想要算一算Wasserstein距离?这里有一份PyTorch实战
选自dfdazac
作者:Daniel Daza
机器之心编译
最优传输理论及 Wasserstein 距离是很多读者都希望了解的基础,本文主要通过简单案例展示了它们的基本思想,并通过 PyTorch 介绍如何实战 W 距离。
机器学习中的许多问题都涉及到令两个分布尽可能接近的思想,例如在 GAN 中令生成器分布接近判别器分布就能伪造出逼真的图像。但是 KL 散度等分布的度量方法有很多局限性,本文则介绍了 Wasserstein 距离及 Sinkhorn 迭代方法,它们 GAN 及众多任务上都展示了杰出的性能。
在简单的情况下,我们假设从未知数据分布 p(x) 中观测到一些随机变量 x(例如,猫的图片),我们想要找到一个模型 q(x|θ)(例如一个神经网络)能作为 p(x) 的一个很好的近似。如果 p 和 q 的分布很相近,那么就表明我们的模型已经学习到如何识别猫。
因为 KL 散度可以度量两个分布的距离,所以只需要最小化 KL(q‖p) 就可以了。可以证明,最小化 KL(q‖p) 等价于最小化一个负对数似然,这样的做法在我们训练一个分类器时很常见。例如,对于变分自编码器来说,我们希望后验分布能够接近于某种先验分布,这也是我们通过最小化它们之间的 KL 散度来实现的。
尽管 KL 散度有很广泛的应用,在某些情况下,KL 散度则会失效。不妨考虑一下如下图所示的离散分布:
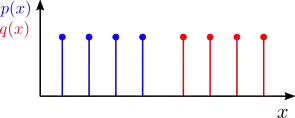
KL 散度假设这两个分布共享相同的支撑集(也就是说,它们被定义在同一个点集上)。因此,我们不能为上面的例子计算 KL 散度。由于这一个限制和其他计算方面的因素促使研究人员寻找一种更适合于计算两个分布之间差异的方法。
在本文中,作者将:
简单介绍最优传输问题
将 Sinkhorn 迭代描述为对解求近似
使用 PyTorch 计算 Sinkhorn 距离
描述用于计算 mini-batch 之间的距离的对该实现的扩展
移动概率质量函数
我们不妨把离散的概率分布想象成空间中分散的点的质量。我们可以观测这些带质量的点从一个分布移动到另一个分布需要做多少功,如下图所示:

接着,我们可以定义另一个度量标准,用以衡量移动做所有点所需要做的功。要想将这个直观的概念形式化定义下来,首先,我们可以通过引入一个耦合矩阵 P(coupling matrix),它表示要从 p(x) 支撑集中的一个点上到 q(x) 支撑集中的一个点需要分配多少概率质量。对于均匀分布,我们规定每个点都具有 1/4 的概率质量。如果我们将本例支撑集中的点从左到右排列,我们可以将上述的耦合矩阵写作:
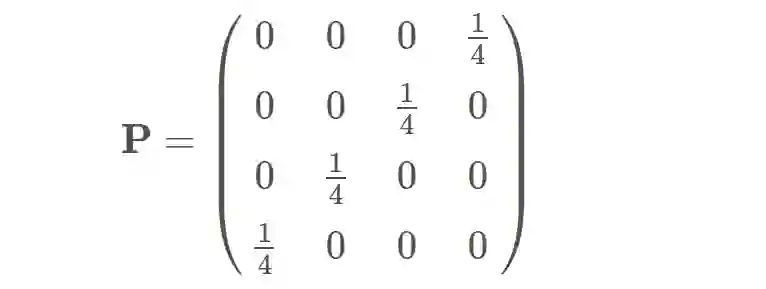
也就是说,p(x) 支撑集中点 1 的质量被分配给了 q(x) 支撑集中的点 4,p(x) 支撑集中点 2 的质量被分配给了 q(x) 支撑集中的点 3,以此类推,如上图中的箭头所示。
为了算出质量分配的过程需要做多少功,我们将引入第二个矩阵:距离矩阵。该矩阵中的每个元素 C_ij 表示将 p(x) 支撑集中的点移动到 q(x) 支撑集中的点上的成本。点与点之间的欧几里得距离是定义这种成本的一种方式,它也被称为「ground distance」。如果我们假设 p(x) 的支撑集和 q(x) 的支撑集分别为 {1,2,3,4} 和 {5,6,7,8},成本矩阵即为:

根据上述定义,总的成本可以通过 P 和 C 之间的 Frobenius 内积来计算:
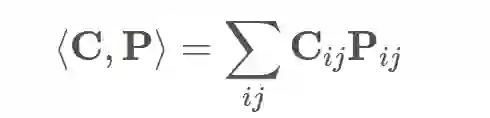
你可能已经注意到了,实际上有很多种方法可以把点从一个支撑集移动到另一个支撑集中,每一种方式都会得到不同的成本。上面给出的只是一个示例,但是我们感兴趣的是最终能够让成本较小的分配方式。这就是两个离散分布之间的「最优传输」问题,该问题的解是所有耦合矩阵上的最低成本 L_C。
由于不是所有矩阵都是有效的耦合矩阵,最后一个条件会引入了一个约束。对于一个耦合矩阵来说,其所有列都必须要加到带有 q(x) 概率质量的向量中。在本例中,该向量包含 4 个值为 1/4 的元素。更一般地,我们可以将两个向量分别记为 a 和 b,因此最有运输问题可以被写作:
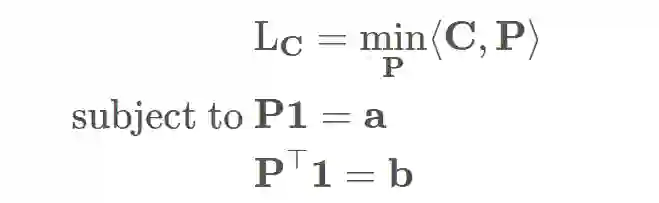
当距离矩阵基于一个有效的距离函数构建时,最小成本即为我们所说的「Wasserstein 距离」。
关于该问题的解以及将其扩展到连续概率分布中还有大量问题需要解决。如果想要获取更正式、更容易理解的解释,读者可以参阅 Gabriel Peyré 和 Marco Cuturi 编写的「Computational Optimal Transport」一书,此书也是本文写作的主要参考来源之一。
这里的基本设定是,我们已经把求两个分布之间距离的问题定义为求最优耦合矩阵的问题。事实证明,我们可以通过一个小的修改让我们以迭代和可微分的方式解决这个问题,这将让我们可以很好地使用深度学习自动微分机制完成该工作。
熵正则化和 Sinkhorn 迭代
首先,我们将一个矩阵的熵定义如下:
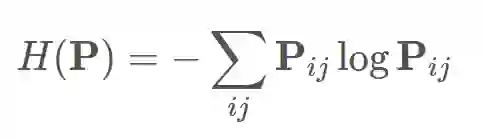
正如信息论中概率分布的熵一样,一个熵较低的矩阵将会更稀疏,它的大部分非零值集中在几个点周围。相反,一个具有高熵的矩阵将会更平滑,其最大熵是在均匀分布的情况下获得的。我们可以将正则化系数 ε 引入最优传输问题,从而得到更平滑的耦合矩阵:
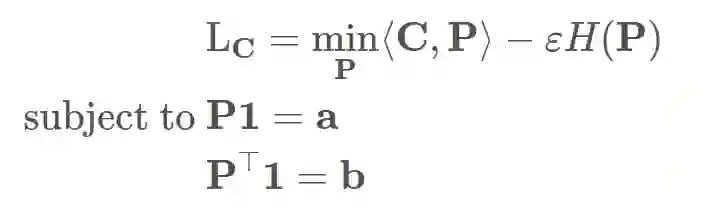
通过增大 ε,最终得到的耦合矩阵将会变得更加平滑;而当 ε 趋近于零时,耦合矩阵会更加稀疏,同时最终的解会更加趋近于原始最优运输问题。
通过引入这种熵正则化,该问题变成了一个凸优化问题,并且可 以通过使用「Sinkhorn iteration」求解。解可以被写作 P=diag(u)Kdiag(v),在迭代过程中交替更新 u 和 v:
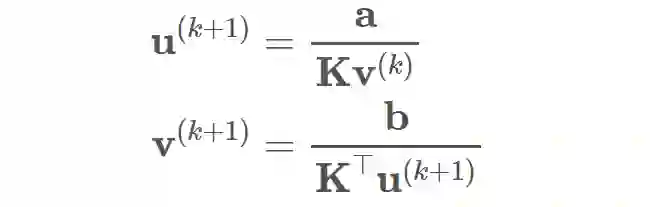
其中 K 是一个用 C 计算的核矩阵(kernel matrix)。由于这些迭代过程是在对原始问题的正则化版本求解,因此对应产生的 Wasserstein 距离有时被称为 Sinkhorn 距离。该迭代过程会形成一个线性操作的序列,因此对于深度学习模型,通过这些迭代进行反向传播是非常简单的。
通过 PyTorch 实现 Sinkhorn 迭代
为了提升 Sinkhorn 迭代的收敛性和稳定性,还可以加入其它的步骤。我们可以在 GitHub 上找到 Gabriel Peyre 完成的详细实现。
项目链接:https://github.com/gpeyre/SinkhornAutoDiff。
让我们先用一个简单的例子来测试一下,现在我们将研究二维空间(而不是上面的一维空间)中的离散均匀分布。在这种情况下,我们将在平面上移动概率质量。让我们首先定义两个简单的分布:
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
np.random.seed(42)
n_points = 5
a = np.array([[i, 0] for i in range(n_points)])
b = np.array([[i, 1] for i in range(n_points)])
plt.figure(figsize=(6, 3))
plt.scatter(a[:, 0], a[:, 1], label='supp($p(x)$)')
plt.scatter(b[:, 0], b[:, 1], label='supp($q(x)$)')
plt.legend();
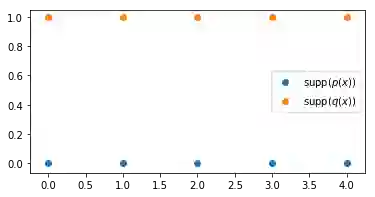
我们很容易看出,最优传输对应于将 p(x) 支撑集中的每个点分配到 q(x) 支撑集上的点。对于所有的点来说,距离都是 1,同时由于分布是均匀的,每点移动的概率质量是 1/5。因此,Wasserstein 距离是 5×1/5= 1。现在我们用 Sinkhorn 迭代来计算这个距离:
import torch
from layers import SinkhornDistance
x = torch.tensor(a, dtype=torch.float)
y = torch.tensor(b, dtype=torch.float)
sinkhorn = SinkhornDistance(eps=0.1, max_iter=100, reduction=None)
dist, P, C = sinkhorn(x, y)
print("Sinkhorn distance: {:.3f}".format(dist.item()))
————————————————————————————————————————————————
Sinkhorn distance: 1.000
结果正如我们所计算的那样,距离为 1。现在,让我们查看一下「Sinkhorn( )」方法返回的矩阵,其中 P 是计算出的耦合矩阵,C 是距离矩阵。距离矩阵如下图所示:
plt.imshow(C)
plt.title('Distance matrix')
plt.colorbar();
plt.imshow(C)plt.title('Distance matrix')plt.colorbar();
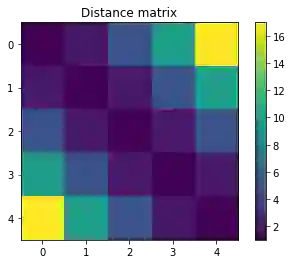
元素「C[0, 0]」说明了将(0,0)点的质量移动到(0,1)所需要的成本 1 是如何产生的。在该行的另一端,元素「C[0, 4]」包含了将点(0,0)的质量移动到点(4,1)所需要的成本,这个成本是整个矩阵中最大的:
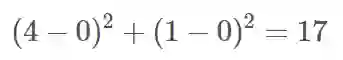
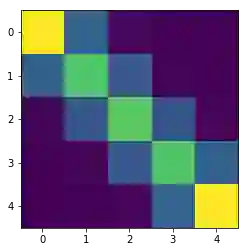
由于我们为距离矩阵使用的是平方后的 ℓ2 范数,计算结果如上所示。现在,让我们看看计算出的耦合矩阵吧:
plt.imshow(P)
plt.title('Coupling matrix');
plt.imshow(P)plt.title('Coupling matrix');

该图很好地向我们展示了算法是如何有效地发现最优耦合,它与我们前面确定的耦合矩阵是相同的。到目前为止,我们使用了 0.1 的正则化系数。如果将该值增加到 1 会怎样?
