【教程】详解如何使用Keras实现Wassertein GAN
选自Deeply Random
来源:机器之心
参与:晏奇、李泽南
在阅读论文 Wassertein GAN 时,作者发现理解它最好的办法就是用代码来实现其内容。于是在本文中,作者将用自己的在 Keras 上的代码来向大家简要介绍一下WGAN。
何为 GAN?
GAN,亦称为生成对抗网络(Generative Adversarial Network),它是生成模型中的一类——即一种能够通过观察来自特定分布的训练数据,进而尝试对这个分布进行预测的模型。这个模型新获取的样本「看起来」会和最初的训练样本类似。有些生成模型只会去学习训练数据分布的参数,有一些模型则只能从训练数据分布中提取样本,而有一些则可以二者兼顾。
目前,已经存在了很多种类的生成模型:全可见信念网络(Fully Visible Belief Network)、变分自编码器(Variational Autoencoder)、玻尔兹曼机(Boltzmann Machine),生成随机网络(Generative Stochastic Network),像素循环神经网络(PixelRNN)等等。以上的模型都因其所表征或接近的训练数据密度而有所区别。一些模型会去精细的表征训练数据,另一些则会以某种方式去和训练数据进行互动——比如说生成模型。GAN 就是这里所说的后者。大部分生成模型的学习原则都可被概括为「最大化相似度预测」——即让模型的参数能够尽可能地与训练数据相似。
GAN 的工作方式可以看成一个由两部分构成的游戏:生成器(Generator/G)和判别器(Discriminator/D)(一般而言,这两者都由神经网络构成)。生成器随机将一个噪声作为自己的输入,然后尝试去生成一个样本,目的是让判别器无法判断这个样本是来自训练数据还是来自生成器的。在判别器这里,我们让它以监督学习方式来工作,具体而言就是让它观察真实样本和生成器生成的样本,并且同时用标签告诉它这些样本分别来自哪里。在某种意义上,判别器可以代替固定的损失函数,并且尝试学习与训练数据分布相关的模式。
何为 Wasserstein GAN?
就其本质而言,任何生成模型的目标都是让模型(习得地)的分布与真实数据之间的差异达到最小。然而,传统 GAN 中的判别器 D 并不会当模型与真实的分布重叠度不够时去提供足够的信息来估计这个差异度——这导致生成器得不到一个强有力的反馈信息(特别是在训练之初),此外生成器的稳定性也普遍不足。
Wasserstein GAN 在原来的基础之上添加了一些新的方法,让判别器 D 去拟合模型与真实分布之间的 Wasserstein 距离。Wassersterin 距离会大致估计出「调整一个分布去匹配另一个分布还需要多少工作」。此外,其定义的方式十分值得注意,它甚至可以适用于非重叠的分布。
为了让判别器 D 可以有效地拟合 Wasserstein 距离:
其权重必须在紧致空间(compact space)之内。为了达到这个目的,其权重需要在每步训练之后,被调整到-0.01 到+0.01 的闭区间上。然而,论文作者承认,虽然这对于裁剪间距的选择并不是理想且高敏感的(highly sensitive),但是它在实践中却是有效的。更多信息可参见论文 6 到 7 页。
由于判别器被训练到了更好的状态上,所以它可以为生成器提供一个有用的梯度。
判别器顶层需要有线性激活。
它需要一个本质上不会修改判别器输出的价值函数。
K.mean(y_true * y_pred)
以 keras 这段损失函数为例:
这里采用 mean 来适应不同的批大小以及乘积。
预测的值通过乘上 element(可使用的真值)来最大化输出结果(优化器通常会将损失函数的值最小化)。
论文作者表示,与 vanlillaGAN 相比,WGAN 有一下优点:
有意义的损失指标。判别器 D 的损失可以与生成样本(这些样本使得可以更少地监控训练过程)的质量很好地关联起来。
稳定性得到改进。当判别器 D 的训练达到了最佳,它便可以为生成器 G 的训练提供一个有用的损失。这意味着,对判别器 D 和生成器 G 的训练不必在样本数量上保持平衡(相反,在 Vanilla GAN 方法中而这是平衡的)。此外,作者也表示,在实验中,他们的 WGAN 模型没有发生过一次崩溃的情况。
开始编程!
