知识在检索式对话系统的应用


近年来,随着自然语言处理(NLP)和深度学习等领域的深入研究和应用,构建一个人与机器可以自然对话的系统引来更多学术界和工业界的关注。
从应用的角度来看对话系统可以分为两大类:
(1)任务导向和(2)非任务导向。任务导向的对话系统,通过人机之间的多轮对话,来完成一个指定的任务。如客服系统,用户可以购买机票、预定餐馆、办理业务等。非任务导向的系统,通常是单轮对话,如闲聊、问答类。
从技术的角度看,数据驱动的对话系统也可分为两大类:
(1)基于检索模型和(2)基于生成式模型。基于检索的对话系统,需要预先构建好数据,通过检索模型来选择最合适的答案。而基于生成式模型的对话系统,则利用训练模型来生成序列回答。实际中,对话系统往往是结合检索模型和生成式模型二者的优点共同实现。
本文探讨一个非任务导向对话系统中的问题:无论是基于检索还是生成式模型,仅考虑当前对话上下文的情况下,经常会出现一些模糊、甚至是无意义的回答。直觉上,对话机器人显得很笨拙、不够智能。反观人与人之间的对话往往是围绕一个话题,而且聊天也不限于当前的对话内容,经常会基于人的知识进行丰富和扩展,让聊天更加自然地进行。因此一个直接的想法就是:能否通过引入外部的知识信息来丰富和提升人机对话的体验?
参考AAAI 2018的文章[2]:利用常识性知识增强端到端的对话系统,后文详细探讨知识数据如何提升对话系统。
关键词
知识、语义网络、对话系统、LSTM、词向量表示、记忆网络
知识的表示和推理是AI领域一个重要的方向,研究如何表示现实世界的知识以及如何运用知识来解决问题。一般地,知识可以通过如逻辑表达式、产生式规则(如IF-THEN)、语义网络(如概念图)等来表示。这里,我们采用基于语义网络表示的知识。
语义网络:基于图来构建,其中节点表示概念(实体对象)、而边表达概念节点之间的关系,节点之间的关系可以表示为一个三元组形式如:<concept1, relation, concept2>。
ConceptNet [3]:是一个完全免费的语义网络,设计之初主要是帮助机器理解人类词语的意义。
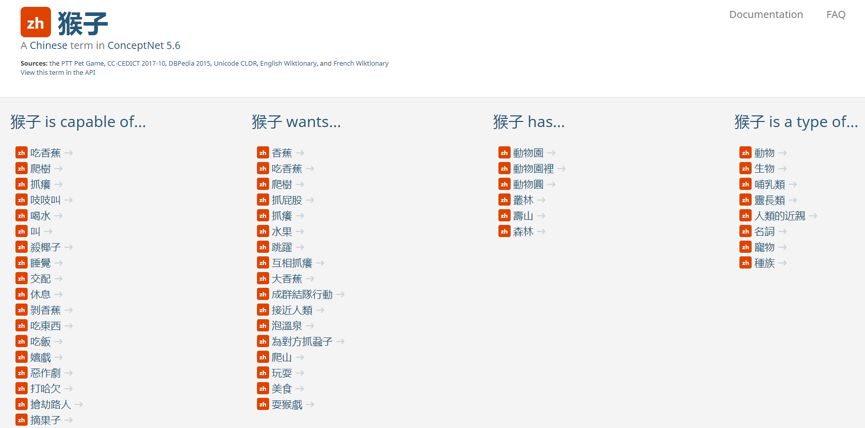
图1. “猴子”
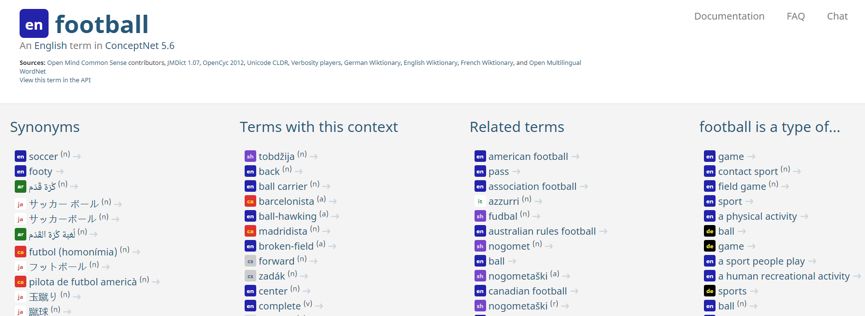
图2.“football”
图2.包含了“football”有多种语言的同义词如“soccer”,“football”是一类游戏、运动项目等信息。
SenticNet [4]:是一个描述概念之间的情感语义网络。
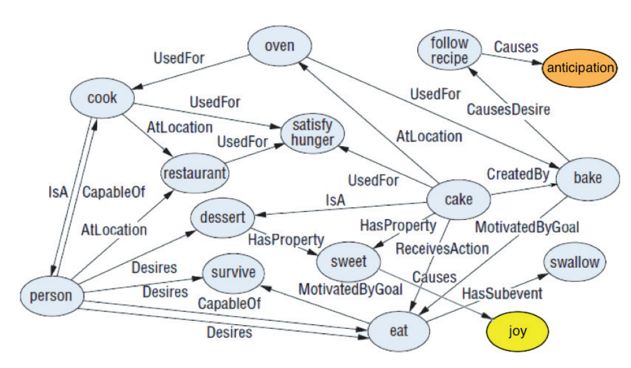
图3. SenticNet例子
如上图3.表示出cook是一种person,cook的位置一般是在restaurant,cake可以用于satisfy hunger,sweet可以产生joy等信息。
基于前面介绍的知识库,接下来主要是基于论文[2]来详细介绍如何利用知识来增强端到端的对话系统。
>>>> 任务定义
原论文主要是在整合常识性知识到基于检索的对话模型中,消息(上下文)x和回答y是从词表V中的词组成的序列。给定x和一组回答候选集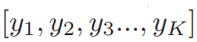
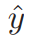
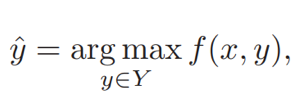
这里,f(x, y)是一个评估x和y兼容性的打分函数。通过<消息,回答,标签>三元组来训练。其中标签为二元值,区别<消息,回答>是否来自于真实数据还是随机组合。
>>>> 模型一:Dual-LSTM编码器
Dual-LSTM编码器将消息x和回答y经过相同LSTM网络的最后层隐状态作为固定大小的嵌入式表示
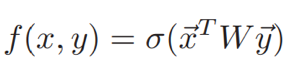
这里,参数矩阵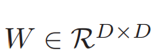
