深度 | 变分自编码器VAE面临的挑战与发展方向
选自akosiorek
机器之心编译
参与:刘天赐、李泽南
变分自编码器(VAE)与生成对抗网络(GAN)一样,是无监督学习最具前景的方法之一。本文中,牛津大学统计系在读博士 Adam Kosiorek 从原理上向我们介绍了 VAE 目前面临的挑战。同时,文中也提出了对于该方法的几种改进方向。
隐变量模型
假设你希望通过一个定义在 x∈RD 上的概率分布来对整个世界建模,其中 p(x)表示 x 可能处于的状态。这个世界可能非常复杂,我们无法知道 p(x)的具体形式。为了解决这个问题,我们引入另一个变量 z∈Rd 来描述 x 的背景信息。例如 x 是一个图像,那么 z 就可以记录关于图像中可见物体的出现、数量、类型,以及画面的背景和光影条件的信息。这个新的变量使得我们可以将 p(x)表示为一个无限混合模型。

这是一个混合模型,因为对于 z 的任意可能取值,都引入另一个条件分布,并通过 z 的概率进行加权,最终得到 p(x)。
在这样的设定下,「给定 x 的观测值,隐变量 z 是什么」就成了一个非常有趣的问题。也就是说,我们希望知道后验分布 p(z∣x)。但是,z 和 x 之间可以呈现高度的非线性关系(比如,由一个多层神经网络实现),而且,D——我们观测值的维度,和 d——隐变量的维度,也可能非常大。由于边缘分布和后验分布都需要对(1)式积分求值,我们认为它们都是无法计算的。
我们可以通过蒙特卡罗抽样,根据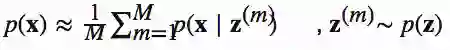
在训练一个概率模型的时候,我们可以使用参数分布 - 它的参数由一个参数为θ∈Θ的神经网络来确定。现在,我们就可以使用极大似然估计来学习得到这些参数。

这里的问题是,我们无法最大化(1)式,因为我们无法估计它。为了解决这个问题,我们可以求助于重要抽样(importance sampling)。当我们需要对原始(名义分布)概率密度分布(pdf)估算一个期望值时,IS 使得我们可以从另一个不同的概率分布(建议分布)中抽样,然后将这些样本对名义分布求期望。用 qϕ(z∣x) 表示我们的建议分布 - 其中的参数由参数为 ϕ∈Φ的神经网络确定。我们可以得到:
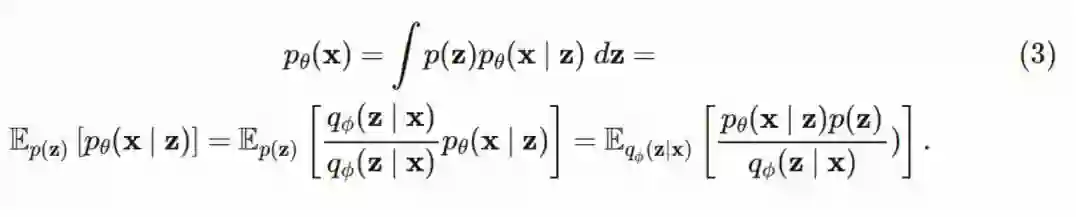