我们会在 Keras 上实现 ACGAN 的 Wasserstein variety。在 ACGAN 这种生成对抗网络中,其判别器 D 不仅可以预测样本的真实与否,同时还可以将其进行归类。
下方代码附有部分解释。
[1] 导入库文件:
import os
import matplotlib.pyplot as plt
%matplotlib inline
%config InlineBackend.figure_format = 'retina' # enable hi-res output
import numpy as np
import tensorflow as tf
import keras.backend as K
from keras.datasets import mnist
from keras.layers import *
from keras.models import *
from keras.optimizers import *
from keras.initializers import *
from keras.callbacks import *
from keras.utils.generic_utils import Progbar[2].Runtime 配置
# random seed
RND = 777
# output settings
RUN = 'B'
OUT_DIR = 'out/' + RUN
TENSORBOARD_DIR = '/tensorboard/wgans/' + RUN
SAVE_SAMPLE_IMAGES = False
# GPU # to run on
GPU = "0"
BATCH_SIZE = 100
ITERATIONS = 20000
# size of the random vector used to initialize G
Z_SIZE = 100[3]生成器 G 每进行一次迭代,判别器 D 都需要进行 D_ITERS 次迭代。
由于在 WGAN 中让判别器质量能够优化这件事更加重要,所以判别器 D 与生成器 G 在训练次数上呈非对称比例。
在论文的 v2 版本中,判别器 D 在生成器 G 每 1000 次迭代的前 25 次都会训练 100 次,此外,判别器也会当生成器每进行了 500 次迭代以后训练 100 次。
D_ITERS = 5
[4]其它准备:
# create output dirif not os.path.isdir(OUT_DIR): os.makedirs(OUT_DIR) # make only specific GPU to be utilized os.environ["CUDA_DEVICE_ORDER"] = "PCI_BUS_ID"os.environ["CUDA_VISIBLE_DEVICES"] = GPU # seed random generator for repeatability np.random.seed(RND) # force Keras to use last dimension for image channels K.set_image_dim_ordering('tf')
[5]判别器的损失函数:
由于判别器 D 一方面力图在训练数据分布与生成器 G 生成的数据之间习得一个 Wasserstein 距离的拟合,另一方面判别器 D 又是线性激活的,所以这里我们不需要去修改它的输出结果。
由于已经使用了损失函数 Mean,所以我们可以在不同的批大小之间比较输出结果。
预测结果等于真值(true value)与元素的点乘(element-wise multiplication),为了让判别器 D 的输出能够最大化(通常,优化器都力图去让损失函数的值达到最小),真值需要取-1。
def d_loss(y_true, y_pred): return K.mean(y_true * y_pred)
[6].创建判别器 D
判别器将图像作为输入,然后给出两个输出:
用线性激活来评价生成图像的「虚假度」(最大化以用于生成图像)。
用 softmax 激活来对图像种类进行预测。
由于权重是从标准差为 0.02 的正态分布中初始化出来的,所以最初的剪裁不会去掉所有的权重。
def create_D():
# weights are initlaized from normal distribution with below params weight_init = RandomNormal(mean=0., stddev=0.02) input_image = Input(shape=(28, 28, 1), name='input_image') x = Conv2D( 32, (3, 3), padding='same', name='conv_1', kernel_initializer=weight_init)(input_image) x = LeakyReLU()(x) x = MaxPool2D(pool_size=2)(x) x = Dropout(0.3)(x) x = Conv2D( 64, (3, 3), padding='same', name='conv_2', kernel_initializer=weight_init)(x) x = MaxPool2D(pool_size=1)(x) x = LeakyReLU()(x) x = Dropout(0.3)(x) x = Conv2D( 128, (3, 3), padding='same', name='conv_3', kernel_initializer=weight_init)(x) x = MaxPool2D(pool_size=2)(x) x = LeakyReLU()(x) x = Dropout(0.3)(x) x = Conv2D( 256, (3, 