朴素贝叶斯分类
朴素贝叶斯模型是一组非常简单快速的分类算法,通常适用于维度非常高的数据集。因为运行速度快,而且可调参数少,因此非常适合为分类问题提供快速粗糙的基本方案。本文重点介绍朴素贝叶斯分类器(naive Bayes classifiers)的工作原理,并通过一些示例演示朴素贝叶斯分类器在经典数据集上的应用。
1. 贝叶斯分类
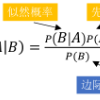
朴素贝叶斯分类器建立在贝叶斯分类方法的基础上,其数学基础是贝叶斯定理(Bayes's theorem)——一个描述统计量条件概率关系的公式。在贝叶斯分类中,我们希望确定一个具有某些特征的样本属于某类标签的概率,通常记为 P (L |特征 )。贝叶斯定理告诉我们,可以直接用下面的公式计算这个概率:
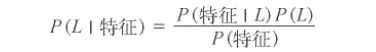
假如需要确定两种标签,定义为 L1 和 L2,一种方法就是计算这两个标签的后验概率的比值:
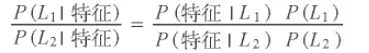
现在需要一种模型,帮我们计算每个标签的 P ( 特征| Li)。这种模型被称为生成模型,因为它可以训练出生成输入数据的假设随机过程(或称为概率分布)。为每种标签设置生成模型是贝叶斯分类器训练过程的主要部分。虽然这个训练步骤通常很难做,但是我们可以通过对模型进行随机分布的假设,来简化训练工作。
之所以称为“朴素”或“朴素贝叶斯”,是因为如果对每种标签的生成模型进行非常简单的假设,就能找到每种类型生成模型的近似解,然后就可以使用贝叶斯分类。不同类型的朴素贝叶斯分类器是由对数据的不同假设决定的,下面将介绍一些示例来进行演示。首先导入需要用的程序库:

2. 高斯朴素贝叶斯
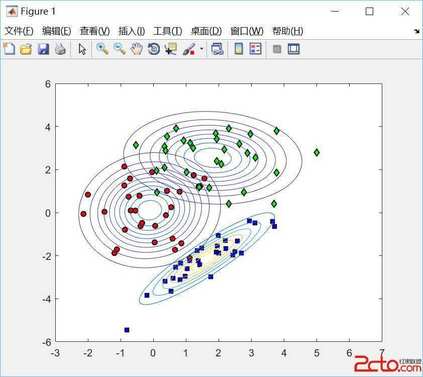
最容易理解的朴素贝叶斯分类器可能就是高斯朴素贝叶斯(Gaussian naive Bayes)了,这个分类器假设每个标签的数据都服从简单的高斯分布。假如你有下面的数据(如图 1 所示):

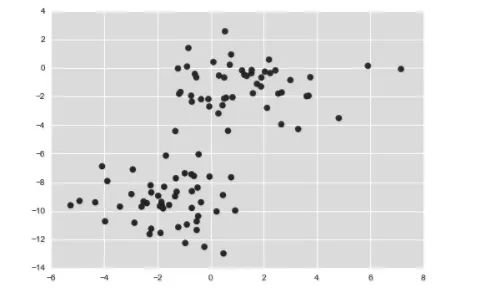
图1 高斯朴素贝叶斯分类数据
一种快速创建简易模型的方法就是假设数据服从高斯分布,且变量无协方差(no covariance,指线性无关)。只要找出每个标签的所有样本点均值和标准差,再定义一个高斯分布,就可以拟合模型了。这个简单的高斯假设分类的结果如图 2 所示。
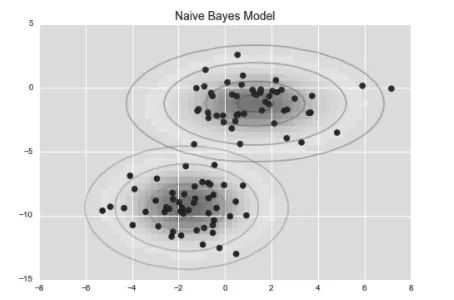
图2 高斯朴素贝叶斯模型可视化图
图中的椭圆曲线表示每个标签的高斯生成模型,越靠近椭圆中心的可能性越大。通过每种类型的生成模型,可以计算出任意数据点的似然估计(likelihood)P ( 特征| L1),然后根据贝叶斯定理计算出后验概率比值,从而确定每个数据点可能性最大的标签。
该步骤在 Scikit-Learn 的 sklearn.naive_bayes.GaussianNB 评估器中实现:

现在生成一些新数据来预测标签:

