一文读懂贝叶斯分类算法(附学习资源)

授权转载自数据派THU(作者:冯叶)
贝叶斯分类是一类分类算法的总称,这类算法均以贝叶斯定理为基础,故统称为贝叶斯分类。本文首先介绍分类问题,给出分类问题的定义。随后介绍贝叶斯分类算法的基础——贝叶斯定理。最后介绍贝叶斯分类中最简单的一种——朴素贝叶斯分类,并结合应用案例进一步阐释。
贝叶斯分类
1. 分类问题综述
对于分类问题,我们每一个人都并不陌生,因为在日常生活中我们都在或多或少地运用它。例如,当你看到一个陌生人,你的脑子下意识判断TA是男是女;你可能经常会走在路上对身旁的朋友说“这个人一看就很有钱、那边有个非主流”之类的话,其实这就是一种分类操作。
从数学角度来说,分类问题可做如下定义:
已知集合: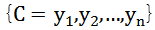
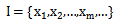
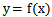
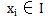
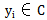
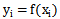
这里要强调的是,分类问题往往采用经验性方法构造映射规则,即一般情况下的分类问题缺少足够的信息来构造100%正确的映射规则,而是通过对经验数据的学习从而实现一定概率意义上正确的分类,因此所训练出的分类器并不是一定能将每个待分类项准确映射到其分类,分类器的质量与分类器构造方法、待分类数据的特性以及训练样本数量等诸多因素有关。
例如,医生对病人进行诊断就是一个典型的分类过程,任何一个医生都无法直接看到病人的病情,只能观察病人表现出的症状和各种化验检测数据来推断病情,这时医生就好比一个分类器,而这个医生诊断的准确率,与他当初受到的教育方式(构造方法)、病人的症状是否突出(待分类数据的特性)以及医生的经验多少(训练样本数量)都有密切关系。
2. 贝叶斯分类的基础——贝叶斯定理
这个定理解决了现实生活里经常遇到的问题:已知某条件概率,如何得到两个事件交换后的概率,也就是在已知P(A|B)的情况下如何求得P(B|A)。这里先解释什么是条件概率:
P(A|B)表示事件B已经发生的前提下,事件A发生的概率,叫做事件B发生下事件A的条件概率。其基本求解公式为:
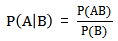
贝叶斯定理之所以有用,是因为我们在生活中经常遇到这种情况:我们可以很容易直接得出P(A|B),P(B|A)则很难直接得出,但我们更关心P(B|A),贝叶斯定理就为我们打通从P(A|B)获得P(B|A)的道路。
下面不加证明地直接给出贝叶斯定理:
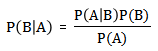
3. 朴素贝叶斯分类
朴素贝叶斯分类的原理与流程:
朴素贝叶斯(分类器)是一种生成模型,它会基于训练样本对每个可能的类别建模。之所以叫朴素贝叶斯,是因为采用了属性条件独立性假设,就是假设每个属性独立地对分类结果产生影响。即有下面的公式:
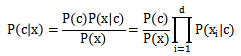
后面连乘的地方要注意的是,如果有一项概率值为0会影响后面估计,所以我们对未出现的属性概率设置一个很小的值,并不为0,这就是拉普拉斯修正(Laplacian correction)。
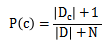
