赛尔原创 | 教聊天机器人进行多轮对话
作者:哈工大SCIR硕士生 宋皓宇
摘要:目前的神经网络对话生成模型在多轮对话过程中存在着容易产生万能回复、很快陷入死循环的问题;而已有的多轮对话相关研究工作存在着使用单轮回复生成模型进行多轮对话,没有考虑未来对话走向的问题。针对这些问题,我们引入了深度强化学习的DQN算法进行开放域的多轮对话策略学习,该策略使得每一轮的回复都更加有利于多轮对话的进行,从而减少万能回复的生成以及死循环的产生。
微博和Twitter等社交媒体上积累了大量的短文本,这些短文本可以近似的作为对话语料来训练基于深度神经网络的对话生成模型[1]。基于深度神经网络的对话生成模型能够有效的对输入产生回复,展现出巨大的研究潜力[2][3][4]。深度神经网络对话生成模型通常是数据驱动的,这类模型通过深度神经网络从大量的对话数据中直接学习得到从输入到回复的一种映射关系。这些模型中,得到广泛应用的是Seq2Seq(Sequenceto Sequence)模型。Seq2Seq模型基于编码器-解码器结构,应用于对话生成任务时,输入通过编码器编码为一个特征向量,再由解码器根据特征向量解码得到回复。这一模型基于极大似然估计(Maximum Likelihood Estimate,MLE),最大化与输入对应的回复的生成概率[5]。Shang L等人[6]在2015年将Seq2Seq模型应用在单轮的对话生成上,取得了很好的效果。

尽管相关工作强调了历史对话信息,但是仍然没有建模多轮对话过程:考虑对话历史得到的回复并不一定有利于对话过程的持续进行。此外,对话生成任务中以Seq2Seq模型为代表的端到端生成方式基于极大似然估计,每次得到的回复都是生成概率最大的句子。这就导致了那些经常出现但是没有实际意义的万能回复(safe response),比如“哈哈哈哈”,非常容易被选中[2][3][14]。一旦出现输入与回复相同的情况,那么模拟的多轮对话过程就会陷入死循环;有很高生成概率的万能回复则很可能把模拟的多轮对话带入这样的死循环中。结合对话历史得到的回复同样无法避免多轮对话过程中容易生成万能回复以及很快陷入死循环的情况的出现[7]。
开放域多轮对话的一个重要目标就是尽可能聊得更久。开放域多轮对话中每一轮回复的选择,不仅需要考虑是否能够有效回复当前输入,更需要考虑是否有利于对话过程的持续进行。更好的建模多轮对话过程,引导现有的Seq2Seq模型有效进行多轮多话,需要从整个对话过程的角度引入一种对话策略。我们通过引入深度强化学习算法DQN,以最大化未来奖励的方式学习一个对话策略,通过这个对话策略指导多轮对话过程中每一轮的回复选择。
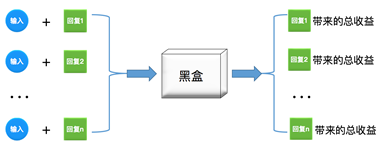
图2: DQN提供了黑盒的功能
DQN对当前对话状态下每一句回复进行评估,每次选择具有最大累计价值而不仅仅是生成概率最高的句子,利用强化学习最大化未来累计奖励的特点,建模多轮对话的过程,使得当前回复有利于对话过程的持续进行,并缓解多轮对话过程中容易出现的生成大量万能回复以及很快陷入死循环的问题。
实验数据方面,我们使用新浪微博对话语料,每一对对话数据分别来自微博的正文和这条微博下面的评论,这样一组博文-评论对就近似构成了一组对话对。该数据集总共有约110万组这样的对话对,语言质量较高,同时该语料也是Shang et al.(2015)所使用的数据集。数据表示方面,我们使用Word Embedding将每一个词语都转化为一个固定维度的向量,使用所有词语的向量共同表示原始的句子,词向量统一取300维。
