朴素贝叶斯和贝叶斯网络算法及其R语言实现

作者:鲁伟
一个数据科学践行者的学习日记。数据挖掘与机器学习,R与Python,理论与实践并行。个人公众号:数据科学家养成记 (微信ID:louwill12)
最近在硬怼data mining,总算把几个月前说好的正面刚算法的计划给开了个头。毕竟在小编的计划中将来是打算偏机器学习的,不懂算法实现肯定是转型无望了。既然小编是做贝叶斯方向的,所以数据挖掘算法这块就先从贝叶斯分类器开始,原本以为花不了多少时间,可这两年终归是离扎实的数学计算训练太远了,就算是正面刚也刚了不少时间。这篇文章主要给大家介绍一下贝叶斯分类器中两个重要的算法:朴素贝叶斯和贝叶斯网络,最后把它们在R语言中简单的实现一下。

小编最近在怼的data mining:

⊙ 朴素贝叶斯分类器及R实现
⊙ 贝叶斯网络及R实现
⊙ 朴素贝叶斯与贝叶斯网络的区别
朴素贝叶斯分类器
朴素贝叶斯分类是一种相对简单的分类算法,称它为朴素贝叶斯分类并不是它有多朴素,而是其背后的的思想方法很朴素,它假设了数据集中的所有特征是同等重要且是条件独立的。朴素贝叶斯的思想基础如下:对于给出的待分类项,求解在此项出现的条件下各个类别出现的概率,哪个最大,就认为此待分类项属于哪个类别。就好比我问你一NBA球员单场抢下30个篮板球你猜这球员是打什么位置的,你十有八九猜中锋。为什么呢?因为中锋球员一般呆在内线,个子较高抢到很多篮板球的概率比较大,当然人家也有可能是名大前锋,但在没有其它可用信息下,我们会选择条件概率最大的类别,这就是朴素贝叶斯的思想基础。
朴素贝叶斯的分类过程如图所示,图片来自:
http://www.cnblogs.com/leoo2sk/archive/2010/09/17/naive-bayesian-classifier.html
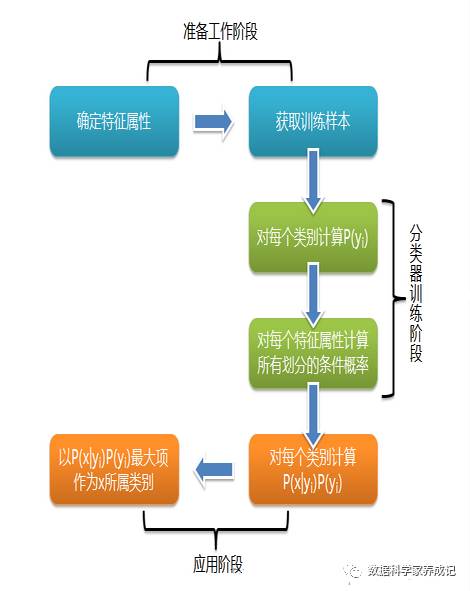
从图中可以看到,贝叶斯分类器可以分为三个阶段:准备工作阶段、分类训练阶段和应用阶段。
准备工作阶段的任务是为朴素贝叶斯分类做必要的准备,主要工作是根据具体情况确定特征属性,并对每个特征属性进行适当划分,然后由人工对一部分待分类项进行分类,形成训练样本集合。这一阶段的输入是所有待分类数据,输出是特征属性和训练样本。
分类训练阶段的任务是生成分类器,计算每个类别在训练样本中的出现频率及每个特征属性划分对每个类别的条件概率估计,在这里类条件概率的计算是至关重要的。其输入是特征属性和训练样本,输出是分类器。(公式不好打,就不放公式了)。
应用阶段就完全交给程序来跑啦,将上面训练好的分类器用R或者Python来实现。
下面来看看朴素贝叶斯简单的在R语言中的实现。
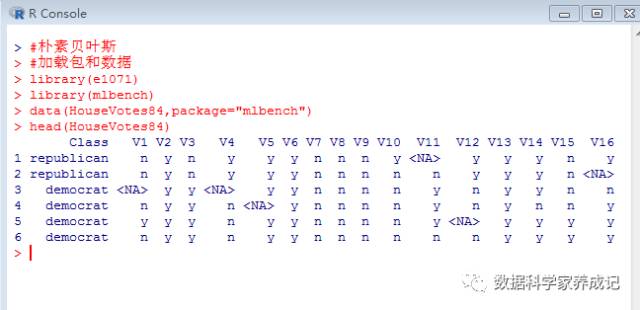
R语言中e1071包和klaR包中的NaiveBayes函数都可以实现朴素贝叶斯分类。本文使用e1071包中分类函数作为例子。数据集使用mlbench包中的HouseVotes84,这是一个关于众议院9种不同票型的数据集。
先简单看下它的数据结构:
使用naiveBayes( )函数进行朴素贝叶斯建模:
model<-naiveBayes(Class~.,data=HouseVotes84)
model
Naive Bayes Classifier for Discrete Predictors
Call:
naiveBayes.default(x = X, y = Y, laplace = laplace)
A-priori probabilities:(类先验概率)
Y
democrat republican
0.6137931 0.3862069
Conditional probabilities:(V1-V16的类条件概率)
V1
Y n y
democrat 0.3953488 0.6046512
republican 0.8121212 0.1878788
(V2-V16类条件概率省略)
#进行分类预测
predict(model,HouseVotes84[1:10,],type="raw")
democrat republican
[1,] 1.029209e-07 9.999999e-01
[2,] 5.820415e-08 9.999999e-01
[3,] 5.684937e-03 9.943151e-01
[4,] 9.985798e-01 1.420152e-03
[5,] 9.666720e-01 3.332802e-02
[6,] 8.121430e-01 1.878570e-01
[7,] 1.751512e-04 9.998248e-01
[8,] 8.300100e-06 9.999917e-01
[9,] 8.277705e-08 9.999999e-01
[10,] 1.000000e+00 5.029425e-11
由上面的预测概率表可知,前10个记录的预测分类为
[1] republican republican republican democrat democrat democrat [7] republican republican republican democrat
贝叶斯网络及R实现