拉普拉斯修正实际上假设了属性值和类别的均匀分布,在学习过程中额外引入了先验识。
整个朴素贝叶斯分类分为三个阶段:
Stage1:准备工作阶段,这个阶段的任务是为朴素贝叶斯分类做必要的准备,主要工作是根据具体情况确定特征属性,并对每个特征属性进行适当划分,然后由人工对一部分待分类项进行分类,形成训练样本集合。这一阶段的输入是所有待分类数据,输出是特征属性和训练样本。这一阶段是整个朴素贝叶斯分类中唯一需要人工完成的阶段,其质量对整个过程将有重要影响,分类器的质量很大程度上由特征属性、特征属性划分及训练样本质量决定。
Stage2:分类器训练阶段,这个阶段的任务就是生成分类器,主要工作是计算每个类别在训练样本中的出现频率及每个特征属性划分对每个类别的条件概率估计,并将结果记录。其输入是特征属性和训练样本,输出是分类器。这一阶段是机械性阶段,根据前面讨论的公式可以由程序自动计算完成。
Stage3:应用阶段,这个阶段的任务是使用分类器对待分类项进行分类,其输入是分类器和待分类项,输出是待分类项与类别的映射关系。这一阶段也是机械性阶段,由程序完成。
4. 半朴素贝叶斯分类
在朴素的分类中,我们假定了各个属性之间的独立,这是为了计算方便,防止过多的属性之间的依赖导致的大量计算。这正是朴素的含义,虽然朴素贝叶斯的分类效果不错,但是属性之间毕竟是有关联的,某个属性依赖于另外的属性,于是就有了半朴素贝叶斯分类器。
为了计算量不至于太大,假定每个属性只依赖另外的一个。这样,更能准确描述真实情况。
公式就变成:
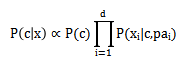
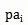
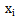
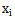
确定父属性有如下方法:
SOPDE方法。这种方法是假定所有的属性都依赖于共同的一个父属性。
TAN方法。每个属性依赖的另外的属性由最大带权生成树来确定。
先求每个属性之间的互信息来作为他们之间的权值。
构件完全图。权重是刚才求得的互信息。然后用最大带权生成树算法求得此图的最大带权的生成树。
找一个根变量,然后依次将图变为有向图。
添加类别y到每个属性的的有向边。
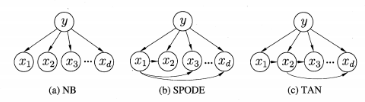
三种方法的属性依赖关系
贝叶斯算法应用举例
以下我们再举一些实际例子来说明贝叶斯方法被运用的普遍性,这里主要集中在机器学习方面。
2.1 中文分词
Google 研究员吴军在《数学之美》系列中就有一篇是介绍中文分词的,这里只介绍一下核心的思想。
分词问题的描述为:给定一个句子(字串),如:南京市长江大桥。如何对这个句子进行分词(词串)才是最靠谱的。例如:
南京市/长江大桥
南京/市长/江大桥
这两个分词,到底哪个更靠谱呢?
我们用贝叶斯公式来形式化地描述这个问题,令 X 为字串(句子),Y 为词串(一种特定的分词假设)。我们就是需要寻找使得 P(Y|X) 最大的 Y ,使用一次贝叶斯可得:
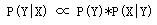
用自然语言来说就是这种分词方式(词串)的可能性乘这个词串生成我们的句子的可能性。我们进一步容易看到:可以近似地将 P(X|Y) 看作是恒等于 1 的,因为任意假想的一种分词方式之下生成我们的句子总是精准地生成的(只需把分词之间的分界符号扔掉即可)。于是,我们就变成了去最大化 P(Y) ,也就是寻找一种分词使得这个词串(句子)的概率最大化。而如何计算一个词串:W1, W2, W3, W4 ..的可能性呢?
