【前沿】NIPS2017贝叶斯生成对抗网络TensorFlow实现(附GAN资料下载)
导读
今年五月份康奈尔大学的 Andrew Gordon Wilson 和 Permutation Venture 的 Yunus Saatchi 提出了一个贝叶斯生成对抗网络(Bayesian GAN),结合贝叶斯和对抗生成网络,提出了一个实用的贝叶斯公式框架,用GAN来进行无监督学习和半监督式学习。论文《Bayesian GAN》也被2017年机器学习顶级会议 NIPS 接受,今天Andrew Gordon Wilson在Twitter上发布消息开源了这篇论文的TensorFlow实现,并且Google GAN之父 Ian Goodfellow 转发这条推文,让我们来看下。

摘要
生成式对抗网络(GANs)能在不知不觉中学习图像、声音和数据中的丰富分布。这些分布通常因为具有明确的相似性,所以很难去建模。在这篇论文中,我们提出了一个实用的贝叶斯公式,通过使用GAN来进行无监督学习和半监督式学习。在这一框架之下,使用动态的梯度汉密尔顿蒙特卡洛(Hamiltonian Monte Carlo)来将生成网络和判别网络中的权重最大化。提出的方法可以非常直接的获得最后的结果,并且在不需要任何标准的干预,比如特征匹配或者mini-batch discrimination的情况下,都获得了良好的表现。通过对生成器中的参数部署一个具有表达性的后验机制。贝叶斯生成式对抗网络能够避免模式碰撞,产生可判断的、多样化的候选样本,并且提供在既有的一些基准测试上,能够提供最好的半监督学习量化结果,比如,SVHN, CelebA 和 CIFAR-10,其效果远远超过 DCGAN, Wasserstein GANs 和 DCGAN 等等。
TensorFlow实现的贝叶斯生成对抗网络
Contents
简介
python 依赖包
训练参数
使用方法
安装
合成数据
例子: MNIST, CIFAR10, CelebA, SVHN
自定义数据
简介
贝叶斯生成对抗网络中我们提出了使用条件后验分布来建模生成器和判别器的权重参数,随后使用了动态的梯度汉密尔顿蒙特卡洛(Hamiltonian Monte Carlo)来将生成网络和判别网络中的权重最大化。贝叶斯方法用在生成对抗网络主要有一下几个特性:(1),能够提供很好的半监督学习量化结果。(2),对效果的影响比较小。(3), 可以通过估计概率GAN的边际相似性;(4),它不容易遭受模型失效(mode collapse)的风险;(5)一个包含针对数据互补的多生成和判别模型,可以形成一个概率集成(ensemble)。
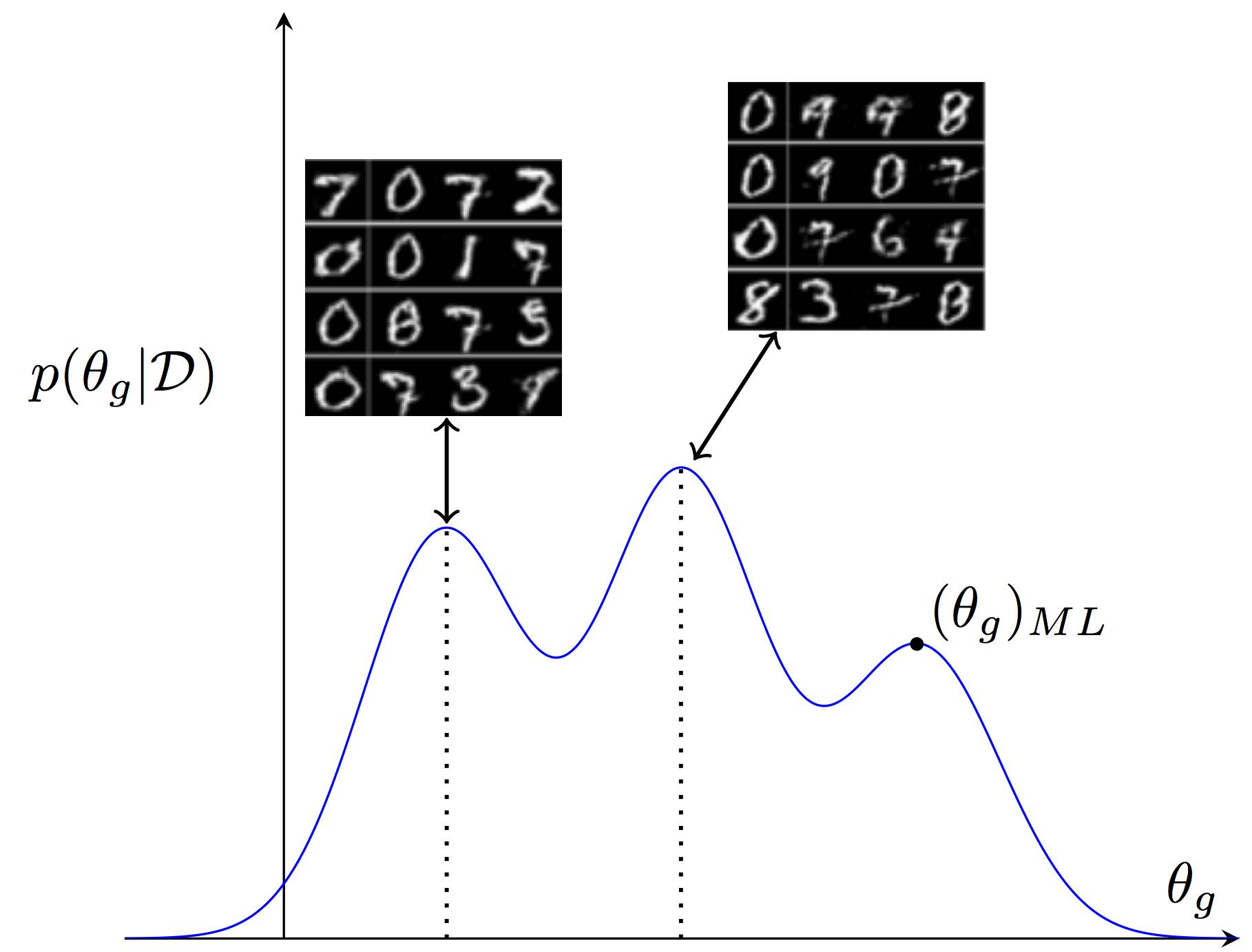
我们展示了在生成器参数上的多模后验。每种参数设定都和不同的数据生成假设相对应。上图显示了对应两种不同手写风格的参数设定而产生的样本。这个贝叶斯生成对抗网络保留了在参数上的全概率分布。相反,标准的生成对抗网络使用点估计(类似于单个最大似然估计)来表示这个全概率分布,这样会丢失一些潜在的并重要的数据解释。