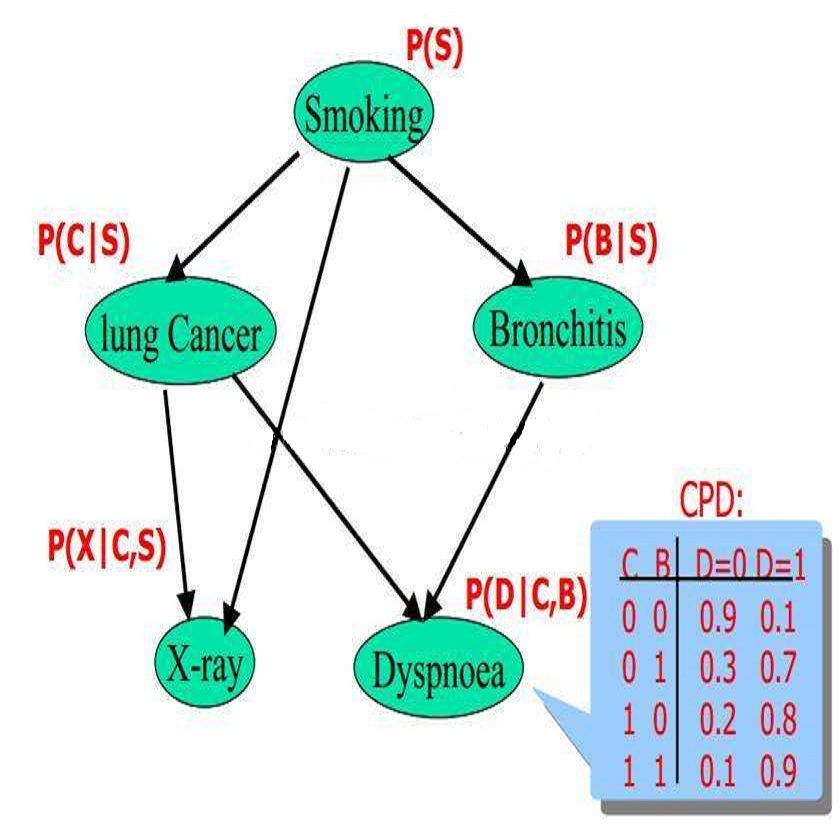
贝叶斯网络(BNN)基本概念有两个:
一个有向无环图(Directed Acyclic Graph)和一个条件概率表集合。
DAG:DAG的结点V包括随机变量(类别和特征),有向连接E(A->B)表示结点A是结点B的parent,且B与A是有依赖关系的(不独立)。 条件概率表集合:同时引入了一个条件性独立(conditional independence)概念,即图中任意结点v在给定v的parent结点的情况下,与图中其它结点都是独立的,也就是说P(v|par(v),x1,x2...,xn) = P(v|par(v))。这里par(v)表示v的parent结点集,x1,x2,...,xn表示图中其它结点。
贝叶斯网络的建模一般包括两个步骤:
(1)创建网络结构;(2)估计每一个结点的概率表中的概率值。网络拓扑结构可以通过程序算法来获得。一旦找到合适的拓扑结构,与各结点关联的概率表就确定了。对这些概率的估计与朴素贝叶斯分类器中的方法类似。
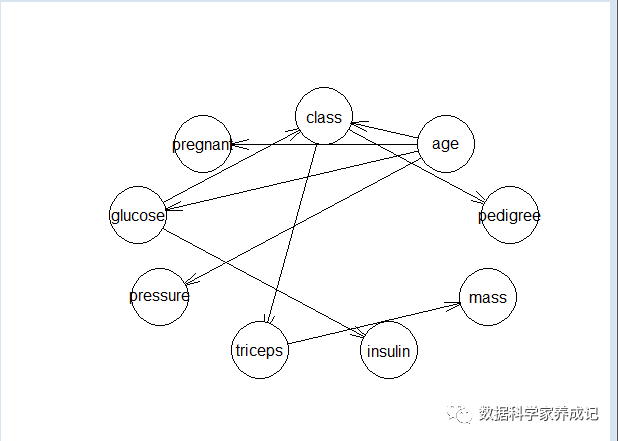
在R语言中可以用bnlearn包来对贝叶斯网络进行建模。但要注意的是bnlearn包不能处理混合数据,所以先将连续数据进行离散化(因子型),然后再进行建模训练。bnlearn包包括结构学习、参数学习和推理三个主要功能,具体如下图。