我们知道,根据联合概率的公式展开:P(W1, W2, W3, W4 ..) = P(W1) * P(W2|W1) * P(W3|W2, W1) * P(W4|W1,W2,W3) * .. 于是我们可以通过一系列的条件概率(右式)的乘积来求整个联合概率。然而不幸的是随着条件数目的增加(P(Wn|Wn-1,Wn-2,..,W1) 的条件有 n-1 个),数据稀疏问题也会越来越严重,即便语料库再大也无法统计出一个靠谱的 P(Wn|Wn-1,Wn-2,..,W1) 来。
为了缓解这个问题,计算机科学家们一如既往地使用了“天真”假设:我们假设句子中一个词的出现概率只依赖于它前面的有限的 k 个词(k 一般不超过 3,如果只依赖于前面的一个词,就是2元语言模型(2-gram),同理有 3-gram 、 4-gram 等),这个就是所谓的“有限地平线”假设。虽然这个假设似乎有些理想化,但结果却表明它的结果往往是很强大的,后面要提到的朴素贝叶斯方法使用的假设跟这个精神上是完全一致的,我们会解释为什么像这样一个理想化假设能够得到强大的结果。
目前我们只要知道,有了这个假设,刚才那个乘积就可以改写成: P(W1) * P(W2|W1) * P(W3|W2) * P(W4|W3) .. (假设每个词只依赖于它前面的一个词)。而统计 P(W2|W1) 就不再受到数据稀疏问题的困扰了。对于我们上面提到的例子“南京市长江大桥”,如果按照自左到右的贪婪方法分词的话,结果就成了“南京市长/江大桥”。但如果按照贝叶斯分词的话(假设使用 3-gram),由于“南京市长”和“江大桥”在语料库中一起出现的频率为 0 ,这个整句的概率便会被判定为 0 。从而使得“南京市/长江大桥”这一分词方式胜出。
2.2 贝叶斯垃圾邮件过滤器
给定一封邮件,判定它是否属于垃圾邮件。按照先例,我们还是用D来表示这封邮件,注意D由N个单词组成。我们用h+来表示垃圾邮件,h-表示正常邮件。问题可以形式化地描述为求:
P(h+|D) = P(h+) * P(D|h+) / P(D)
P(h-|D) = P(h-) * P(D|h-) / P(D)
其中 P(h+) 和 P(h-) 这两个先验概率都是很容易求出来的,只需要计算一个邮件库里面垃圾邮件和正常邮件的比例就行了。然而 P(D|h+) 却不容易求,因为 D 里面含有 N 个单词 d1, d2, d3, .. ,所以P(D|h+) = P(d1,d2,..,dn|h+) 。我们又一次遇到了数据稀疏性,为何这么说呢?P(d1,d2,..,dn|h+) 就是说在垃圾邮件当中出现跟我们目前这封邮件一模一样的一封邮件的概率是非常小的,因为每封邮件都是不同的,世界上有无穷多封邮件。这就是数据稀疏性,因为可以肯定地说,你收集的训练数据库不管里面含了多少封邮件,也不可能找出一封跟目前这封一模一样的。结果呢?我们又该如何来计算 P(d1,d2,..,dn|h+) 呢?
我们将 P(d1,d2,..,dn|h+)扩展为: P(d1|h+) * P(d2|d1, h+) * P(d3|d2,d1, h+) * .. 。这个式子想必大家并不陌生,这里我们会使用一个更激进的假设,我们假设 di 与 di-1 是完全条件无关的,于是式子就简化为 P(d1|h+) * P(d2|h+) * P(d3|h+) * .. 。这个就是所谓的条件独立假设,也正是朴素贝叶斯方法的朴素之处。而计算 P(d1|h+) * P(d2|h+) * P(d3|h+) * .. 问题至此就变得简单了,只要统计di这个单词在垃圾邮件中出现的频率即可。
通过以上学习我们发现,由于无法穷举所有可能性,贝叶斯推断基本上不能给出肯定的结果。尽管如此,在进行大量的测试后,如果获得的测试结果都无误,我们也会对自己的算法很有信心(即便算法的准确性尚未确认)。事实上,随着新的测试结果出现,算法无误的可信度也在逐渐改变。
生活中,我们经常有意或无意地运用着贝叶斯定理,从算法的角度讲,如果想真正搞懂其中的原理,还需要对数理统计知识进行更加深入地学习并且不断实践,最终相信大家一定能够有所收获。
推荐书目:
《贝叶斯方法:概率编程与贝叶斯推断》
《贝叶斯分析》
《贝叶斯思维:统计建模的Python学习法》
往期精彩文章
点击图片阅读
职位情报局 | 城投意谷、酷旅互动数据、网帅科技相关职位招聘ing