python 依赖包
这个代码包含以下依赖包 (版本号非常重要):
python 2.7
tensorflow==1.0.0
在Linux上安装tensorflow 1.0.0可以参考官方指南 https://www.tensorflow.org/versions/r1.0/install/.
scikit-learn==0.17.1 你可以使用以下命令来安装 scikit-learn 0.17.1
`pip install scikit-learn==0.17.1此外你可以创建一个conda的虚拟Python环境并使用我们提供的, environment.yml 文件类配置`conda env create -f environment.yml -n bgan用下面命令来启动环境`source activate bgan` ## 训练参数
bayesian_gan_hmc.py 包含以下训练选项.
--out_dir: 输出目录--n_save: 每次保存的样本和参数的数量n_save是迭代次数; 默认为 100--z_dim: 生成器中z向量的维度 ;默认为100--data_path: 数据目录; 这个路径是必须的--dataset: 数据集可以是mnist,cifar,svhnorceleb; 默认为mnist--gen_observed: 被生成器“观察”到的数据 ; 这会影响到噪声离散的尺度和先验,默认为1000--batch_size: 一次训练的批量数 ;默认 64--prior_std: 权重先验的标准差;默认为1--numz: 与论文中的J参数一样; 参数z需要整合的样本数; 默认 1--num_mcmc: 与论文中的M参数一样; 每个zde 蒙特卡洛 NN权重样本; 默认是1--lr: Adam 优化器的学习率; 默认 0.0002--optimizer: 优化方法:adam(tf.train.AdamOptimizer) 或者sgd(tf.train.MomentumOptimizer); 默认使用adam--semi_supervised: 进行半监督学习--N: 进行半监督学习的标注样本数--train_iter: 训练迭代次数; 默认 50000--save_samples: 训练中保存生成样本--save_weights: 训练中保存生成权重--random_seed: 随机种子;注意如果使用了GPU,因为这个操作结果不能做到%100复现
你可以使用--wasserstein来运行WGANs 或者使用 --ml_ensemble <num_dcgans>来训练多个 DCGANs 的集成. 此外你还可以使用-ml_ensemble 1来训练DCGAN
使用方法
安装
安装要求的依赖集
克隆代码仓库
合成数据
为了能再论文中提到的合成数据上运行你可以使用T bgan_synth 脚本. 比如,下面的命令训练 贝叶斯生成对抗网络(with D=100 and d=10)迭代 5000 词并将结果保存在 <results_path>.
