
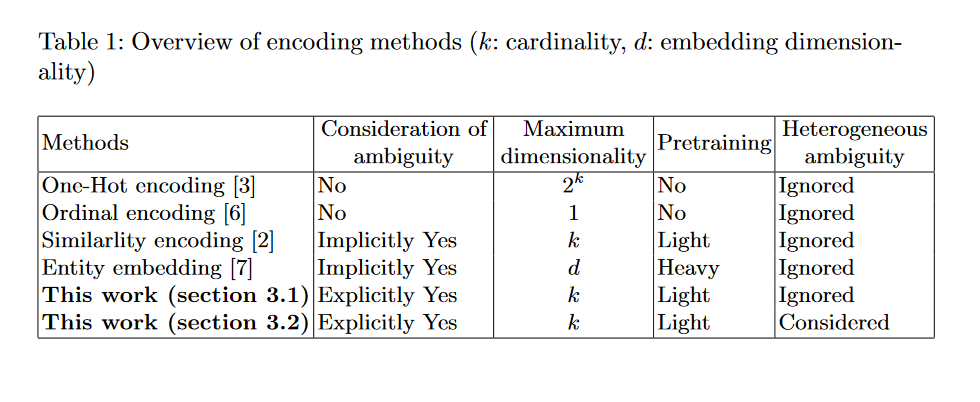
题目: Encoding Categorical Variables with Ambiguity
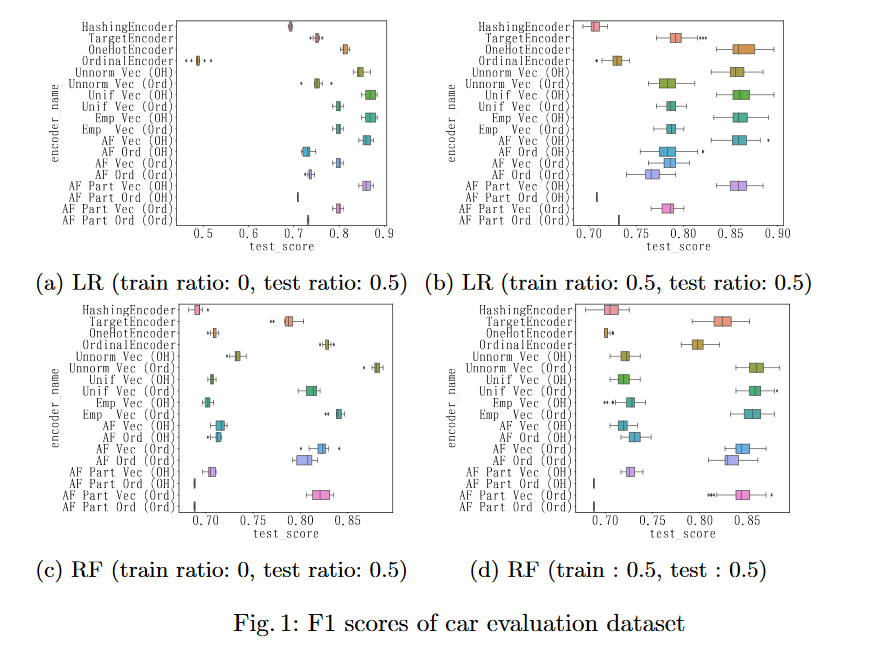
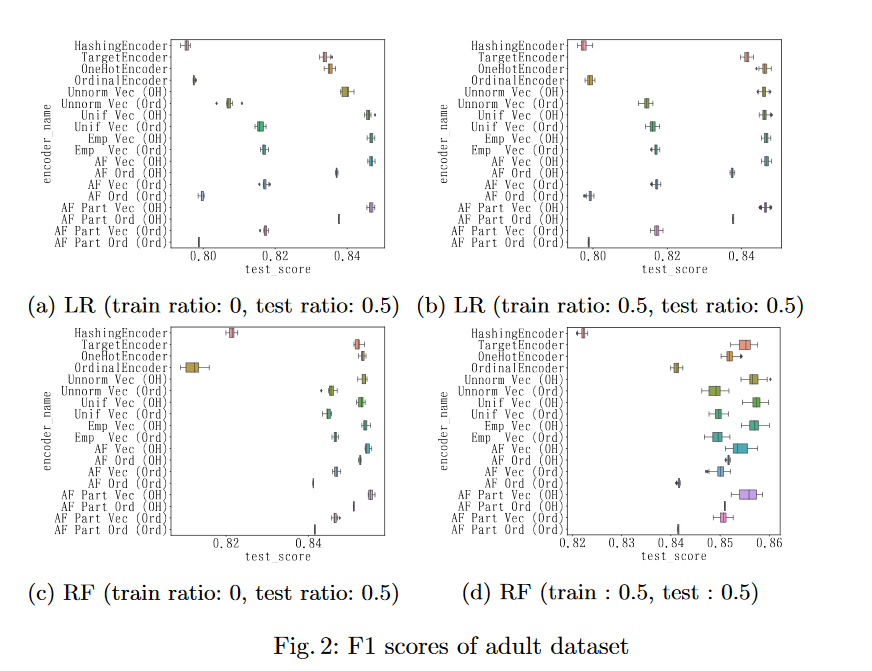
摘要: 大多数有监督的学习方法都假设独立变量是无歧义的。在学习方法的预处理阶段,分类变量常常由一个映射函数从每一个类别映射到一个实数,从而形成数值向量。然而,在现实世界中,有几种自然情况下分类变量是模糊的,例如X的值是a或b。在本文中,我们证明了编码模糊分类变量的问题可以被理解为缺失值的插补问题。我们扩展了现有的一种HoToN编码方法,明确地处理了模糊的分类变量,并在此基础上提出了基于缺失值算法、模糊森林的两种编码方法。一种是missforest算法的简单扩展,另一种是missforest从部分标签学习到编码方法的新应用。我们通过掩蔽两个真实世界的数据集以包含具有模糊性的分类自变量来评估编码方法的效果。
成为VIP会员查看完整内容
相关内容
专知会员服务
32+阅读 · 2020年6月11日
专知会员服务
16+阅读 · 2020年4月8日
专知会员服务
36+阅读 · 2020年3月12日
专知会员服务
18+阅读 · 2019年12月14日
专知会员服务
7+阅读 · 2019年12月3日
专知会员服务
8+阅读 · 2019年12月3日
Arxiv
6+阅读 · 2018年4月9日



相关VIP内容
专知会员服务
32+阅读 · 2020年6月11日
专知会员服务
16+阅读 · 2020年4月8日
专知会员服务
36+阅读 · 2020年3月12日
专知会员服务
18+阅读 · 2019年12月14日
专知会员服务
7+阅读 · 2019年12月3日
专知会员服务
8+阅读 · 2019年12月3日
相关资讯
相关论文
Arxiv
6+阅读 · 2018年4月9日