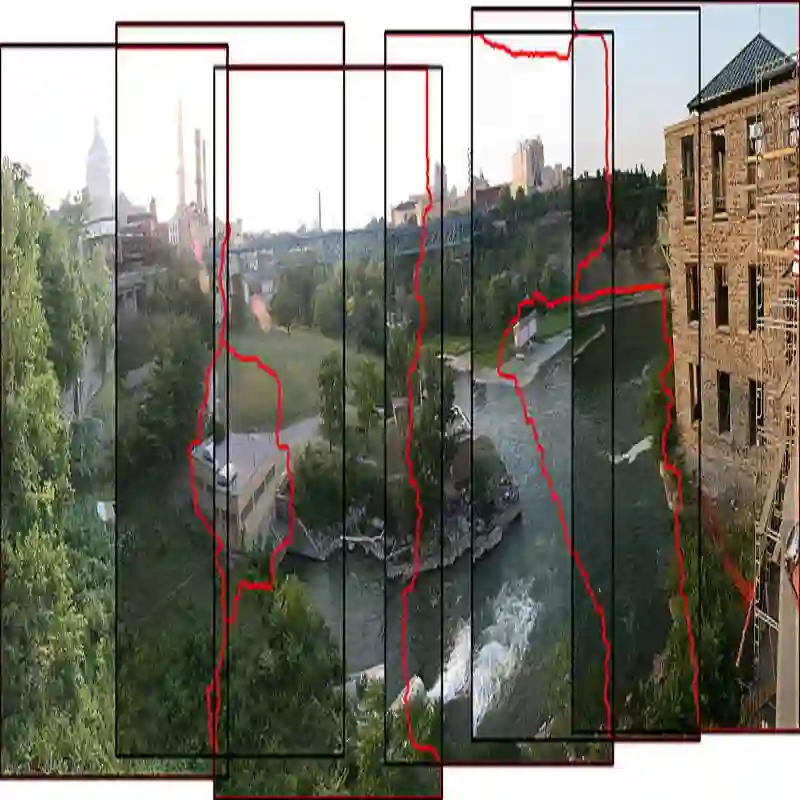
Results of image stitching can be perceptually divided into single-perspective and multiple-perspective. Compared to the multiple-perspective result, the single-perspective result excels in perspective consistency but suffers from projective distortion. In this paper, we propose two single-perspective warps for natural image stitching. The first one is a parametric warp, which is a combination of the as-projective-as-possible warp and the quasi-homography warp via dual-feature. The second one is a mesh-based warp, which is determined by optimizing a total energy function that simultaneously emphasizes different characteristics of the single-perspective warp, including alignment, naturalness, distortion and saliency. A comprehensive evaluation demonstrates that the proposed warp outperforms some state-of-the-art warps, including homography, APAP, AutoStitch, SPHP and GSP.
翻译:图像缝合的结果可以分化为视觉和多重视觉。 与多重视觉结果相比,单一视觉结果在视觉一致性方面优于视觉,但受到幻觉扭曲的影响。 在本文中,我们提出了自然图像缝合的两种单一视觉扭曲。第一个是参数扭曲,它是通过双重特征的“预测-可能-扭曲”和准摄影扭曲的组合。第二个是网状扭曲,这是通过优化一个同时强调单一视觉扭曲的不同特征,包括校准、自然性、扭曲和突出特征的总能量功能来决定的。 一项全面评价表明,拟议的扭曲超越了某些状态-艺术的扭曲,包括同源法、APAPAP、AutoStitch、SPHP和普惠制。