>>>> 知识检索
有了知识库,检索与对话消息相关的知识,可以通过如下步骤:
构建词典:原有语义网络中的三元组<c1, r,c2>,c1和c2分别是概念,r表示c1和c2之间的关系。对于概念c构建词典,key为c,value表示元组信息。
检索阶段:通过消息x与词典key的n-gram进行匹配,召回所有相关的元组数据作为知识。
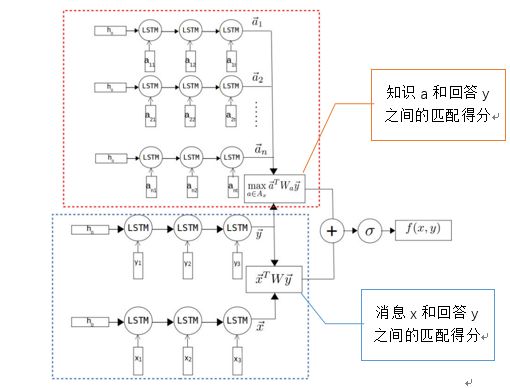
图4. Tri-LSTM编码器
>>>> 模型二:Tri-LSTM编码器
如图4所示,Tri-LSTM在Dual-LSTM编码器(图中下半部分)的基础上,对于检索得到的所有元组Ax采用另一个LSTM进行编码(图中上半部分),这里作者简单的将任意一个知识元组a(<c1, r, c2>)转换为一个词序列:
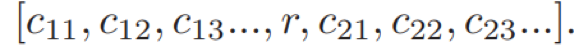
对于多个相关的元组a,这里只选择匹配得分最大的一个。匹配得分函数通过知识a和回答y来计算,如下:
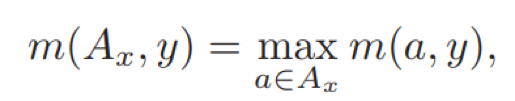
匹配最相关的元组(知识)之后,消息x和回答y的最终得分在考虑x和y本身的同时,考虑检索得到的知识匹配得分,如下:
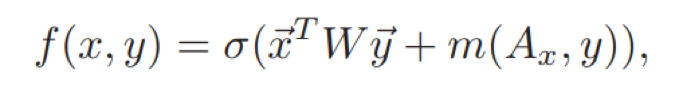
直观上这里优化目标表明一个合适的回答y不仅依赖于消息x,同时也会根据x检索得到的知识产生关联。因此,回答y可以包含更多关于某个知识的信息,提升对话体验。
>>>> 对比方法
方法一:监督词向量SWE(supervised word embedding)直接利用消息x和回答y的词袋向量(Bag-of-words Embedding)
,
的内积计算得分函数,如下:
考虑检索得到的知识a,也同样表示为词袋向量,因此有以下考虑知识的最终得分函数:
可以看到,这里线性模型SWE与Tri-LSTM编码器的区别,主要是SWE利用词袋向量而不是RNN来表示句子。
方法二:记忆网络MM(memory network)是一类经典的方法,在语言理解中引入知识模块。在这里,MM的输出记忆表示为
,其中
是检索到知识的词袋向量表示,
是消息x在记忆Ax(这里检索知识作为记忆模块)上的注意力信号
。因此,消息x和回答y的最终打分函数如下:
可以看到MM与Tri-LSTM利用知识的区别在于MM考虑回答y的权重是通过消息x和知识a的注意力信号来计算,而Tri-LSTM则是直接利用回答y和知识a计算之后选择最大。
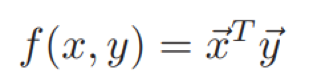
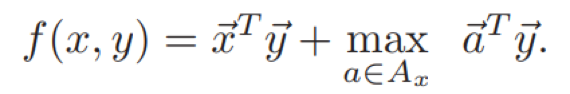
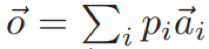
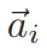
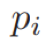
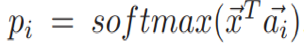
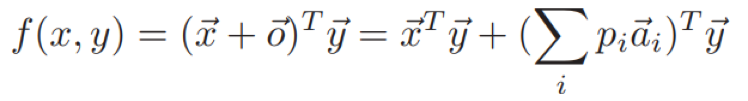
>>>> 实验结果
实验部分,数据集采用一个100万规模的Twitter<消息,回答>对作为正样本,负样本中消息的答案则通过随机采样得到。
首先来总结对比前面提到的多个模型之间的区别,如下:
模型 |
Encoder |
考虑知识 |
非线性转换 |
知识选择 |
SWE |
词袋向量 |
是 |
否 |
Max |
MM |
词袋向量 |
是 |
否 |
Attention weight |
Dual-LSTM |
LSTM |
否 |
是 |
否 |
Tri-LSTM |
LSTM |
是 |
是 |
Max |
原论文主要是集中在基于检索的对话模型,因此召回作为评价指标,结果如下:

图5. 实验结果
可以看到Tri-LSTM相比其他基础模型,结果最好。
>>>> 一个例子

如上所示,根据消息检索到知识有:“insomnia(失眠症)”是一类睡眠问题,“夏威夷”是一个流行的度假目的地、是一个太平洋的岛屿,“too_much_work”可以产生度假的想法等。很明显,考虑了知识的回答使得人机对话的体验更好(图中相同颜色表示对应的知识和回答)。
本文主要是探讨对话系统中回答模糊、缺少有意义的话题等问题,希望借助外部知识来解缓解。并且参考论文[2]的方法,简单容易实现,可以考虑在实际的对话系统中尝试。
引用
[1]:A Survey onDialogue Systems: Recent Advances and New Frontiers https://arxiv.org/pdf/1711.01731.pdf
[2]:AugmentingEnd-to-End Dialogue Systems with Commonsense Knowledge, AAAI 2018, http://sentic.net/dialogue-systems-with-commonsense.pdf
[3]:ConceptNet:http://conceptnet.io/
[4]:SenticNet:https://sentic.net/

 微信ID:WeChatAI
微信ID:WeChatAI
 长按左侧二维码关注
长按左侧二维码关注
登录查看更多
相关内容
专知会员服务
35+阅读 · 2020年4月30日
Arxiv
4+阅读 · 2018年4月13日
Arxiv
4+阅读 · 2018年1月26日



相关VIP内容
专知会员服务
35+阅读 · 2020年4月30日
相关资讯
相关论文
Arxiv
4+阅读 · 2018年4月13日
Arxiv
4+阅读 · 2018年1月26日