相关性≠因果:概率图模型和do-calculus
编者按:Databricks数据科学主管Sean Owen讨论了三种数据提供有歧义的结果的情况,以及因果关系如何帮助澄清数据的解读。

相关和因果
相关性不等于因果。仅仅因为冰淇淋和美黑霜销量同时上升或下降并不意味着两者之间有什么因果关系。然而,人类的思考方式倾向于因果关系。你大概已经意识到这两种商品的销量均取决于夏季炎热的天气。那么,因果关系是一个什么样的角色?
新入行的数据科学家可能有一个印象,因果关系是一个大家避而不谈的话题。这是一个错误印象。我们使用数据决定“哪则广告将导致更多点击?”这样的事情。已经有一个易用、开放工具的生态系统,可供我们基于数据建立模型,我们觉得这些模型可以回答关于成因和效果的问题。什么时候它们确实做到了这一点,什么时候我们误以为它们做到了?
数据告诉我们什么,和我们认为数据告诉我们什么,这两者之间存在着微妙的空隙,这正是困惑和错误的源泉。新入行的数据科学家,尽管配备了强大的建模工具,仍可能成为“未知的未知”的牺牲品,即使是在简单的分析中也是如此。
本文将演示三种看起来简单的情况,这些情况会产生惊人的歧义结果。剧透:在所有情形下,因果关系是澄清数据解读必不可少的成分。包括概率图模型和do-calculus在内的激动人心的工具,能够让我们基于数据和因果关系进行推理,得出强有力的结论。
两条“最佳拟合”直线
考虑R内置的cars数据集。这个简单的小数据集提供了不同车速的制动距离。假设低速情况下,两者的关系是线性的。
再没什么能比线性回归更简单了吧?距离是速度的函数:
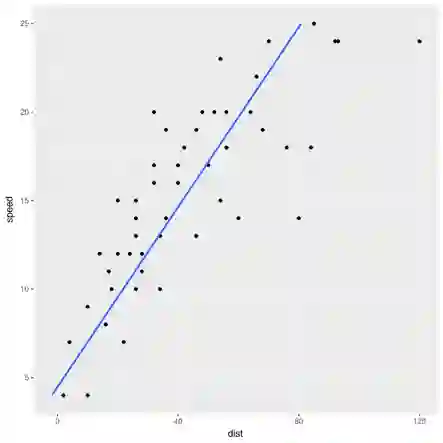
同样,速度也是距离的函数:
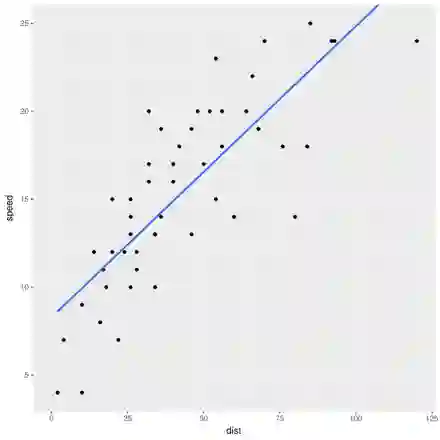
尽管看起来是同一件事,两种说法,这两种回归会给出不同的最佳拟合直线。这两条线不可能都是最佳的,那么哪一条才是最佳拟合直线,为什么?