sinkhorn = SinkhornDistance(eps=1, max_iter=100, reduction=None)
dist, P, C = sinkhorn(x, y)
print("Sinkhorn distance: {:.3f}".format(dist.item()))
plt.imshow(P);
————————————————————————————————————————————————
Sinkhorn distance: 1.408
正如我们前面讨论过的,加大 ε 有增大耦合矩阵熵的作用。接下来,我们看看 P 是如何变得更加平滑的。但是,这样做也会为计算出的距离带来一个不好的影响,导致对 Wasserstein 距离的近似效果变差。
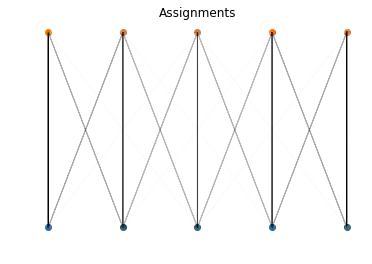
可视化支撑集的空间分配也很有意思:
def show_assignments(a, b, P):
norm_P = P/P.max()
for i in range(a.shape[0]):
for j in range(b.shape[0]):
plt.arrow(a[i, 0], a[i, 1], b[j, 0]-a[i, 0], b[j, 1]-a[i, 1],
alpha=norm_P[i,j].item())
plt.title('Assignments')
plt.scatter(a[:, 0], a[:, 1])
plt.scatter(b[:, 0], b[:, 1])
plt.axis('off')
show_assignments(a, b, P)
让我们在一个更有趣的分布(Moons 数据集)上完成这项工作。
from sklearn.datasets import make_moons
X, Y = make_moons(n_samples = 30)
a = X[Y==0]
b = X[Y==1]
x = torch.tensor(a, dtype=torch.float)
y = torch.tensor(b, dtype=torch.float)
sinkhorn = SinkhornDistance(eps=0.1, max_iter=100, reduction=None)
dist, P, C = sinkhorn(x, y)
print("Sinkhorn distance: {:.3f}".format(dist.item()))
show_assignments(a, b, P)
——————————————————————————————————————————
Sinkhorn distance: 1.714

Mini-batch 上的 Sinkhorn 距离
在深度学习中,我们通常对使用 mini-batch 来加速计算十分感兴趣。我们也可以通过使用额外的批处理维度修改 Sinkhorn 迭代来满足该设定。将此更改添加到具体实现中后,我们可以在一个 mini-batch 中计算多个分布的 Sinkhorn 距离。下面我们将通过另一个容易被验证的例子说明这一点。
代码:https://github.com/dfdazac/wassdistance/blob/master/layers.py
我们将计算包含 5 个支撑点的 4 对均匀分布的 Sinkhorn 距离,它们垂直地被 1(如上所示)、2、3 和 4 个单元分隔开。这样,它们之间的 Wasserstein 距离将分别为 1、4、9 和 16。
n = 5
batch_size = 4
a = np.array([[[i, 0] for i in range(n)] for b in range(batch_size)])
b = np.array([[[i, b + 1] for i in range(n)] for b in range(batch_size)])
# Wrap with torch tensors
x = torch.tensor(a, dtype=torch.float)
y = torch.tensor(b, dtype=torch.float)
sinkhorn = SinkhornDistance(eps=0.1, max_iter=100, reduction=None)
dist, P, C = sinkhorn(x, y)
print("Sinkhorn distances: ", dist)
——————————————————————————————————————————
Sinkhorn distances: tensor([ 1.0001, 4.0001, 9.0000, 16.0000])
这样做确实有效!同时,也请注意,现在 P 和 C 为 3 维张量,它包含 mini-batch 中每对分布的耦合矩阵和距离矩阵:
print('P.shape = {}'.format(P.shape))
print('C.shape = {}'.format(C.shape))
——————————————————————————————————————————
P.shape = torch.Size([4, 5, 5])
C.shape = torch.Size([4, 5, 5])
结语
分布之间的 Wasserstein 距离及其通过 Sinkhorn 迭代实现的计算方法为我们带来了许多可能性。该框架不仅提供了对 KL 散度等距离的替代方法,而且在建模过程中提供了更大的灵活性,我们不再被迫要选择特定的参数分布。这些迭代过程可以在 GPU 上高效地执行,并且是完全可微分的,这使得它对于深度学习来说是一个很好的选择。这些优点在机器学习领域的最新研究中得到了充分的利用(如自编码器和距离嵌入),使其在该领域的应用前景更加广阔。

原文链接:https://dfdazac.github.io/sinkhorn.html
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com