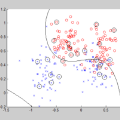
可以将这些新数据画出来,看看决策边界的位置(如图 3 所示):

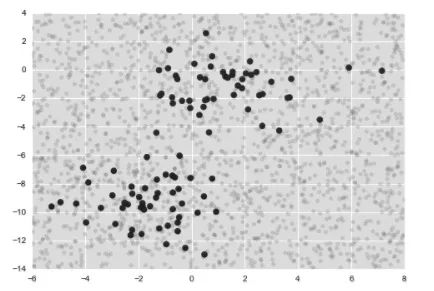
图3 高斯朴素贝叶斯分类可视化图
可以在分类结果中看到一条稍显弯曲的边界——通常,高斯朴素贝叶斯的边界是二次方曲线。
贝叶斯主义(Bayesian formalism)的一个优质特性是它天生支持概率分类,我们可以用predict_proba 方法计算样本属于某个标签的概率:
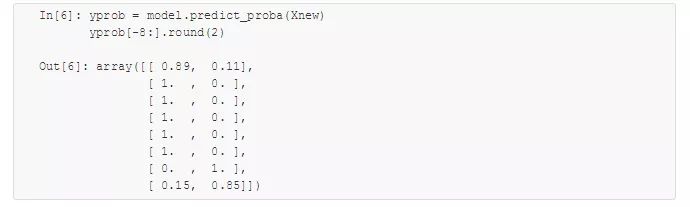
这个数组分别给出了前两个标签的后验概率。如果你需要评估分类器的不确定性,那么这类贝叶斯方法非常有用。
当然,由于分类的最终效果只能依赖于一开始的模型假设,因此高斯朴素贝叶斯经常得不到非常好的结果。但是,在许多场景中,尤其是特征较多的时候,这种假设并不妨碍高斯朴素贝叶斯成为一种有用的方法。
3. 多项式朴素贝叶斯
前面介绍的高斯假设并不意味着每个标签的生成模型只能用这一种假设。还有一种常用的假设是多项式朴素贝叶斯(multinomial naive Bayes),它假设特征是由一个简单多项式分布生成的。多项分布可以描述各种类型样本出现次数的概率,因此多项式朴素贝叶斯非常适合用于描述出现次数或者出现次数比例的特征。
这个理念和前面介绍的一样,只不过模型数据的分布不再是高斯分布,而是用多项式分布代替而已。
案例:文本分类
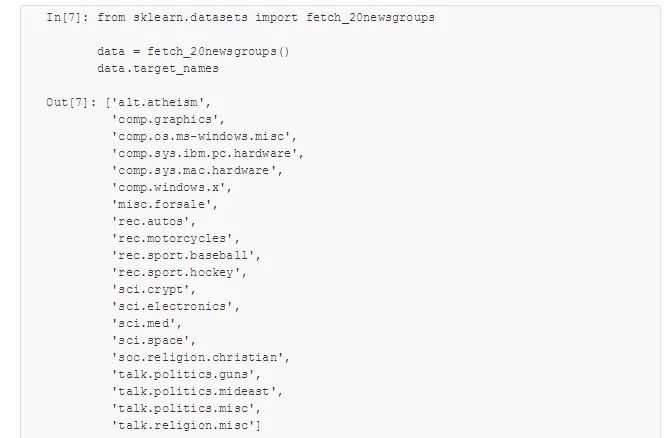
多项式朴素贝叶斯通常用于文本分类,其特征都是指待分类文本的单词出现次数或者频次。这里用 20 个网络新闻组语料库(20 Newsgroups corpus,约 20 000 篇新闻)的单词出现次数作为特征,演示如何用多项式朴素贝叶斯对这些新闻组进行分类。首先,下载数据并看看新闻组的名字:
为了简化演示过程,只选择四类新闻,下载训练集和测试集:

选其中一篇新闻看看:
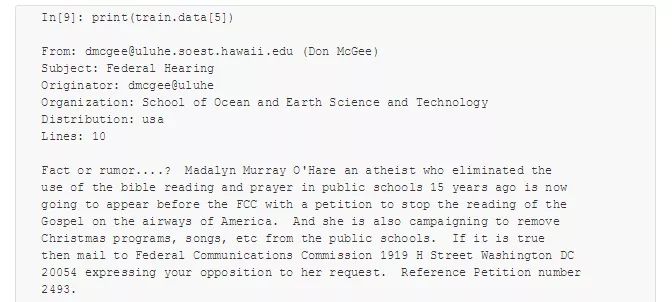
为了让这些数据能用于机器学习,需要将每个字符串的内容转换成数值向量。可以创建一个管道,将 TF–IDF 向量化方法与多项式朴素贝叶斯分类器组合在一起:

通过这个管道,就可以将模型应用到训练数据上,预测出每个测试数据的标签:

这样就得到每个测试数据的预测标签,可以进一步评估评估器的性能了。例如,用混淆矩阵统计测试数据的真实标签与预测标签的结果(如图 4 所示):
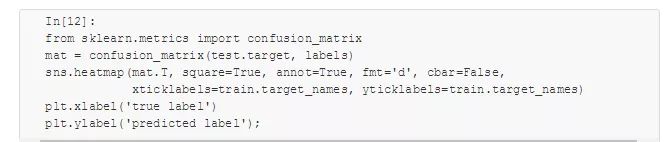
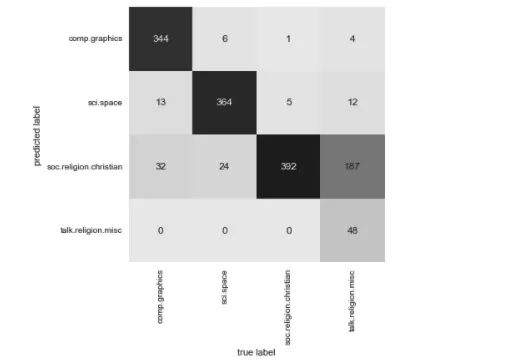
图4 多项式朴素贝叶斯文本分类器混淆矩阵
从图中可以明显看出,虽然用如此简单的分类器可以很好地区分关于宇宙的新闻和关于计算机的新闻,但是宗教新闻和基督教新闻的区分效果却不太好。可能是这两个领域本身就容易令人混淆!
但现在我们有一个可以对任何字符串进行分类的工具了,只要用管道的 predict() 方法就可以预测。下面的函数可以快速返回字符串的预测结果:

下面试试模型预测效果:

虽然这个分类器不会比直接用字符串内单词(加权的)频次构建的简易概率模型更复杂,但是它的分类效果却非常好。由此可见,即使是一个非常简单的算法,只要能合理利用并进行大量高维数据训练,就可以获得意想不到的效果。
4. 朴素贝叶斯的应用场景
由于朴素贝叶斯分类器对数据有严格的假设,因此它的训练效果通常比复杂模型的差。其优点主要体现在以下四个方面。
训练和预测的速度非常快。
直接使用概率预测。
通常很容易解释。
可调参数(如果有的话)非常少。
这些优点使得朴素贝叶斯分类器通常很适合作为分类的初始解。如果分类效果满足要求,那么万事大吉,你获得了一个非常快速且容易解释的分类器。但如果分类效果不够好,那么你可以尝试更复杂的分类模型,与朴素贝叶斯分类器的分类效果进行对比,看看复杂模型的分类效果究竟如何。朴素贝叶斯分类器非常适合用于以下应用场景。
假设分布函数与数据匹配(实际中很少见)。
各种类型的区分度很高,模型复杂度不重要。
非常高维度的数据,模型复杂度不重要。
后面两条看似不同,其实彼此相关:随着数据集维度的增加,任何两点都不太可能逐渐靠近(毕竟它们得在每一个维度上都足够接近才行)。也就是说,在新维度会增加样本数据信息量的假设条件下,高维数据的簇中心点比低维数据的簇中心点更分散。因此,随着数据维度不断增加,像朴素贝叶斯这样的简单分类器的分类效果会和复杂分类器一样,甚至更好——只要你有足够的数据,简单的模型也可以非常强大。

本文内容节选自《Python数据科学手册》第5章机器学习中的部分内容。原版美亚 4.5 星评好书,中文版一上架即位列京东数据处理图书新书榜首。Scikit-Learn、IPython 等库代码贡献者、华盛顿大学 eScience 学院知名教授 Jake VanderPlas 作品。掌握用 Scikit-Learn、NumPy 等工具高效存储、处理和分析数据。

Python Data Science Handbook
作者:Jake VanderPlas
译者:陶俊杰,陈小莉
最受期待和好评的 Python 数据科学参考读本
掌握用 Scikit-Learn、NumPy 等工具高效存储、处理和分析数据
大量示例+逐步讲解+举一反三,从计算环境配置到机器学习实战,切实解决工作痛点
本书以 IPython、NumPy、Pandas、Matplotlib 和 Scikit-Learn 这5个能完成数据科学大部分工作的基础工具为主,从实战角度出发,讲授如何清洗和可视化数据、如何用数据建立各种统计学或机器学习模型等常见数据科学任务,旨在让各领域与数据处理相关的工作人员具备发现问题、解决问题的能力。