赛尔原创 | COLING 2018 中文零指代消解:基于注意力机制的模型
作者:哈工大SCIR博士生 尹庆宇
1 任务介绍
中文的零指代,是中文中存在的一种特殊的现象。它可以被视为是指代现象中的一种特殊情况。具体而言,在中文等代词缺失(pro-dropped)的语言中,读者能够根据上下文的关系推断出来的部分经常被省略,被省略的部分在句子中又承担相应的句法成分,并且回指前文中的某个语言单位。被省略掉的部分称为零指代项或者零代词,被指向的语言单位被称为先行语。图1是一个中文零指代现象的示例。在这里,“Φ”表示一个零代词,它的先行语为"苹果''。

图1 中文零指代示例
零指代消解在中文自然语言处理中扮演着举足轻重的角色。随着自然语言的发展,越来越多的系统被研究以方便信息的传递与交流。如信息检索(Information Retrieval)、信息抽取(Information Extraction)、问答(Question Answering)、自动文摘(Automatic Summarization)和机器翻译(Machine Translation)等系统,能够帮助用户更为方便快捷准确地获得自己所需的内容。在这些系统中,自然语言都扮演着很重要的角色。比如在问答系统中,用户的问题都是通过自然语言的形式提出的,而如何能够让机器正确有效地理解这些问题就成了重中之重。而在实际情况中,用户经常会将省略了的语句作为提问输入。因此,为了更准确且没有遗漏地从文本中抽取相关信息,必须要对文章中的省略现象进行消解。
2 我们的方法
2.1 动机
现有的中文零指代消解系统中,都是把零指代消解问题视作一个分类问题。即每次都拿出一个候选先行语和一个零代词进行分类。这种方法每次只会从局部中选取最优的解。也就是说,用这种单分类的方法构建的零指代消解系统不能有效利用之前的候选先行语分类提供的信息,而该类信息是很重要的,我们需要设计一种模型能够很好的利用之前判断出的候选先行语信息来帮助对后续的候选先行语进行分类。因此,我们把分类的模型用一种序列化的决策的方式来进行分类,把所有的候选先行语视为一个序列,在判断序列后放的候选词的时候能够把之前的序列候选词信息考虑进去。这种序列决策的方法能够利用深度强化学习的方法来实现。综上,我们设计了一种基于强化学习的中文零指代消解系统,旨在解决传统的单分类中文零指代系统中不能很好利用全局信息的缺点。
2.2 方法设计
下边给出一个中文零指代现象在OntoNotes 5.0数据集上的一个实例,在这里φ用来指代零代词。
这次地震φ1 有一些房屋塌的,这里面如果有建房的质量问题,φ2是要追究责任的。
In this earthquck φ1 some rooms collapsed, if there exsit some room quality issues, φ2 will need to call to account.
在这些零代词中,φ2是可消解的零代词,其先行语为"政府/the government'',而另一个零代词则为不可消解零代词。
现有的研究中,研究者们都从零代词的上下文建模的角度出发,对零代词进行表示(Chen and Ng, 2016; Yin et al., 2017a; Yin et al., 2017b)。比如 Chen and Ng (2016)的就利用了一个零代词的前边的词的信息表示零代词;Yin et al. (2017a)利用LSTM的结构利用上下文分别表示零代词的信息。然而,我们发现,在零代词的上下文中,只有一些部分的词是对于表示零代词帮助很大的。比如在句子"two trains in ten weeks ago φ crashed in their way to the southern German countryside" 中,"crashed in their way"能够很好的帮助解释零代词,而其他部分的上下文则没有那么重要。因此,我们希望能够利用某些方法来自动的让模型建模那些更重要的信息。另一方面,对于表示候选先行语,其中也是有一部分词是相对更重要的,而传统方法并没有显示的获取这些重要的信息。
为了更好的解决以上问题,我们提出了一种基于注意力机制的零指代消解模型。对于零代词的建模而言,我们采用了自注意力模型(self-attention mechanism),自动建模更重要的上下文部分。对于候选先行语的建模,我们采用了通用的注意力模型,让其能够自动获取短语的重要成分。传统的零指代方法主要分为两个步骤:零代词的可消解性识别和零代词的消解。在这篇文章中,同已有的方法类似(Chen and Ng, 2016; Yin et al., 2017a; Yin et al., 2017b),我们主要关注第二个子任务,即零代词的消解。其整体流程图如图2所示。
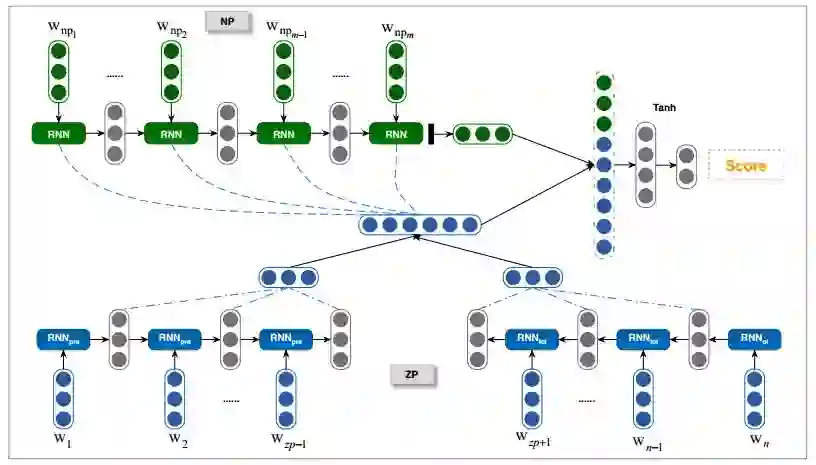
图2 基于注意力机制的的中文零指代消解方法流程图
2.2.1 零代词建模
受Lin et al. (2017)的启发,我们这里利用自注意力机制来建模零代词的上下文信息。我们利用两个循环神经网络(RNN)来分别建模零代词上文和下文,然后利用这些向量进行自注意力的建模。对于一个零代词,我们将其对应的上下文信息利用RNN建模成序列词嵌入(embedding)。
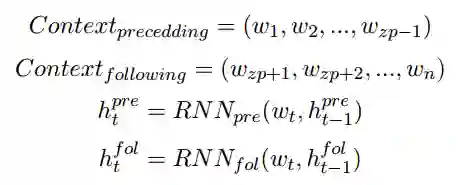
这里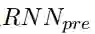