3), padding='same', name='coonv_4', kernel_initializer=weight_init)(x) x = MaxPool2D(pool_size=1)(x) x = LeakyReLU()(x) x = Dropout(0.3)(x) features = Flatten()(x) output_is_fake = Dense( 1, activation='linear', name='output_is_fake')(features) output_class = Dense( 10, activation='softmax', name='output_class')(features) return Model( inputs=[input_image], outputs=[output_is_fake, output_class], name='D')
[7].创建生成器
生成器有两个输入:
一个尺寸为Z_SIZE的潜在随机变量。
我们希望生成的数字类型(integer o 到 9)。
为了加入这些输入(input),integer 类型会在内部转换成一个1 x DICT_LEN(在本例中DICT_LEN = 10)的稀疏向量,然后乘上嵌入的维度为 DICT_LEN x Z_SIZE的矩阵,结果得到一个维度为1 x Z_SIZE的密集向量。然后该向量乘上(点 乘)可能的输入(input),经过多个上菜样和卷积层,最后其维度就可以和训练图像的维度匹配了。
def create_G(Z_SIZE=Z_SIZE): DICT_LEN = 10 EMBEDDING_LEN = Z_SIZE # weights are initialized from normal distribution with below params weight_init = RandomNormal(mean=0., stddev=0.02) # class# input_class = Input(shape=(1, ), dtype='int32', name='input_class') # encode class# to the same size as Z to use hadamard multiplication later on e = Embedding( DICT_LEN, EMBEDDING_LEN, embeddings_initializer='glorot_uniform')(input_class) embedded_class = Flatten(name='embedded_class')(e) # latent var input_z = Input(shape=(Z_SIZE, ), name='input_z') # hadamard product h = multiply([input_z, embedded_class], name='h') # cnn part x = Dense(1024)(h) x = LeakyReLU()(x) x = Dense(128 * 7 * 7)(x) x = LeakyReLU()(x) x = Reshape((7, 7, 128))(x) x = UpSampling2D(size=(2, 2))(x) x = Conv2D(256, (5, 5), padding='same', kernel_initializer=weight_init)(x) x = LeakyReLU()(x) x = UpSampling2D(size=(2, 2))(x) x = Conv2D(128, (5, 5), padding='same', kernel_initializer=weight_init)(x) x = LeakyReLU()(x) x = Conv2D( 1, (2, 2), padding='same', activation='tanh', name='output_generated_image', kernel_initializer=weight_init)(x) return Model(inputs=[input_z, input_class], outputs=x, name='G')
[8].将判别器 D 和生成器 G 整合到一个模型中:
D = create_D() D.compile( optimizer=RMSprop(lr=0.00005), loss=[d_loss, 'sparse_categorical_crossentropy']) input_z = Input(shape=(Z_SIZE, ), name='input_z_') input_class = Input(shape=(1, ),name='input_class_', dtype='int32') G = create_G() # create combined D(G) model output_is_fake, output_class = D(G(inputs=[input_z, input_class])) DG = Model(inputs=[input_z, input_class], outputs=[output_is_fake, output_class]) DG.compile( optimizer=RMSprop(lr=0.00005), loss=[d_loss, 'sparse_categorical_crossentropy'] )
[9].加载 MNIST 数据集:
# load mnist data (X_train, y_train), (X_test, y_test) = mnist.load_data() # use all available 70k samples from both train and test sets X_train = np.concatenate((X_train, X_test)) y_train = np.concatenate((y_train, y_test)) # convert to -1..1 range, reshape to (sample_i, 28, 28, 1) X_train = (X_train.astype(np.float32) - 127.5) / 127.5X_train = np.expand_dims(X_train, axis=3)
[10].生成样本以及将指标和图像发送到 TensorBorad 的实用工具:
# save 10x10 sample of generated images def generate_samples(n=0, save=True): zz = np.random.normal(0., 1., (100, Z_SIZE)) generated_classes = np.array(list(range(0, 10)) * 10) generated_images = G.predict([zz, generated_classes.reshape(-1, 1)]) rr = [] for c in range(10): rr.append( np.concatenate(generated_images[c * 10:(1 + c) * 10]).reshape( 280, 28)) img = np.hstack(rr) if save: plt.imsave(OUT_DIR + '/samples_%07d.png' % n, img, cmap=plt.cm.gray) return img # write tensorboard summaries sw = tf.summary.FileWriter(TENSORBOARD_DIR) def update_tb_summary(step, write_sample_images=True): s = tf.Summary() # losses as is for names, vals in zip((('D_real_is_fake', 'D_real_class'), ('D_fake_is_fake', 'D_fake_class'), ('DG_is_fake', 'DG_class')), (D_true_losses, D_fake_losses, DG_losses)): v = s.value.add() v.simple_value = vals[-1][1] v.tag = names[0] v = s.value.add() v.simple_value = vals[-1][2] v.tag = names[1] # D loss: -1*D_true_is_fake - D_fake_is_fake v = s.value.add() v.simple_value = -D_true_losses[-1][1] - D_fake_losses[-1][1] v.tag = 'D loss (-1*D_real_is_fake - D_fake_is_fake)' # generated image if write_sample_images: img = generate_samples(step, save=True) s.MergeFromString(tf.Session().run( tf.summary.image('samples_%07d' % step, img.reshape([1, *img.shape, 1])))) sw.add_summary(s, step) sw.flush()
[11].训练
训练过程包含了以下步骤:
1、解除对判别器 D 权重的控制,让它们变得可学习。
2、调整判别器的权重(调整到-0.01 到+0.01 闭区间上)。
3、向判别器 D 提供真实的样本,通过在损失函数中将其乘上-1 来尽可能最大化它的输出,最小化它的值。
4、向判别器 D 提供假的样本试图最小化其输出。
5、按照上文讲述的判别器迭代训练方法重复步骤 3 和 4。
6、固定判别器 D 的权重。
7、训练一对判别器和生成器,尽力去最小化其输出。由于这种手段优化了生成器 G 的权重,所以前面已经训练好了的权重固定的判别器才会将生成的假样本判断为真图像。
progress_bar = Progbar(target=ITERATIONS) DG_losses = [] D_true_losses = [] D_fake_losses = []for it in range(ITERATIONS): if len(D_true_losses) > 0: progress_bar.update( it, values=[ # avg of 5 most recent ('D_real_is_fake', np.mean(D_true_losses[-5:], axis=0)[1]), ('D_real_class', np.mean(D_true_losses[-5:], axis=0)[2]), ('D_fake_is_fake', np.mean(D_fake_losses[-5:], axis=0)[1]), ('D_fake_class', np.mean(D_fake_losses[-5:], axis=0)[2]), ('D(G)_is_fake', np.mean(DG_losses[-5:],axis=0)[1]), ('D(G)_class', np.mean(DG_losses[-5:],axis=0)[2]) ] ) else: progress_bar.update(it) # 1: train D on real+generated images if (it % 1000) < 25 or it % 500 == 0: # 25 times in 1000, every 500th d_iters = 100 else: d_iters = D_ITERS for d_it in range(d_iters): # unfreeze D D.trainable = True for l in D.layers: l.trainable = True # clip D weights for l in D.layers: weights = l.get_weights() weights = [np.clip(w, -0.01, 0.01) for w in weights] l.set_weights(weights) # 1.1: maximize D output on reals === minimize -1*(D(real)) # draw random samples from real images index = np.random.choice(len(X_train), BATCH_SIZE, replace=False) real_images = X_train[index] real_images_classes = y_train[index] D_loss = D.train_on_batch(real_images, [-np.ones(BATCH_SIZE), real_images_classes]) D_true_losses.append(D_loss) # 1.2: minimize D output on fakes zz = np.random.normal(0., 1., (BATCH_SIZE, Z_SIZE)) generated_classes = np.random.randint(0, 10, BATCH_SIZE) generated_images = G.predict([zz, generated_classes.reshape(-1, 1)]) D_loss = D.train_on_batch(generated_images, [np.ones(BATCH_SIZE), generated_classes]) D_fake_losses.append(D_loss) # 2: train D(G) (D is frozen) # minimize D output while supplying it with fakes, # telling it that they are reals (-1) # freeze D D.trainable = False for l in D.layers: l.trainable = False zz = np.random.normal(0., 1., (BATCH_SIZE, Z_SIZE)) generated_classes = np.random.randint(0, 10, BATCH_SIZE) DG_loss = DG.train_on_batch( [zz, generated_classes.reshape((-1, 1))], [-np.ones(BATCH_SIZE), generated_classes]) DG_losses.append(DG_loss) if it % 10 == 0: update_tb_summary(it, write_sample_images=(it % 250 == 0))
结论
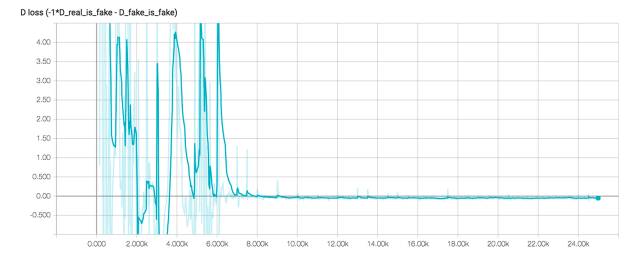
视频的每一秒都是 250 次训练迭代。使用 Wasserstein GAN 的一个好处就是它有着损失与样本质量之间的关系。如我们在下方看到的损失图,当进行了约 8000 次训练之后,损失开始逼近 0,在视频中 32 秒位置时,我们已经开始可以看到像样的图像了。
附论文地址:https://arxiv.org/pdf/1701.07875.pdf
参考文献
1. Wasserstein GAN paper (https://arxiv.org/pdf/1701.07875.pdf) – Martin Arjovsky, Soumith Chintala, Léon Bottou
2. NIPS 2016 Tutorial: Generative Adversarial Networks (https://arxiv.org/pdf/1701.00160.pdf) – Ian Goodfellow
3. Original PyTorch code for the Wasserstein GAN paper (https://github.com/martinarjovsky/WassersteinGAN)
4. Conditional Image Synthesis with Auxiliary Classifier GANs (https://arxiv.org/pdf/1610.09585v3.pdf) – Augustus Odena, Christopher Olah, Jonathon Shlens
5. Keras ACGAN implementation (https://github.com/lukedeo/keras-acgan) – Luke de Oliveira
6. Code for the article (https://gist.github.com/myurasov/6ecf449b32eb263e7d9a7f6e9aed5dc2)
☞ 【最详尽的GAN介绍】王飞跃等:生成式对抗网络 GAN 的研究进展与展望
☞ 【智能自动化学科前沿讲习班第1期】王飞跃教授:生成式对抗网络GAN的研究进展与展望
☞ 【智能自动化学科前沿讲习班第1期】王坤峰副研究员:GAN与平行视觉
☞ 【重磅】平行将成为一种常态:从SimGAN获得CVPR 2017最佳论文奖说起
☞ 【GitHub项目】GAN完整理论推导与实现,Perfect!
☞ 【算法】深度学习优化器算法详解:梯度更新规则+缺点+如何选择