本例中使用mlbench包中的关于糖尿病诊断的PimaIndiansDiabetes2数据集,鉴于数据集中存在较多的缺失值,在进行贝叶斯网络建模前,我们采用装袋法对缺失值进行填补:
#加载扩展包和数据
library(caret)
data(PimaIndiansDiabetes2,package="mlbench")
#装袋法对缺失值插补
preproc<-preProcess(PimaIndiansDiabetes2[-9],method="bagImpute")
data<-predict(preproc,PimaIndiansDiabetes2[-9])
data$Class<-PimaIndiansDiabetes2[,9]
然后对填补后的数据集进行训练:
#贝叶斯网络建模
library(bnlearn)
#数据离散化
data2<-discretize(data[-9],method="quantile")
data2$class<-data[,9]
#爬山算法学习结构
bayesnet<-hc(data2)
#显示网络图
plot(bayesnet)
#修改网络图中的箭头指向
bayesnet<-set.arc(bayesnet,"age","pregnant")
plot(bayesnet)
拓扑结构如图:
然后利用bn.fit( )函数进行参数学习:
#参数学习
fitted<-bn.fit(bayesnet,data2,method="mle")
#训练样本预测并提取混淆矩阵
pre<-predict(fitted,data=data2,node="class")
#进行条件推断
cpquery(fitted,(class=="pos"),(age=="(36,81]"&mass=="(34.8,67.1]"))
[1] 0.5934619
由条件推断结果可知在年龄为36~81岁之间以及mass为34.8~67.1区间的得糖尿病的概率为0.5934619。
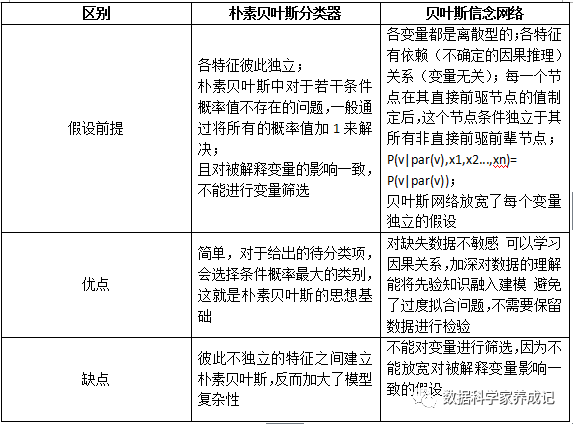
朴素贝叶斯与贝叶斯网络的区别
不想写了,一图流:
总结
文末放一张昨晚小编做贝叶斯分类题的草稿哈哈哈:


公众号后台回复关键字即可学习
回复 R R语言快速入门免费视频
回复 统计 统计方法及其在R中的实现
回复 用户画像 民生银行客户画像搭建与应用
回复 大数据 大数据系列免费视频教程
回复 可视化 利用R语言做数据可视化
回复 数据挖掘 数据挖掘算法原理解释与应用
回复 机器学习 R&Python机器学习入门