如果你想亲自验证,可以查看、运行创建上面两个图形的代码:https://trial.dominodatalab.com/u/srowen/causation/view/main.R
两个最佳疗法
下面的数据集可能看起来很熟悉。它显示了肾结石的两种疗法的治愈率。
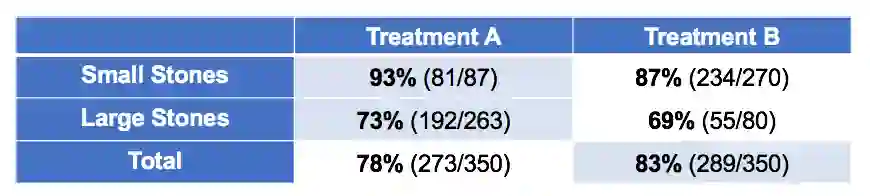
你也许注意到了上表的奇怪之处。总体而言,B疗法的治愈率更高。然而,A疗法在小结石上有着更高的治愈率,在小结石以外的情形(大结石)上也有着更高的治愈率。这怎么可能?你可以自己算一下。
许多人会马上意识到这是辛普森悖论的一个典型例子。(这个例子取自辛普森悖论的维基页面。)意识到这一点很重要。然而,意识到这一点并不能回答真正的问题:哪种疗法更好?
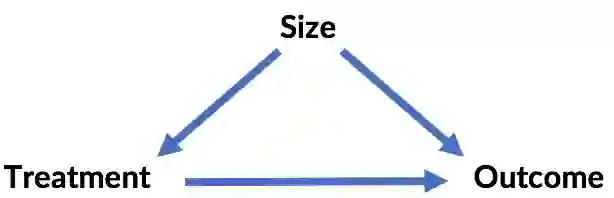
这里,A疗法更好。较大的肾结石更难治疗,总体而言治愈率更低。在这些比较困难的情形下,更常应用A疗法。虽然A疗法实际上更好,但因为更常应用在困难情形下,总体治愈率被拉低了。结石大小是一个混淆变量,表格的横行控制了结石大小。所以,控制所有像这样的变量以避免出现悖论总不会错吧?
考虑下面的数据:
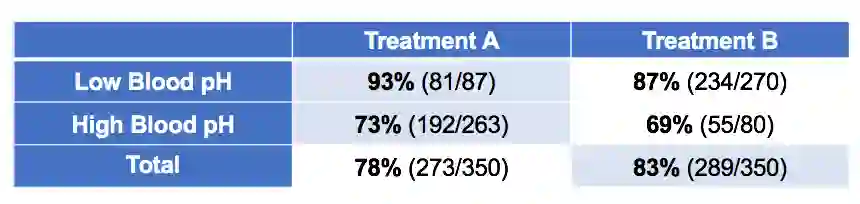
这次是根据治疗后病人的血酸分组。基于这些数据,哪种疗法更好?为什么?
虚幻的相关性
最后,考虑R内置的mtcars数据集。它提供了20世界70年代的一些车型的统计数据,例如引擎汽缸容量、燃油效率、气缸数量,等等。考虑drat(后轮轴减速比)和carb(化油器数量——现在的车不使用化油器,改用电子喷射系统)的相关性。
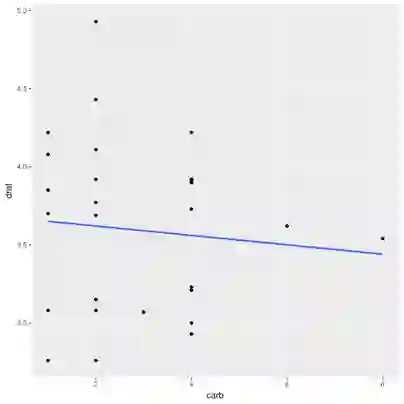
几乎没有相关性(r = -0.09)。这是有道理的,毕竟变速设计和引擎设计实际上是正交的。(我承认这不是一个最直观的例子,但这是R语言内置的简易数据集中最易懂的例子。)
然而,如果我们只考虑6缸或8缸引擎的车型:
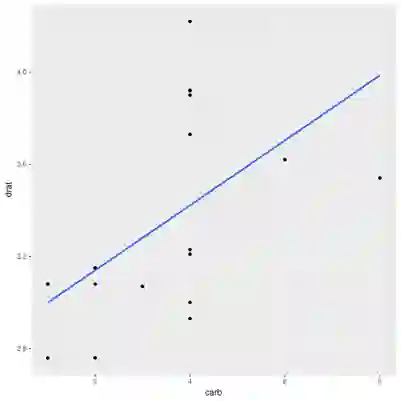
有很清楚的正相关性(r = 0.52)。那么其他车型呢?
