赛尔原创 | COLING 2018 对话语义理解的序列到序列数据增强
论⽂作者:侯宇泰,刘一佳,车万翔,刘挺
关键词:自然语言理解,数据增强,端到端模型
联系邮箱: ythou@ir.hit.edu.cn
本⽂介绍哈尔滨⼯业⼤学社会计算与信息检索研究中⼼( SCIR)录⽤于COLING 2018的论⽂《Sequence-to-Sequence Data Augmentation for Dialogue Language Understanding》中的⼯作。在本文中,我们研究了面向任务的对话系统中语言理解模块的数据增强问题。相比之前的工作在生成新语句时不考虑语句间关系,我们利用训练数据中与一个语句具有相同语 义的其他句子,提出了基于序列到序列生成的数据增强框架。我们创新地将多样性等级 结合到话语表示中以使模型产生多样化的语句数据,而这些多样化的新语句有助于改善语言理解模块。在航空旅行信息系统数据集以及一个新标注的斯坦福多轮多域对话数据集上的实验结果表明,当训练集仅包含数百句语句时,我们的框架在F值上分别实现了6.38和10.04的显著提升。案例研究也证实我们的方法能够产生多样化的新句子。
1 引言
语言理解(LU)是面向任务的对话系统管道中的初始和必要组成部分(Young et al. 2013)。构建健壮的LU的一个难点是处理用户表达需求的各种表述方式。在一些无法得到大规模标记数据的新域中,这个问题变得更加严重。训练数据不足使得LU容易受到没见过的用户语句的影响,这些语句在语法上与现有的训练数据不同但在语义上相关。这种识别能力的不足会进一步损害了整个面向任务的对话系统的流程。
数据增广(Data Augmentation)是通过扩大机器学习系统中训练数据的大小来解决数据不足问题的有效方法。 数据增广在诸如图像分类、语音识别等很多领域取得了成功,但是在任务型对话上的相关研究还很少,据我们所知目前Kurata等人 2016年的工作(Kurata et al. 2016)。Kurata等人在工作中通过给seq2seq的中间表示加入随机扰动的方式生成新的句子。但是他们没有考虑句子之间的关系。
在本文中,我们研究了LU的数据增强问题,并提出了一种新的数据驱动框架,该框架利用训练数据中相同语义的语句之间的关系。Seq2Seq模型是我们框架的核心,输入一种表述的句子,生成不同表述的新句子。为了进一步鼓励多样化生成,我们把一种新的多样性等级嵌入到话语表示中。在训练seq2seq模型时,多样性等级也用于过滤相似的表述对。 提出的这些方法生成了多样的增强数据,显着提高了标记数据稀缺情况下的LU性能。
2 方法
2.1 数据增强流程
流程如图所示,当给定一个句话,我们首先通过抽槽操作进行去多样化,再将想要生成的不同多样化等级以token的形式加到语句表示中。然后我们把原句和多样化等级一起作为输入送入到Seq2Seq模型中,生成新的语句,最后对新的语句进行填槽操作从而得到增强数据。
