赛尔原创 | IJCAI 2019 融合角色信息的多样性对话生成
论文名称:Exploiting Persona Information for Diverse Generation of Conversational Responses
论文作者:宋皓宇,张伟男,崔一鸣,王栋,刘挺
原创作者:哈工大 SCIR 博士生 宋皓宇
论文链接:https://arxiv.org/abs/1905.12188
1. 背景介绍
构建能够通过图灵测试[1]的开放域(Open domain)对话系统一直是人工智能研究的重要目标。在实际的应用中,开放域对话系统通常用于与用户建立联系,并在较长的一段时间内陪伴用户[2]。因此,开放域对话在内容上越丰富越好;同时,对于某一句输入,通常也会有不止一句的可用回复。对话内容的多样性可以直观的定义为:对于同样的或者意思相近的输入,系统能够给出用词或者句式不重复、表达不同含义的回复。这种“一对多”(One-to-many)的性质是对话生成任务区别于其它机器学习任务的一个重要特点。下面我们通过一个例子来解释一下这种性质:

图1. 基于角色信息的一对多回复示例
如图1所示,对于输入“What do you do for a living ?”,根据已有的信息可以做出不同的回复。这些回复不仅与输入高度相关,而且覆盖了已有信息的不同方面,同时还具有了较好的多样性:当“What do you do for a living ?”这个输入再次出现时,系统可以选择一个没有使用过的句子作为本次的回复。
另一方面,这个例子也展示出对话系统如何维持自己的角色信息(Persona)。给一些预先定义的Persona文本,对话系统需要同时根据这些Persona文本以及常规的输入来产生回复[3]。维持一致的角色信息对于对话系统有着重要的意义。一个自我矛盾(Inconsistent)的对话系统难以获得用户的信任,更无法通过图灵测试。此外,Persona作为一种额外的信息,也有助于对话系统生成更加具体的回复,降低类似“I don’t know”这类无聊回复(Dull response)出现的可能性。
在这项工作中,我们提出了一种基于记忆机制的结构来建模Persona信息,并结合了条件变分自编码器中的隐变量来捕捉回复中的多样性。我们在ConvAI2 的Persona-Chat数据集上进行了实验,结果表明:
(1)我们的模型成功在回复中融合了Persona信息;
(2)我们的模型生成了更多样和更吸引人的回复。
2. 模型
该项任务可以形式化的定义为:给定输入 X 和角色信息文本的集合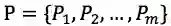
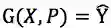
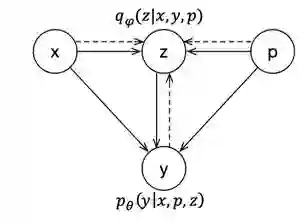
图2. 概率图模型
其中实线表示了以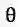
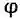
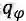
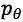
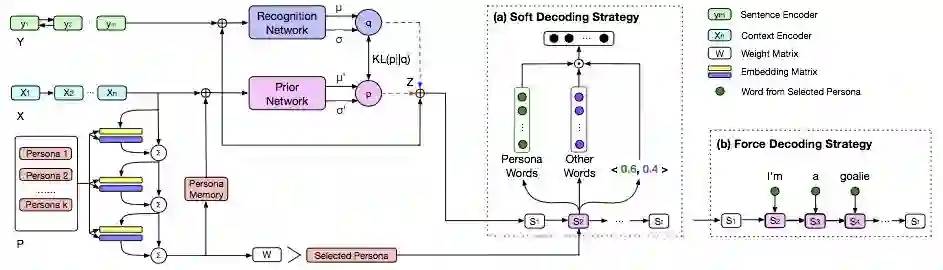
图3. 模型的网络结构
为了实现这一目标,我们构建了如图3所示的网络结构。在编码器一端,模型主要由变分自编码器和记忆网络两部分共同组成。变分自编码器通过先验网络(Prior network)和识别网络(Recognition network)编码 X 和 Y 来获得隐变量 Z 的表示。在训练过程中,隐变量 Z 来自识别网络,先验网络以学习到和识别网络更相似的表示为目标;预测过程中,隐变量Z来自经过训练的识别网络(此时没有标准答案 Y 的信息)。通过采样操作,我们可以获得某一分布下不同的 Z ,从而在解码器端生成不同的回复。
虽然变分自编码器建模了回复的多样性,但是仍然没有建模角色(Persona)信息。为此,我们引入了记忆网络[5]。每一条Persona文本都被视为独立的记忆存储在记忆网络中。经过编码的输入文本则作为对于记忆的查询,与记忆网络中的Persona信息进行计算。这里的记忆网络有两个作用:编码所有Persona信息以及选择与输入最相关的一项Persona信息文本。
为了更好的从编码信息中解码出Persona信息,我们在解码器一端使用了特殊的解码策略。在解码过程的每一个时刻 t ,词表都被划分为两个不相交的集合,分别包含了来自Persona文本的词语和其它所有词语。解码器分别在两个词表上预测词语的概率分布。同时,每一个时刻 t ,解码器还需要预测该时刻的词语是来自哪一个词表,这一任务与序列标注类似。最终的概率分布由词表概率乘上类别概率决定。
3. 实验
我们在ConvAI2的Persona-Chat数据集上进行了实验,并通过客观指标和人工打分的方式进行了评价。
单一的客观指标很难全面的评价生成回复的质量。在我们实验中,客观指标主要衡量了生成回复的多样性和对于Persona信息的覆盖率。实验结果如下:

图4. 客观指标结果
其中Dtinct-1和Dtinct-2是对多样性的度量,P.Cover是对Persona覆盖率的定量计算。带有*的数字则表示相对于所有基线模型具有统计显著性。 N 是同一句输入生成的回复数目。从客观指标中可以看出,我们的模型在生成回复的多样性以及Persona信息的覆盖率上具有明显的优势。
此外,对于生成回复的质量,我们进行了人工评价:
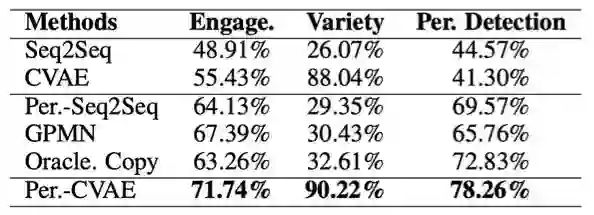
图5. 回复质量人工评价结果(N=5)

图6. 人工对比测试(N=5)
可以看出,在生成回复的质量上,我们的模型也具备很大的优势。
最后,我们给出一些生成回复的例子:

图7. 回复生成示例
4. 总结以及未来工作
这项工作着眼于利用对话系统的角色信息来产生多样化的回复,提出了一种基于角色信息的记忆结构。实验在ConvAI2 Persona-Chat数据集上进行。实验结果表明,我们的模型在多样性和角色信息覆盖方面取得了很好的效果。在将来的工作中,我们将探索如何在开放域对话过程中更好的建模用户的角色信息。
参考文献
[1]. [Turing, 1950] A. M. Turing. Computing machinery and intelligence. Mind, 59(236):433–460, 1950.
[2]. [Shum et al., 2018] Heung-Yeung Shum, Xiao-dong He, and Di Li. From eliza to xiaoice: challenges and opportunities with social chatbots. Frontiers of Information Technology & Electronic Engineering, 19(1):10–26, 2018.
[3]. [Zhang et al., 2018] Saizheng Zhang, Emily Dinan, Jack Urbanek, Arthur Szlam, Douwe Kiela, and Jason Weston. Personalizing dialogue agents: I have a dog, do you have pets too? In Proceedings of the 56th ACL, pages 2204– 2213, 2018.
[4]. [Kingma and Welling, 2013] Diederik P Kingma and Max Welling. Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114, 2013.
[5]. [Sukhbaatar et al., 2015] Sainbayar Sukhbaatar, Jason Weston, Rob Fergus, et al. End-to-end memory networks. In NIPS, pages 2440–2448, 2015.
本期责任编辑:张伟男
本期编辑:吴 洋
“哈工大SCIR”公众号
主编:车万翔
副主编: 张伟男,丁效
责任编辑: 张伟男,丁效,刘一佳,崔一鸣
编辑: 李家琦,吴洋,刘元兴,蔡碧波,孙卓,赖勇魁
长按下图并点击 “识别图中二维码”,即可关注哈尔滨工业大学社会计算与信息检索研究中心微信公共号:”哈工大SCIR” 。