根据重要性抽样的文献可知,最优的建议分布,与名义分布乘以某个函数成比例,其中这个函数的期望是我们希望估计的。在我们的设定下,「某个函数」就是 p(x|z)。根据贝叶斯定理,p(z∣x)=p(x∣z)p(z)/p(x),我们可以看到,最优建议分布与后验分布成比例,显然,后验分布无法求解。
变分自编码器的诞生
幸运的是,事实上我们可以一箭双雕:通过一个学习到的建议分布来近似估计后验分布,我们可以有效的得到边缘分布 pθ(x) 的估计。在这里,我们无意间得到了一个自编码的设定。为了学习我们的模型,我们需要:
pθ(x,z) - 生成模型,其中包含:
pθ(x∣z) - 一个概率形式的解码器,以及
p(z) - 一个定义在隐变量上的先验分布
qϕ(z∣x) - 一个概率形式的编码器
为了近似估计后验分布,我们可以利用建议分布和后验分布之间的 KL 散度(可以理解为两个概率分布之间的距离),而且我们可以最小化这个结果。
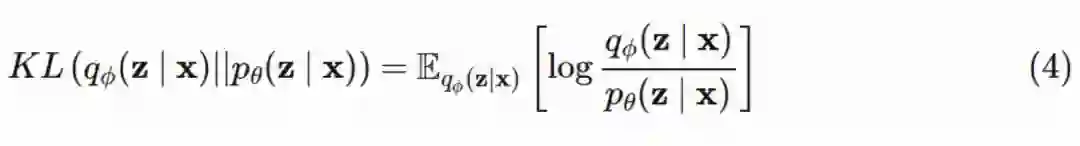
这个时候,我们面临的新问题就是:为了计算 KL 散度,我们需要知道后验分布。并非没有可能,只要利用一点点代数运算,我们就能得到可以计算的目标函数。
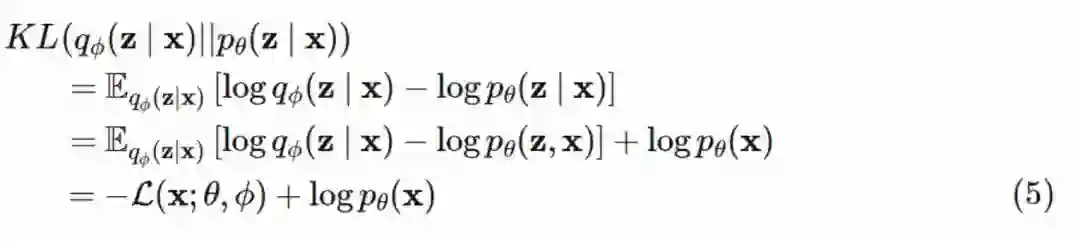
我在第二行展开了对数项,在第三行使用了贝叶斯定理以及 pθ(x) 和 z 是独立的事实。最后一行中的 L(x;θ,ϕ) 是对数概率分布 pθ(x) 的下界 - 即通常所说的证据下界(ELBO)。我们通过整理可以得到:
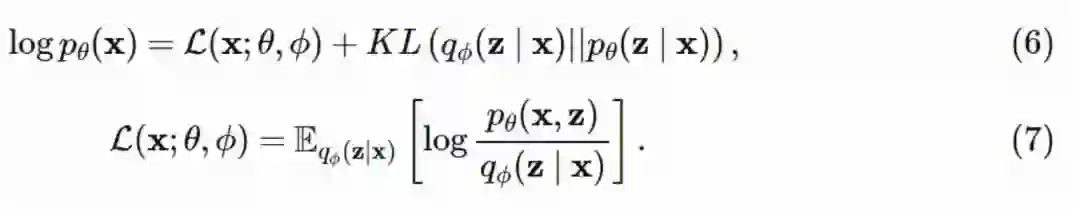
只需要一个从建议分布中抽得的样本,我们就可以得到近似估计:
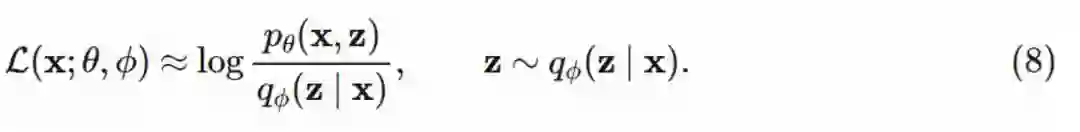
我们通过寻找最大化 ELBO 的ϕ和θ(通常使用随机梯度下降)来训练模型:
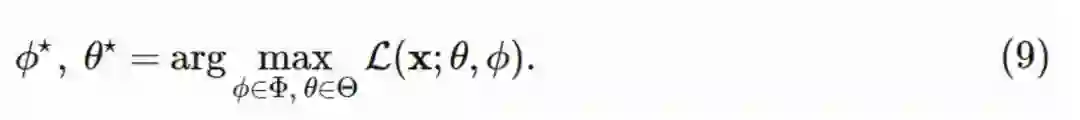
通过最大化 ELBO,我们或(1)最大化边缘分布,或(2)最小化 KL 散度,或同时完成。需要注意,ELBO 的近似估计是 f(x)=1、重要性权重为 w(x)=pθ(x,z)qϕ(z∣x) 的重要性抽样的期望的对数形式。
这个估计量有什么问题?