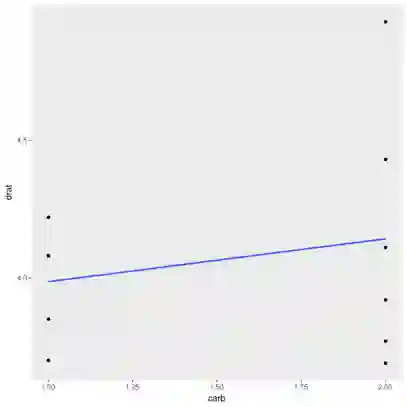
竟也有较小的正相关性(r = 0.22)。两个变量在部分数据上相关,在剩余数据上也相关,但是在整体数据上却不相关,怎么可能会这样?
答案在因果关系之中
当然,这些问题都有答案。在第一个例子中,两条不同的直线源自两组不同的假定。距离 ~ 速度回归意味着距离是速度的线性函数,加上高斯噪声,直线最小化实际距离和预测距离的均方误差。另一条直线最小化实际速度和预测速度的均方误差。前者对应的假定是速度的不同导致了制动距离的不同,很有道理;后者暗示距离的不同导致了速度的不同,没有意义。所以源自距离 ~ 速度的直线是正确的最佳拟合直线。不过,判定这一点需要数据以外的信息。
速度不同导致制动距离不同这一想法可以用一个(非常简单的)有向图表示:

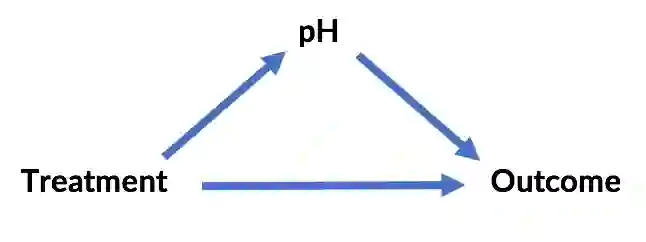
类似地,在辛普森悖论的第二个例子中,血酸不再是混淆变量,而是中介变量。它并不导致选取哪种疗法,反而是选取哪种疗法导致了不同的血酸水平。将它作为控制变量等于移除了疗法的主要效果。在这一情形下,B疗法看起来要好一点,因为它导向更低的血酸,从而导向更好的结果(尽管A疗法确实看起来有一些正面的次级效应)。
因此,辛普森悖论的原场景为:
而第二个场景为:
同样,这里的“悖论”是可以解决的。关于因果关系的外部信息解决了“悖论”——两个场景的解决方式不同!
第三个例子是伯克森悖论的一个例子。假定后轮轴减速比和化油器数目都影响汽缸数目(这里不展开讨论,假定引擎设计上这一点成立),那么后轮轴减速比和化油器数量没有相关性这一结论是正确的。控制汽缸数目创造了不存在的相关性,因为汽缸数目是同时和后轮轴减速比与化油器数量相关的“碰撞”变量。
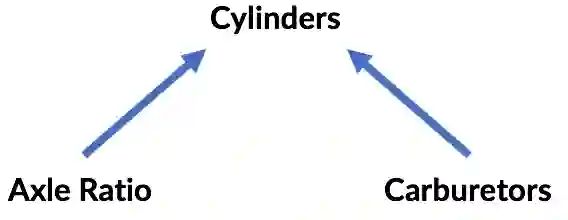
同样,数据没有告诉我们这点;具备变量之间因果关系的知识才能得出这一结论。
概率图模型和do-Calculus
我们上面绘制概率图模型(PGM)有其目的。这些图表达了成因-结果关系中的条件概率依赖的类型。尽管上述情形的概率图很是微不足道,它们很容易变得很复杂。然而,不管简单还是复杂,我们都可以通过分析概率图检测正确分析数据所需的变量之间的关系。
PGM是一个有趣的主题。(Coursera上有Daphne Koller开的课程。)理解因果关系的重要性,以及如何分析因果关系以正确解读数据是数据科学家之旅必经的一步。
这类分析导向了一种可能更加激动人心的能力。假如一个变量取了不同的值,会发生什么?做出这方面的推理是有可能的。这一想法听起来像是条件概率:给定今天的冰淇淋销量很高(IC)这一条件,美黑霜的销量很高(ST)的概率是多少?也就是,P(ST|IC)是多少?基于数据集,这很容易回答。如果两者是正相关的,我们可以进一步期望P(IC|ST) > P(IC)——也就是说,当美黑霜的销量很高的时候,冰淇淋的销量很高的概率更大。
然而,如果我们提高了美黑霜的销量(也许可以记作do(ST)),那么冰淇淋的销量会增长吗?很清楚,P(IC|do(ST))和P(IC|ST)不是一回事,因为我们不期望这两者之间有什么因果联系。
数据只提供了简单的条件概率吗?我们有可能演算数据中未曾发生的反事实概率,从而评判这些有关行动的论断吗?