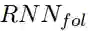
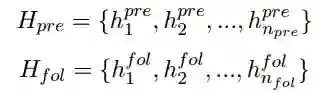
然后我们利用自注意力机制来计算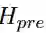
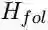
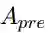
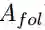
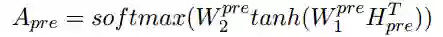
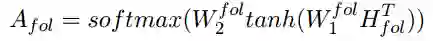
这里的softmax()被用在矩阵维度的第二维度,注意力矩阵A 即可被当做一种对零代词上下文的多层注意力表示。最后,我们将其相乘得到零代词的表示(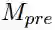
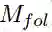
2.2.2 候选先行语建模
我们有了零代词的表示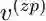
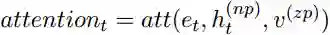
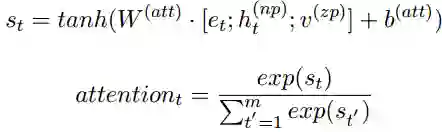
之后,我们将其加权平均得到候选先行语的表示。
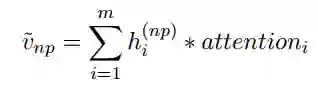
2.2.3 计算消解概率
通过对零代词和候选先行语的建模,我们得到其表示,并分别记为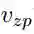
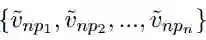
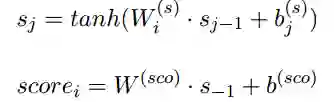
这里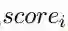
3 实验结果
我们在OntoNotes 5.0语料上进行了实验,并选取了目前世界上最好的中文指代消解系统作为基准系统进行对比。在实验的过程中,根据不同情况的特点,我们共设计了三组对比实验。OntoNotes语料是由6个不同来源的语料组成的,其分别为:广播新闻(BN)、报纸新闻(NW)、广播采访(BC)、电话通话(TC)、微博(WB)和杂志(MZ)。我们的每组实验除了在整体语料上对比外,还对其不同分类做出了对比。我们假设所有的零代词的可消解性都是标注好了的,即只对可消解的零代词进行消解,并且依存树结构是人工标注的标准树结构(Gold Parse),实验结果如表1所示。
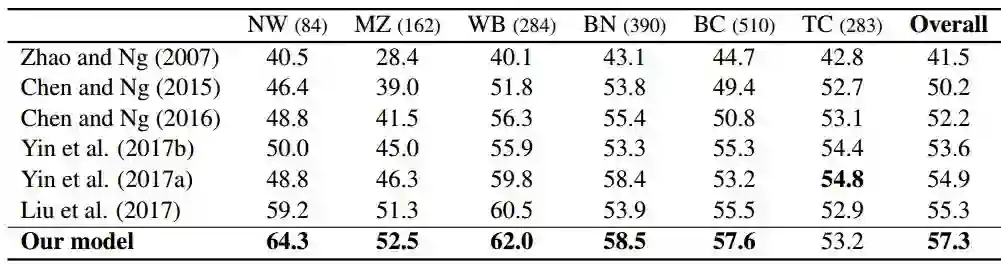
表1 实验结果
我们设置注意力矩阵的维数为2(r = 2)。从结果中,我们可以发现我们的系统得到了F值为57.3%,超过了最好的基准系统。
4 总结
我们提出了一种基于注意力机制的零代词消解模型,旨在解决传统方法不能有效获取重要上下文信息以及内容信息的缺点。我们的方法能够让模型更好的建模有效信息,因而能得到一个更好的系统。论文发表在Coling 2018 (https://arxiv.org/abs/1806.03711)。
References
Chen Chen and Vincent Ng. 2016. Chinese zero pronoun resolution with deep neural networks. In Proceedings of the 54rd Annual Meeting of the ACL.
Zhouhan Lin, Minwei Feng, Cicero Nogueira dos Santos, Mo Yu, Bing Xiang, Bowen Zhou, and Yoshua Bengio. 2017. A structured self-attentive sentence embedding. arXiv preprint arXiv:1703.03130.
Qingyu Yin, Yu Zhang, Weinan Zhang, and Ting Liu. 2017a. Chinese zero pronoun resolution with deep memory network. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pages
1309–1318.
Qingyu Yin, Yu Zhang, Weinan Zhang, and Ting Liu. 2017b. A deep neural network for chinese zero pronoun resolution. In IJCAI.
点击文末“阅读原文”查看往期精彩原创推送。
本期责任编辑: 张伟男
本期编辑: 吴 洋
“哈工大SCIR”公众号
主编:车万翔
副主编: 张伟男,丁效
责任编辑: 张伟男,丁效,赵森栋,刘一佳
编辑: 李家琦,赵得志,赵怀鹏,吴洋,刘元兴,蔡碧波,孙卓
长按下图并点击 “识别图中二维码”,即可关注哈尔滨工业大学社会计算与信息检索研究中心微信公共号:”哈工大SCIR” 。