如果你足够仔细的看重要性抽样,就能发现,对建议分布的支撑应该比对名义分布的支撑更广泛——应该同时避免估计量方差无限大和数值的不稳定性。在这里,最好是来优化 KL(p∣∣q) 的倒数——因为它有模式平均性质,而不是优化 KL(q∣∣p),来试图通过模式 q 去匹配找到一个最好的模式 p。这意味着我们需要从真实的后验分布中进行抽样,而这是很困难的。作为替代,我们可以使用 ELBO 的 IS 估计,作为重要性加权自编码器(IWAE)。这里的想法很简单:我们从建议分布中抽取 k 个样本,并从中计算出平均概率比,这里的每一个样本也叫「粒子」。
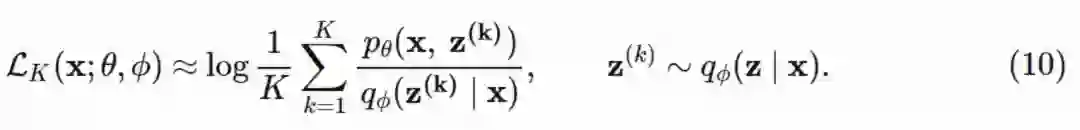
已经证明,这个估计量是在优化修正后的 KL 散度 KL(qIS∣∣pIS),其中 qIS 和 pIS 的定义分别是:
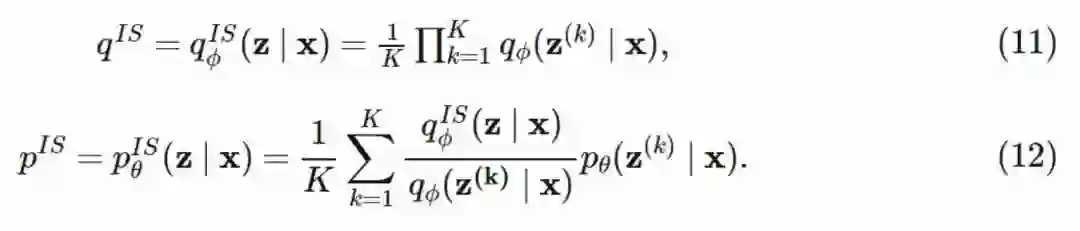
尽管和原始分布看似接近,但 qIS 和 pIS 允许 q 和 p 中存在预想以外的小的变动。原始论文中证明,优化这个下界可以得到更好的生成模型。同时它也给出了一个近似后验分布 q 的熵更大的估计(更宽,更离散),并成功的超越了原始 KL 散度的模式匹配方法。还有一个有趣的结果,如果我们令粒子 K 的数量趋于无穷,我们就可以不需要推断模型 q。

IWAE(第一行)和 VAE(第二行)中 z 的后验分布。图像从 IWAE 论文中复现得到。
IWAE 有什么问题?
重要性加权 ELBO,或 IWAE,推广了原始的 ELBO:对于 K=1,我们有 LK=L1=L。同时有 logp(x)≥Ln+1≥Ln≥L1。换言之,我们用来估计 LK 的粒子越多,它的结果就会越接近数据真实对数概率分布——即「界限越紧」。这意味着和原始 ELBO 的梯度相比,通过对 IWAE 求微分得到的梯度估计量可以帮助我们找到一个更好的梯度方向。除此之外,随着 K 的增加,梯度估计量的方差会相应收缩。
对于生成模型这些点非常好,但面对建议分布的时候,就会出现问题。随着 K 的增大,建议分布中参数的梯度的大小会趋于 0,而且比方差收敛得还要快。
令Δ(ϕ) 表示我们优化的目标函数(即 ELBO)在ϕ上的梯度的小批量估计。如果定义参数更新的信号-噪声比(SNR)如下:

其中 E 和 V 分别表示期望和方差。可以看出对于 pθ,SNR 随着 K 增加而增加,但对于 qϕ,SNR 随着 K 增加而减小。这里的结论很简单:我们使用的粒子越多,我们的推断模型效果就会越差。如果我们关心的是表示学习,我们就会遇到问题了。
更好的估计量