我们参考Sutskeveret al.(2014)以及Vinyalset al.(2015)中的seq2seq模型,进行了有监督的对话生成学习,并且在训练过程中加入了Bahdanau et al.(2014)提出的注意力机制和Srivastava et al.(2014)提出的Dropout机制。实际的对话过程大多数时候都是有来有往的多轮交互,而不是简单的一问一答。能够对输入做出适当的回复并不代表能够有效的进行多轮对话。在得到了一个基础的回复生成模型后,就可通过模拟对话的方式来检验该模型能否有效进行多轮对话。
通常情况下,基于Seq2Seq模型的模拟对话只能进行有限的几轮:对话很容易陷入死循环或者生成大量没有价值的回复。分析其中的原因,不难发现这些现象与seq2seq模型基于MLE的估计方法以及没有建模上下文有着直接的关系。模型选择生成概率最大的句子,那么一些经常出现但是没有意义的回复就容易被选中;模型只看到当前输入而没有考虑到对话未来走向,就会很容易进入到死循环中。
表1: 基于seq2seq的模拟多轮对话
seq2seq模拟多轮对话1 |
seq2seq模拟多轮对话2 |
A:不足够自信上帝凭什么把机会给你 B:有道理! A:有道理! B:有道理! A:有道理! B:有道理! … |
A:成都加菲猫走红 B:真好! A:有点意思 B:哈哈哈哈哈哈哈哈 A:哈哈哈哈哈哈哈哈 B:哈哈哈哈哈哈哈哈 ... |
在多轮对话过程中应用强化学习方法需要向量化的特征表示,同时因为句子是变长和离散的,不利于进一步处理,所以我们借鉴自编码的思想,使用自编码器来获得关于句子的固定维度向量表示。理想情况下,自编码器学习得到的是一个恒等映射,即输入的句子与解码得到的句子完全相同。在数据比较简单的情况下,是有可能实现的。但是句子的数量空间特别巨大,想要得到一个完全的恒等映射几乎不可行。即使是使用深度学习模型也无法完全做到解码句子和输入句子完全一致,只能做到尽量的近似,但是这并不影响中间特征在强化学习模型中的使用。这是因为这些向量只需要按照同样的规则得到、处于同一个向量空间就可以满足需要。自编码器的学习过程对于中间特征向量引入了额外的信息,对于后续强化学习过程是有益的。
接下来使用强化学习模型建模多轮对话过程。有关强化学习模型的内容请参考引文[16]。
代理(Agent)的主要作用是根据环境更新的状态s选择动作a,这部分的主体是通过DQN算法训练得到的深度价值网络。深度价值网络对于给定的状态s和动作a,估计出一个价值Q ( s, a ),然后选择价值最大的那个动作。这里的动作是固定的:从束搜索得到的若干个(本文实验中是10个)候选句子中选择一个Q值最大的;状态的维度也是固定的(本文自编码器的中间特征是512维)。训练时,代理还需要根据环境提供的奖励值r更新深度价值网络。通过束搜索得到候选项的过程需要Seq2Seq模型的参与,但是无论是训练过程还是预测过程,基础的Seq2Seq模型都没有发生任何改变。
环境(Environment)的主要作用是接受代理选择的动作a(也就是句子),根据这个句子更新状态s,并根据奖励函数计算这个动作得到的奖励r。环境的主体部分是训练好的自编码器,将输入句子编码为特征向量从而表示状态s。
同时,强化学习是一个马尔科夫决策过程(MDP)。MDP是一个五元组,其中的变量有状态的集合,动作的集合,转移概率,奖励函数和衰减因子。衰减因子是一个数,无需特别的建模。首先定义状态集合和动作集合:
状态(State)在这里通过当前时刻的对话来表示。具体来说,当前时刻的对话分别为pi那么把pi送入训练好的自编码器中,得到固定维度的特征向量C,那么这个特征向量C就是当前时刻的状态表示。动作(Action)定义为选择一个句子。具体来说,束搜索得到若干个候选项,那么一个动作就是从这些候选项中选择出一个句子作为对输入的回复。
转移概率在对话过程中不需要定义,因为状态的转移依赖于模拟对话过程。