`./bgan_synth.py --x_dim 100 --z_dim 10 --numz 10 --out \<results_path\>`在此数据集上运行 ML GAN可以运行
`./bgan_synth.py --x_dim 100 --z_dim 10 --numz 1 --out \<results_path\>bgan_synth有--save_weights,--out_dir,--z_dim,--numz,--wasserstein,--train_iter以及--x_dim这些参数.x_dim控制观测数据的维度 (也就是论文中的x` ).
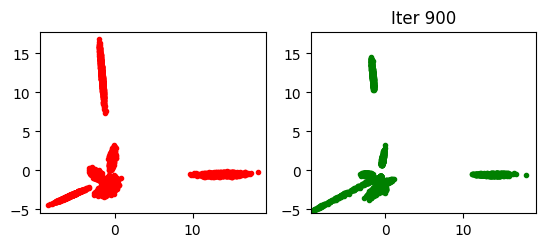
如果你运行了以上两条命令后你会看到每100次迭代的输出结果 <results_path>. 举例来说贝叶斯生成对抗网络在第900次迭代的结果如下图:
对比来说标准 GAN (对应于numz=1, 使用最大似然估计) 产生的结果如下:
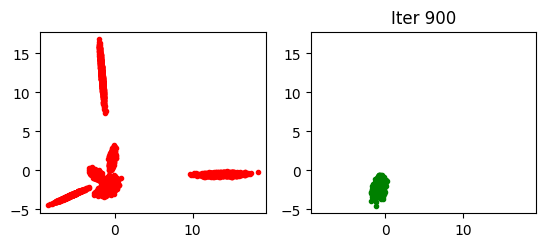
上面的图展示了标准GAN容易遇到模型失效(mode collapse)而我们提出的 Bayesian GAN则可以避免这种情况。
为了进一步探究合成的数据, 同时生成JS散度 ,你可以运行 synth.ipynb.
MNIST, CIFAR10, CelebA, SVHN
bayesian_gan_hmc script allows to train the model on standard and custom datasets. Below we describe the usage of this script.
数据准备
为了重现在 MNIST, CIFAR10, CelebA 和 SVHN 数据集上的实验,你需要使用正确的--data_path来准备数据.
对于 MNIST你不需要预处理数据,可以指定任意的
--data_path;对于 CIFAR10 你需要从https://www.cs.toronto.edu/kriz/cifar.htmlPython处理的数据please下载并解压出适合 download ;
对于 SVHN数据, 从http://ufldl.stanford.edu/housenumbers/下载
train_32x32.mat和test_32x32.mat文件对于CelebA数据,你需要首先安装 openCV. 可以从这个链接来下载数据http://mmlab.ie.cuhk.edu.hk/projects/CelebA.html. 首先创建一个包含“ Anno
和 img_align_celeba 子目录的目录celebA folder ”Anno ‘ 必须包含list_attr_celeba.txt,而img_align_celeba必须包含.jpg文件. 你还需要使用datasets/crop_faces.py脚本来裁剪图片, 其中包含参数--data_path <path>来指定’celebA‘的目录。
无监督训练
你可以通过运行不包含--semi 参数的bayesian_gan_hmc 脚本来训练无监督版本的训练,. 比如使用:
`./bayesian_gan_hmc.py --data_path \<data_path\> --dataset svhn --numz 1 --num_mcmc 10 --out_dir
\<results_path\> --train_iter 75000 --save_samples --n_save 100在SVHN 数据集上训练模型. 这条命令将迭代75000次并且每100次迭代保存一次样本。 这里的必须指向结果产生的目录.



半监督训练
你可以用脚本带--semi 选项的bayesian_gan_hmc 脚本来训练半监督版本的模型。 用 -N 参数来设定需要训练的标注样本数目。比如运行:
`./bayesian_gan_hmc.py --data_path \<data_path\> --dataset cifar --numz 1 --num_mcmc 10
--out_dir \<results_path\> --train_iter 75000 --N 4000 --semi --lr 0.00005在 CIFAR10 数据集上使用 4000 标注样本来训练模型. 这条命令将迭代75000次训练模型,并将结果保存在` 文件夹中.