正如我们在最近的论文《Tighter Variational Bounds are Not Necessarily Better》中证明的,我们可以得到比 IWAE 更好的结果。思路是在推断和生成模型中使用不同的目标,通过这种方法,我们可以保证两个目标中都得到小方差非零梯度,最终得到更好的模型。
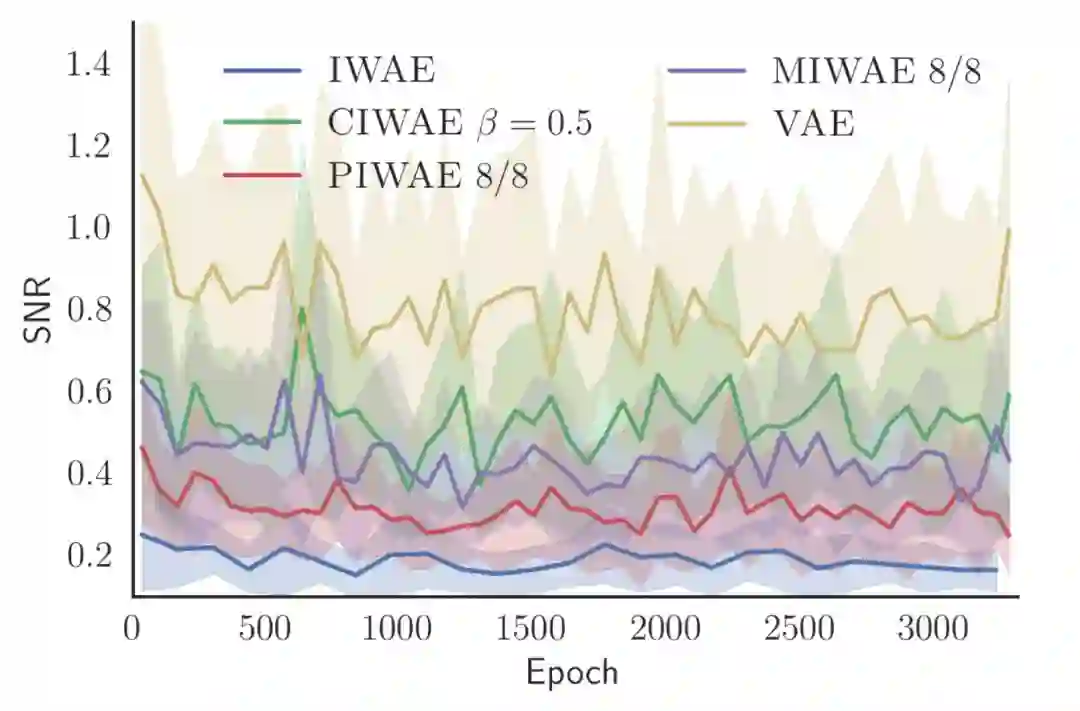
不同的训练目标在训练时期中信号-噪声比
在上图中,我们比较了建议分布 qϕ的参数ϕz 在更新中的 SNR。SNR 最高的 VAE 通过最优化 L1 来训练。SNR 最低的 IWAE 则通过最优化 L64。中间的三条曲线使用的是不同的组合:生成模型中使用的 L64,推断模型中使用的则是 L8 或 L1。在当前指标下,它们效果虽然没有 VAE 好,但训练出的建议分布和生成模型都比使用 VAE 或 IWAE 得到的好。
这里有一个令人惊讶的副作用:使用我们新的估计量训练的模型比使用 IWAE 本身训练的模型达到了更高的 L64 界限。为什么会这样?通过研究有效样本量(ESS)和数据的边缘概率分布的对数,似乎是最优化 L1,导致了性质最好的建议分布但是性质最差的生成模型。如果我们将一个好的建议分布和一个可以得出好的生成模型的目标结合在一起,我们应该可以得到这个目标的一个方差更小的估计,甚至因此可以得到更好的模型。请在这里查看我们论文的详情。
论文:Tighter Variational Bounds are Not Necessarily Better

论文地址:https://arxiv.org/abs/1802.04537
摘要:我们同时在理论和经验上证明,使用更紧的信息下界(ELBO)可能并不利于通过减少梯度估计量的信号-噪声比来学习推断网络的过程。我们的结果对目前广为应用的暗含假设:「更紧的 ELBO 是联立模型学习和推断摊销模式中更合适的变分目标」提出了质疑。根据我们的研究,我们提出了三个新的算法:偏重要性加权自编码器(PIWAE)、多层重要性加权自编码器(MIWAE)以及联合重要性加权自编码器(CIWAE);在这三个算法中,标准的重要性自编码器(IWAE)都可以作为一个特殊情况。我们证明了这三个自编码器都可以在 IWAE 的基础上取得效果提升——即使我们使用的是 IWAE 中的目标来测试效果。进一步来说,和 IWAE 相比,PIWAE 可以同时提升推断网络和生成网络的效果。

原文链接:http://akosiorek.github.io/ml/2018/03/14/what_is_wrong_with_vaes.html
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:editor@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com




