是人类原始文化的产物,是原始的人类在和大自然的斗争中形成的人类原始的文化。在这种和大自然的斗争中,人类首先以生存需要为中心,而在发展过程中自然就形成趋吉避邪的本能的观念。”,是介绍“吉祥物”概念的,和“中国”“奥运会”完全没有关系,是一个错误答案;不过在加入答案验证模块之后,系统返回的答案为“不可磨灭。福福娃含义:福娃代表了梦想以及娃介绍:福娃是北京 2008 年第 29 届奥运会吉祥物,其色彩与中国人民的渴望。”,答案中提到“福娃”是“北京奥运会”的吉祥物,为正确答案。据此,我们总结出段落级答案验证模块的优势之一,即实现了“软词重叠”:在上面的例子中,因为正确答案中的“吉祥物”和问题中的“吉祥物”,“北京”和问题中的“中国”,“奥运会”和问题中的“奥运会”对应,且这几个词都是有实际意义的词,关键词概率也很高,所以计算出的答案验证分数较高,帮助我们选出了正确答案;而错误答案中只有“吉祥物”和问题中的“吉祥物”对应,所以答案验证分数较低,没有被选择。而上面的这种特性恰恰就是一种问题和答案中的词重叠特性,考虑到在答案选择任务中考虑词重叠以后MAP值可以提高将近10%,我们的段落级答案验证方法亦实现了词向量的软词重叠,因此对于段落级答案的选择亦有较好的效果。表 6展示了“软词重叠”的另外例子:
表6 段落级答案验证例子

同时,我们亦发现段落级答案验证模块的另一优势:因为段落一般都较长,难以建模,所以对于较长的段落,原始的答案选择模块表现一般,而加入答案验证模块则可以明显修正。比如针对“计算机有几个组成部分,分别是什么?”这个问题,原始答案是“运算器 控制器 存储器 输入输出”,虽然回答了组成部分,但缺少“几个”的信息,而加入答案验证模块后,系统返回的答案为“计算机硬件是计算机系统中各种设备的总称。计算机硬件应包括5个基本部分,即运算器、控制器、存储器、输入设备、输出设备,上述各基本部件的功能各异。”,是一个即回答了“几个”又回答了“分别是什么”的正确答案。
4. 总结
针对问答系统返回的词汇级、句子级、段落级等不同级别的答案,本文分别提出了基于文本蕴含识别的答案验证方法,取得了实际可用的效果且对问答系统的性能有较大提升。
为了应用基于深度学习的文本蕴含识别技术,本文首次翻译了两个大规模英文文本蕴含语料SNLI和QNLI到中文,为之后进行中文方面的文本蕴含研究打下基础。
在词汇级答案验证方面,本文首次引入了基于深度学习的文本蕴含识别模型到答案验证任务中,亦是文本蕴含识别技术实际应用的一次尝试,且实验结果显示,在实际应用的深度问答系统返回的答案测试集中蕴含识别的准确率达到了实际可用水平。
在句子级答案验证方面,本文首先提出了一种基本的基于文本蕴含识别的句子级答案验证方法,然后在此基础上,本文受前人问句生成方面工作的启发,提出了一种在基本句子级答案验证模型上融合了生成问句和原始问句间蕴含关系的句子级答案验证方法,实验结果显示融合了生成问句的句子级答案验证方法显著提高了句子级答案的蕴含识别准确性。
在段落级答案验证方面,之前针对这方面的研究比较缺乏,本文考虑到段落较长难以建模且缺少段落级蕴含语料,提出了一种无监督的基于文本蕴含对齐和关键词的段落级答案验证方法。在实际应用的在线问答系统上显示我们提出的方法可以帮助系统选择更合理的段落做为答案,显著提高在线问答系统的性能。
在今后的工作中,我们首先可以尝试使用更有效的文本蕴含识别模型,以提高蕴含识别的准确率进而提高答案验证的效果;其次可以完善问句生成模型,采用更复杂的问句生成模块,生成更流畅相关的问句辅助答案验证的进行。
本期责任编辑:刘一佳
本期编辑:赖勇魁
“哈工大SCIR”公众号
主编:车万翔
副主编: 张伟男,丁效
责任编辑: 张伟男,丁效,刘一佳,崔一鸣
编辑: 李家琦,吴洋,刘元兴,蔡碧波,孙卓,赖勇魁
长按下图并点击 “识别图中二维码”,即可关注哈尔滨工业大学社会计算与信息检索研究中心微信公共号:”哈工大SCIR” 。