我们把基于Seq2Seq和多样化等级K的数据增强模型形式化为图1:
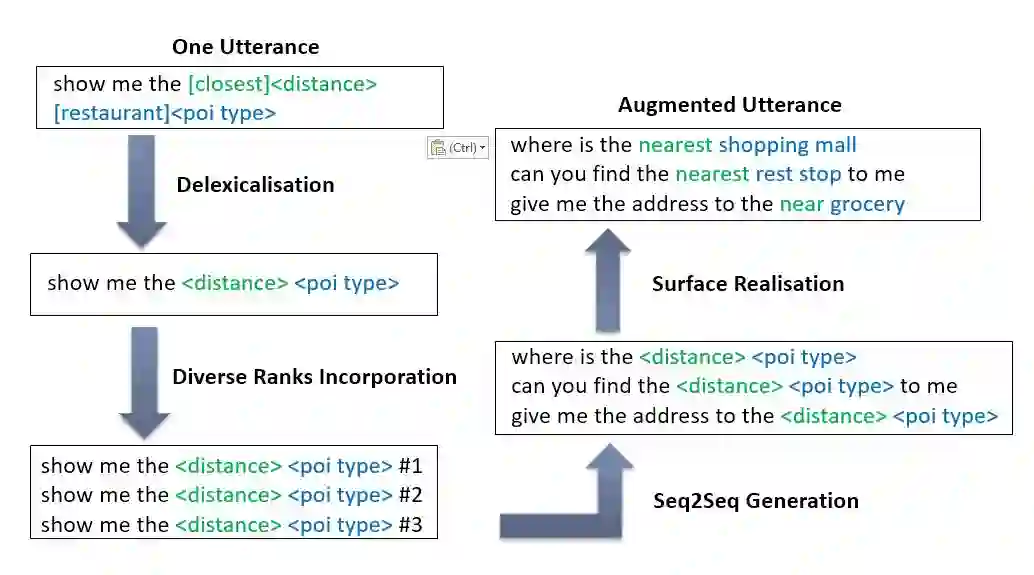
图1. 基于Seq2Seq和多样化等级K的数据增强模型
2.2 Seq2Seq模型训练流程
其中的seq2seq的训练流程如图2所示。我们将具有相同语义框架的句子配对,然后计算句子对的多样化分数并以此进行排序作为多样化等级。在使用多样化等级过滤掉相似的句子对后,我们把加上多样化等级的句子对送到seq2seq中进行训练。
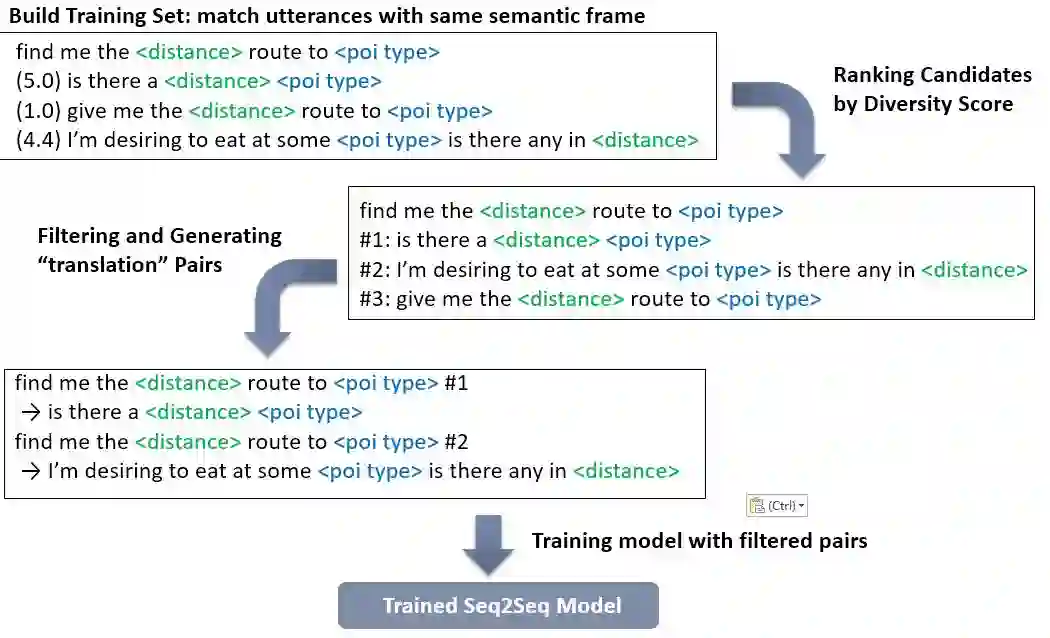
图2. seq2seq的训练流程
2.3 多样化等级
本文中的多样化等级由多样化的分数进行排序得到,其中多样化分数表示于一相同的两句话表述的不同程度。计算方式如下:

其中,LDP为长度惩罚,用于惩罚由于长度相差过多而导致的语义偏差,计算方法如下:
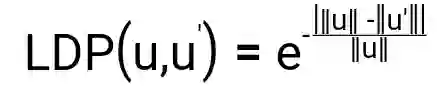
3 实验结果
3.1 数据
在本文中,我们在广泛用于LU的ATIS数据集进行了实验。为了在ATIS之外的新域上测试我们的模型,我们还在斯坦福对话数据集上做了一个新的有LU标注数据集。为了模拟数据不足的情况,我们按照Cheng等人的划分,将ATIS训练数据划分为大中小三种数据子集(Chen et al. 2016a)。
3.2 主实验
我们在ATIS和Stanford数据上的实验结果如下图所示。我们的基线模型是vanilla BiLSTM的slot 标注模型,我们的数据增强模型使用相同的模型结构,但是使用我们的方法生成的增强数据进行训练。 与基线相比,我们的增强方法显着提高了LU性能,在小比例数据上获得了6.38 F-score提升,在中等比例数据上获得了2.02 F-score提升。
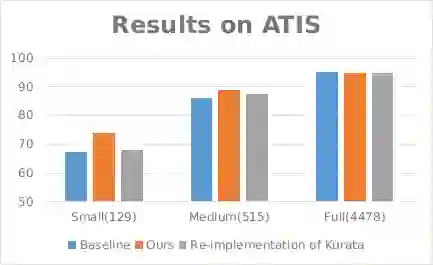
图3. ATIS数据集上实验结果
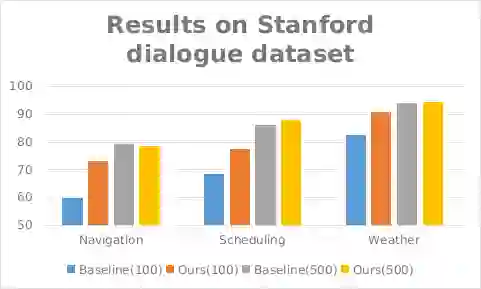
图4. Stanford dialogue dataset上的实验结果

图5. 与ATIS数据集上最优的模型进行比较
3.3 消融测试(Ablation Test)
为了探究我们方法的各个组成模块的作用与贡献,我们进行了消融测试,测试结果如下图所示。除了F-score之外,我们还对比了去掉不同组成时模型生成的新语句个数、以及新语句与训练集的最小编辑距离,以反映我们模型生成多样化数据的能力。
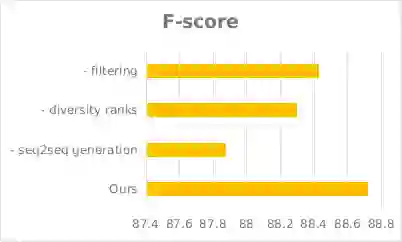
图6. 分别去掉各模块后F值的变化
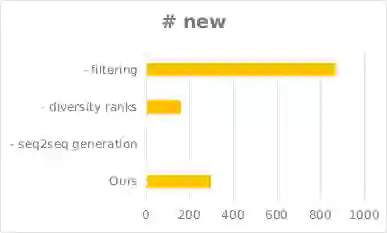