最后需要定义的就是奖励函数。奖励函数的作用是引导对话向轮数更多、信息更丰富、无聊回复更少的方向进行。从这个角度出发,奖励(Reward)定义为选择一个动作后得到的即时奖励,通过生成概率以及互信息的方式计算,此处不再赘述。
DQN(DeepQ-Network)是强化学习算法Q-Learning的深度学习近似版本。其核心思想是用一个深度神经网络来作为对价值的估计媒介,其参数更新通过对式(1)进行随机梯度下降来完成,其中表示状态,表示动作,表示奖励,Q表示通过深度价值网络对状态-动作对进行估值。
(1)
其中,价值的估计通过式(2)来完成:
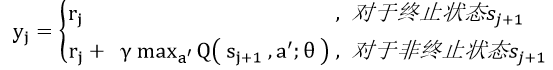
更多DQN的实现细节请参考引文[15]。我们方法的整体结构如下图所示:
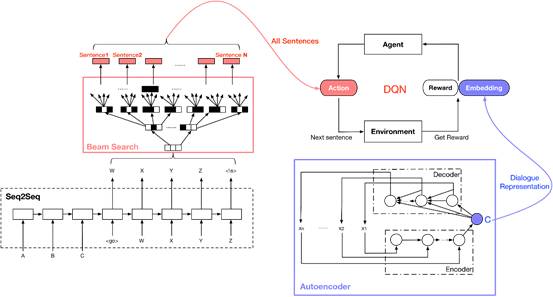
图3: 方法的整体结构
实验结果方面,下表给出一些直观的结果展示。可以看到,通过DQN引入多轮对话策略后,模拟对话的质量有了明显的提升。
表2: DQN和Baseline单轮对话对比
输入 |
Seq2Seq Baseline |
基于DQN的对话策略模型 |
日落巴塞罗那金色海岸,浪漫色彩。 |
真美! |
美得让人窒息。 |
彩虹和闪电交汇,非常难得的瞬间。 |
真美! |
抓拍的真好! |
两种广告,你选哪种? |
很有创意! |
二者皆可抛。 |
老段子,但我还是笑了。 |
笑死了 |
我笑了 |
人际交往的3个超经典的潜规则 |
很有道理 |
很不错的说 |
录音棚学歌中 |
忐忑唱忐忑 |
唱忐忑了 |
苹果明年或推iOS电视机 |
有时间看看 |
30寸苹果的iphone |
流言止于智者,聊天止于呵呵~ |
支持o(╯□╰)o |
呵呵,呵呵呵 |
二师兄也曾有过青葱岁月 |
真好! |
好可爱的猪猪~ |
表3: DQN和Baseline多轮对话对比
Seq2Seq Baseline |
基于DQN的对话策略模型 |
A: 元芳, (1) B: 元芳你怎么看? (2) A: 元芳,你怎么看? (3) B: 元芳,你怎么看? (4) A: 元芳,你怎么看? (5) B: 元芳,你怎么看? (6) A: 元芳,你怎么看? (7) B: 元芳,你怎么看? (8) … |
A: 元芳, (1) B: 元芳,你怎么了? (2) A: 元芳,你怎么看? (3) B: 元芳,我怎么看? (4) A: 元芳你怎么看? (5) B: 大人,此事必有蹊跷。 (6) A: 很有创意 (7) B: 好有创意 (8) … |
A: 发现,还是杨坤这期最好看~ (1) B: 哈哈哈哈哈哈哈哈 (2) A: 太可爱了 (3) B: 可爱死了 (4) A: 太可爱了(5) B: 可爱死了 (6) … |
A: 发现,还是杨坤这期最好看~ (1) B: 我觉得哈林唱的更好 (2) A: 哈哈,哈林唱得不错。 (3) B: 哈林唱的好 (4) A: 哈林唱得好! (5) … |
客观指标方面,引入DQN学习多轮对话策略后,模拟对话的平均对话轮数由2.51轮提高到了4.56轮。
参考文献:
[1] Serban I V, Lowe R, Charlin L, et al. A survey of available corpora for building data-driven dialogue systems[J]. arXiv preprint arXiv:1512.05742, 2015.
[2] Vinyals O, Le Q. A neural conversational model[J]. arXiv preprint arXiv:1506.05869, 2015.