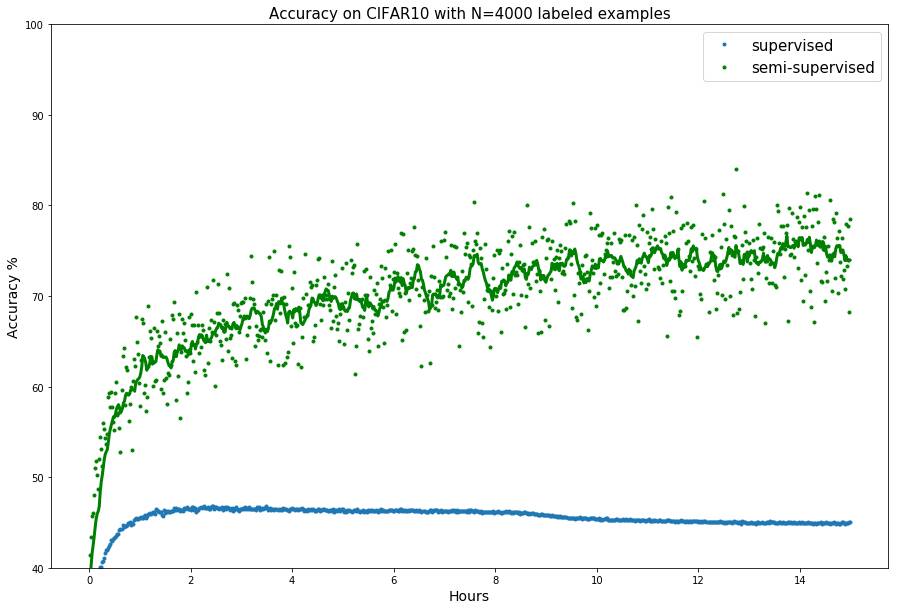
为了在MNIST数据集上使用200个标注样本训练模型你可以使用以下命令:
`./bayesian_gan_hmc.py --data_path \<data_path\>/ --dataset mnist --numz 5 --num_mcmc 5
--out_dir \<results_path\> --train_iter 30000 -N 200 --semi --lr 0.001`
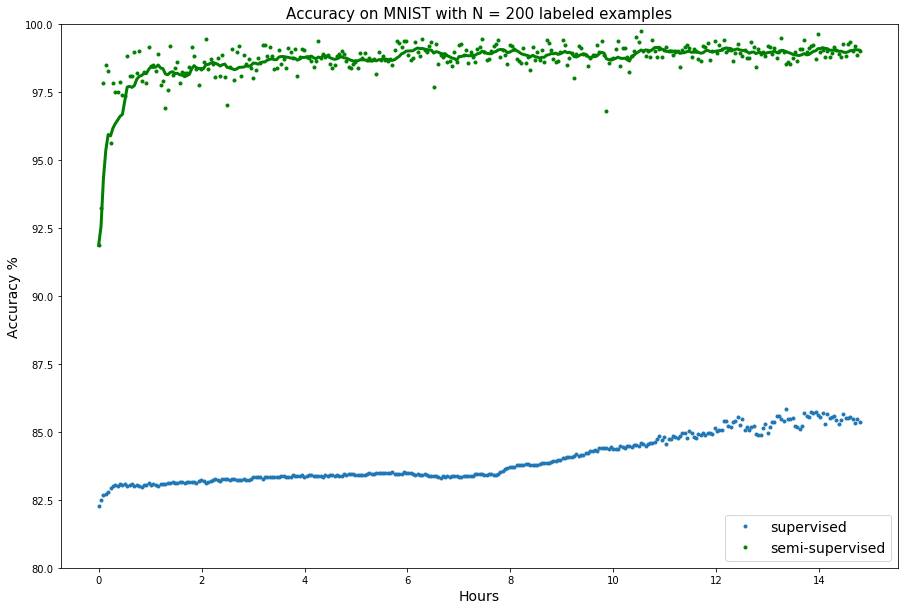
自定义数据
为了在自定义的数据集上训练模型,你需要为每一个分类定义特定的接口。比如你想在 digits(http://scikit-learn.org/stable/modules/generated/sklearn.datasets.load_digits.html) 数据集上训练模型.,这个数据集包含8x8的数字图片。假设数据被分别存储在x_tr.npy, y_tr.npy, x_te.npy and y_te.npy 文件中,我们认为 x_tr.npy and x_te.npy 的大小为 (?, 8, 8, 1). 随后我们可以在bgan_util.py 中定义针对这个数据集类:
`class Digits:
def __init__(self):
self.imgs = np.load('x_tr.npy')
self.test_imgs = np.load('x_te.npy')
self.labels = np.load('y_tr.npy')
self.test_labels = np.load('y_te.npy')
self.labels = one_hot_encoded(self.labels, 10)
self.test_labels = one_hot_encoded(self.test_labels, 10)
self.x_dim = [8, 8, 1](#)
self.num_classes = 10
@staticmethod
def get_batch(batch_size, x, y):
"""Returns a batch from the given arrays.