令人惊喜的答案,是的,在因果模型和Judea Pearl提出的“do-calculus”的帮助下,这是有可能的。do-calculus是Pearl的新书The Book of Why的主题。这本书总结了因果思考的历史,贝叶斯网络,图模型和Pearl自己对这一领域的显著贡献,在此高度推荐。
也许do-calculus最引人入胜的演示是这本书对吸烟致癌相关研究的回溯分析。据Pearl所述,吸烟致癌到底是通过肺部烟焦油囤积,还是因为未知的基因因素同时导致了喜欢吸烟和易得肺癌,对此人们曾有疑问。不幸的是,这一基因因素无法观测,也不可能控制。画出其中暗含的因果模型,就很容易做出推理。
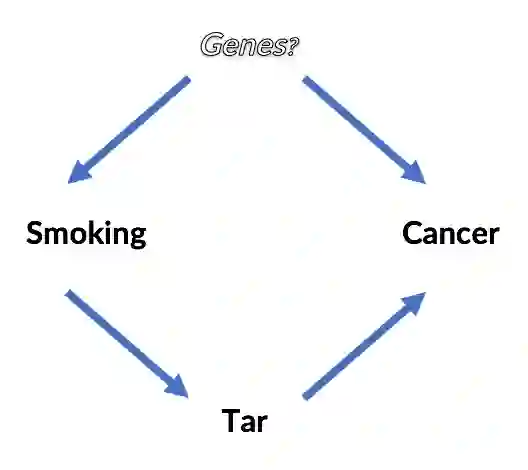
即使在不能确定基因因素是否存在的情况下,还有可能回答“吸烟致癌”这样的问题吗?P(癌|do(吸烟)) > P(癌)吗?
通过应用do-calculus的三条基本规则,这是有可能做到的,具体细节这里就不展开了(请看论文和书)。应用do-calculus规则之后,只涉及吸烟、烟焦油、癌症的条件概率,这些都可以从现实数据集中得出:

仅仅通过数据中的条件概率,即使在不知道是否存在未知混淆变量的情况下,就有可能知道是否吸烟导致患癌风险增加,
结语
有经验的数据科学家不仅知道如何将工具作为黑箱使用,还知道模型和数据的正确解读常常具有歧义,甚至违背直觉。避免常见误区是资深从业者的标志。

幸运的是,许多这样的悖论有着常见的来源,通过基于成因-效果网络的推理,可以分析这些来源,从而解决这些悖论。概率图模型和统计方法一样重要。
再加上do-calculus,我们可以基于数据做出一些解读和分析,对那些习惯相信无法仅仅从数据中得到因果或反事实结论的人来说,这些解读和分析十分惊人!
原文地址:https://blog.dominodatalab.com/three-simple-worrying-stats-problems/