图7. 分别去掉各模块后生成新语句数的变化
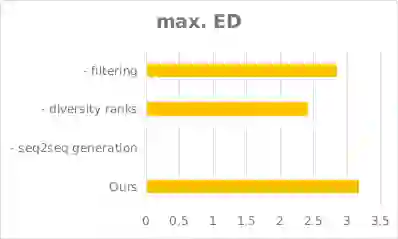
图8. 分别去掉各模块后新语句与训练集的最小编辑距离的变化
3.4 训练集大小对增强效果的影响
下图探究了不同的增强数据大小对增强效果的影响,结果显示我们的增强方法在只有数百个训练样本时能极大提升LU效果。
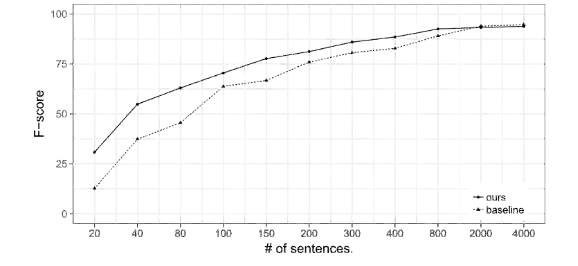
图9. 随着ATIS训练数据规模的变化,我们模型得到的F值的变化情况
3.5 案例
案例显示我们的模型生成了全新的且不同于训练目标的新句子。
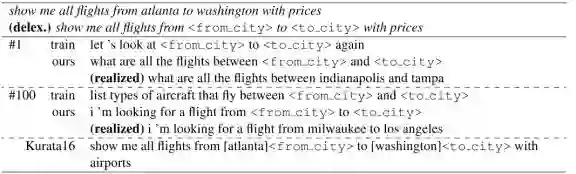
图10. 案例一

图11. 案例二
4 结论
在本文中,我们研究了LU的数据增强问题。我们提出了一个数据驱动的框架来增强训练数据。我们的框架利用相同语义的不同表达的语句来训练seq2seq模型。 我们还提出了一种新的多样性等级,用以提升生成语句的多样性和过滤相似的句子。在实验中,当训练集只有数百个语句时,我们的模型分别实现了6.38和10.04 F-score的显著提升。案例研究还表明我们的框架能够生成多种表达式。
5 参考文献
Steve Young, Milica Gasic, Blaise Thomson, and Jason D Williams. 2013. Pomdp-based statistical spoken dialog systems: A review. Proc. of the IEEE, 101(5):1160–1179.
Gakuto Kurata, Bing Xiang, and Bowen Zhou. 2016a. Labeled data generation with encoder-decoder LSTM for semantic slot filling. In INTERSPEECH 2016, pages 725–729.
Yun-Nung Chen, Dilek Hakanni-Tur, Gokhan Tur, Asli Celikyilmaz, Jianfeng Guo, and Li Deng. 2016a. Syntax or semantics? knowledge-guided joint semantic frame parsing. In SLT, pages 348–355.
本期责任编辑: 丁 效
本期编辑: 吴 洋
“哈工大SCIR”公众号
主编:车万翔
副主编: 张伟男,丁效
责任编辑: 张伟男,丁效,赵森栋,刘一佳
编辑: 李家琦,吴洋,刘元兴,蔡碧波,孙卓,赖勇魁
长按下图并点击 “识别图中二维码”,即可关注哈尔滨工业大学社会计算与信息检索研究中心微信公共号:”哈工大SCIR” 。