"""
idx = np.random.choice(range(x.shape[0](#)), size=(batch_size,), replace=False)
return x[idx](#), y[idx](#)
def next_batch(self, batch_size, class_id=None):
return self.get_batch(batch_size, self.imgs, self.labels)
def test_batch(self, batch_size):
return self.get_batch(batch_size, self.test_imgs, self.test_labels)这个类必须有next_batch和test_batch等函数, 同时要包含imgs,labels,test_imgs,test_labels,x_dim以及num_classes` 属性.
这时候我们就可以引入 Digits 类到 bayesian_gan_hmc.py中了
`from bgan_util import Digits同时可以在--dataset` 参数中添加如下行
`if args.dataset == "digits":
dataset = Digits()` 在准备工作结束后,我们可以用下面命令来训练模型
`./bayesian_gan_hmc.py --data_path \<any_path\> --dataset digits --numz 1 --num_mcmc 10
--out_dir \<results path\> --train_iter 5000 --save_samples声明
感谢Pavel Izmailov对代码进行的压力测试,并且写出这份教程。
参考网址链接:
代码:https://github.com/andrewgordonwilson/bayesgan
论文:https://arxiv.org/abs/1705.09558
特别提示-课程课件和视频下载:
请关注专知公众号(扫一扫最下面专知二维码,或者点击上方蓝色专知),
后台回复“GAN” 就可以获取生成式对抗网络GAN知识资料全集下载查看链接~~
请登录专知,获取GAN知识资料,请PC登录www.zhuanzhi.ai或者点击阅读原文,顶端搜索“GAN” 主题,查看获得对应主题专知荟萃全集知识等资料!如下图所示~
欢迎转发到你的微信群和朋友圈,分享专业AI知识!
更多专知荟萃知识资料全集获取,请查看:
【专知荟萃01】深度学习知识资料大全集(入门/进阶/论文/代码/数据/综述/领域专家等)(附pdf下载)
【专知荟萃02】自然语言处理NLP知识资料大全集(入门/进阶/论文/Toolkit/数据/综述/专家等)(附pdf下载)
【专知荟萃03】知识图谱KG知识资料全集(入门/进阶/论文/代码/数据/综述/专家等)(附pdf下载)
【专知荟萃04】自动问答QA知识资料全集(入门/进阶/论文/代码/数据/综述/专家等)(附pdf下载)
【专知荟萃05】聊天机器人Chatbot知识资料全集(入门/进阶/论文/软件/数据/专家等)(附pdf下载)
【专知荟萃06】计算机视觉CV知识资料大全集(入门/进阶/论文/课程/会议/专家等)(附pdf下载)
【专知荟萃07】自动文摘AS知识资料全集(入门/进阶/代码/数据/专家等)(附pdf下载)
【专知荟萃08】图像描述生成Image Caption知识资料全集(入门/进阶/论文/综述/视频/专家等)
【专知荟萃09】目标检测知识资料全集(入门/进阶/论文/综述/视频/代码等)
【专知荟萃10】推荐系统RS知识资料全集(入门/进阶/论文/综述/视频/代码等)
【教程实战】Google DeepMind David Silver《深度强化学习》公开课教程学习笔记以及实战代码完整版
【GAN货】生成对抗网络知识资料全集(论文/代码/教程/视频/文章等)
【干货】Google GAN之父Ian Goodfellow ICCV2017演讲:解读生成对抗网络的原理与应用
【AlphaGoZero核心技术】深度强化学习知识资料全集(论文/代码/教程/视频/文章等)
请扫描小助手,加入专知人工智能群,交流分享~

获取更多关于机器学习以及人工智能知识资料,请访问www.zhuanzhi.ai, 或者点击阅读原文,即可得到!
-END-
欢迎使用专知
专知,一个新的认知方式!目前聚焦在人工智能领域为AI从业者提供专业可信的知识分发服务, 包括主题定制、主题链路、搜索发现等服务,帮你又好又快找到所需知识。
使用方法>>访问www.zhuanzhi.ai, 或点击文章下方“阅读原文”即可访问专知
中国科学院自动化研究所专知团队
@2017 专知
专 · 知
关注我们的公众号,获取最新关于专知以及人工智能的资讯、技术、算法、深度干货等内容。扫一扫下方关注我们的微信公众号。


点击“阅读原文”,使用专知!