[3] Luan Y, Ji Y, Ostendorf M. LSTM based Conversation Models[J]. arXiv preprint arXiv:1603.09457, 2016.
[4] Yao K, Peng B, Zweig G, et al. An Attentional Neural Conversation Model with Improved Specificity[J]. arXiv preprint arXiv:1606.01292, 2016.
[5] Sutskever I, Vinyals O, Le Q V. Sequence to sequence learning with neural networks[C]//Advances in neural information processing systems. 2014: 3104-3112.
[6] Shang L, Lu Z, Li H. Neural responding machine for short-text conversation[J]. Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics, 2015, pages 1577–1586.
[7] Li J, Monroe W, Ritter A, et al. Deep Reinforcement Learning for Dialogue Generation[J]. Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, pages 1192–1202, Austin, Texas, November 1-5, 2016.
[8] Williams J D, Raux A, Ramachandran D, et al. The Dialog State Tracking Challenge[C]//SIGDIAL Conference. 2013: 404-413.
[9] Henderson M, Thomson B, Williams J. The second dialog state tracking challenge[C]//15th Annual Meeting of the Special Interest Group on Discourse and Dialogue. 2014, 263.
[10] Su P H, Gasic M, Mrksic N, et al. On-line Active Reward Learning for Policy Optimisation in Spoken Dialogue Systems[C]// Meeting of the Association for Computational Linguistics. 2016:2431-2441.
[11] Lowe R, Pow N, Serban I, et al. The Ubuntu Dialogue Corpus: A Large Dataset for Research in Unstructured Multi-Turn Dialogue Systems[J]. Computer Science, 2015.
[12] Pascual B, Gurruchaga M, Ginebra M P, et al. A Neural Network Approach to Context-Sensitive Generation of Conversational Responses[J]. Transactions of the Royal Society of Tropical Medicine & Hygiene, 2015, 51(6):502-504.
[13] Serban I V, Sordoni A, Bengio Y, et al. Hierarchical Neural Network Generative Models for Movie Dialogues[J]. Computer Science, 2015.
[14] Li J, Galley M, Brockett C, et al. A Diversity-Promoting Objective Function for Neural Conversation Models[C]//Proceedings of NAACL-HLT. 2016: 110-119.
[15] Mnih V, Kavukcuoglu K, Silver D, et al. Playing Atari with Deep Reinforcement Learning[J]. Computer Science, 2013.
[16] Sutton R S, Barto A G. Reinforcement learning : an introduction[J]. IEEE Transactions on Neural Networks, 2005, 16(1):285-286.
[17] Hasselt H V, Guez A, Silver D. Deep Reinforcement Learning with Double Q-learning[J]. Computer Science, 2015.
[18] Schaul T, Quan J, Antonoglou I, et al. Prioritized Experience Replay[J]. Computer Science, 2015.
[19] Wang Z, Schaul T, Hessel M, et al. Dueling network architectures for deep reinforcement learning[J]. 2015:1995-2003.
[20] Guo H. Generating Text with Deep Reinforcement Learning[J]. arXiv preprint arXiv:1510.09202, 2015.
[21] Graves A. Sequence Transduction with Recurrent Neural Networks[J]. Computer Science, 2012, 58(3):235-242.
[22] Bahdanau D, Cho K, Bengio Y. Neural Machine Translation by Jointly Learning to Align and Translate[J]. Computer Science, 2014.
[23] Srivastava N, Hinton G, Krizhevsky A, et al. Dropout: A simple way to prevent neural networks from overfitting[J]. The Journal of Machine Learning Research, 2014, 15(1): 1929-1958.
本期责任编辑:赵森栋
本期编辑:赵怀鹏
“哈工大SCIR”公众号
主编:车万翔
副主编: 张伟男,丁效
责任编辑: 张伟男,丁效,郭江,赵森栋
编辑: 李家琦,赵得志,赵怀鹏,吴洋,刘元兴,蔡碧波
长按下图并点击 “识别图中二维码”,即可关注哈尔滨工业大学社会计算与信息检索研究中心微信公共号:”哈工大SCIR” 。



