Yann LeCun说是时候放弃概率论了,因果关系才是理解世界的基石

作者:Carlos E. Perez
编译:高宁、阮雪妮、Aileen
Yann LeCun说,他已经做好放弃概率论的准备了!
今年9月初,Yann LeCun在Cognitive Computational Neuroscience (CCN) 2017上发表了题为“为什么大脑能短时间内学习如此多东西?”的演讲,在演讲中他提到,他已经做好放弃概率论(throw Probability Theory under the bus)的准备。
他认为概率理论只是一个工具,而非现实或智能系统的基本特征。作为一个工具,它就存在应用领域的限制。就算你的锯子能够砍树,这并不意味着它就能切割钛。
点击查看Yann LeCun演讲
▼
视频来源:http://www.ccneuro.org
概率论存在的这个问题与预测的有效性密切相关。首先,请看下面的gif动图
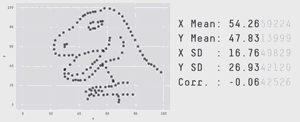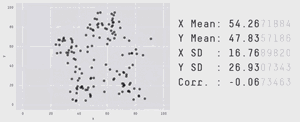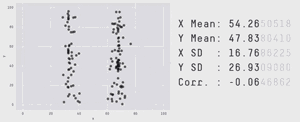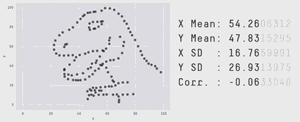
从图中我们可以很明显看出他们的分布是不同的,但右侧显示的统计测量的方法和结果却是相同的!换句话说,如果你的预测是基于概率分布所计算出的期望值,那么你很容易就被骗了。
创建这些分布的方法和我们在深度学习中发现的渐进方法类似,主要使用摄动方法(perturbation method)和模拟退火(simulated annealing)。从这个角度看,如果你想骗过一个统计学家,那么深度学习方法会是一个非常方便的工具。
在2015年,有一篇很有趣的论文“使用非平衡热力学进行深度无监督学习”(“Deep Unsupervised Learning using Nonequilibrium Thermodynamics)”写道,你可以使用统计力学的摄动方法,从根本上重新创建一个从随机噪音开始的特定分布。也有一个反向扩散的方法可以将噪音回收成原始分布。
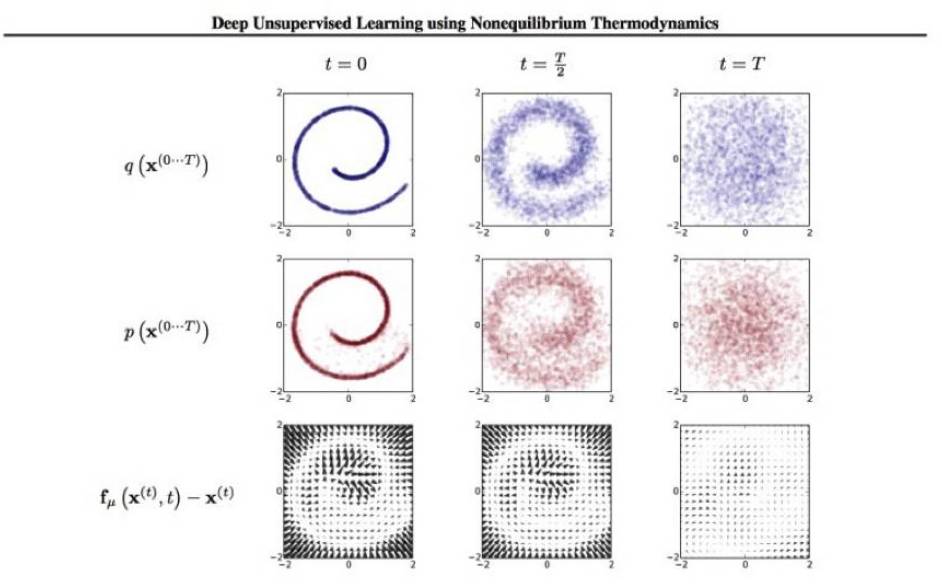
图:我们是基于二维的类似“瑞士卷”分布的数据集上训练的建模框架。第一行显示了沿着轨道方向的时间切片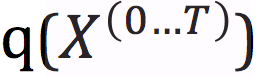
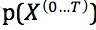
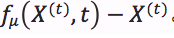
增量摄动(Incremental perturbation)是一个非常强大的工具,很难对其使用统计方法进行处理。摄动方法很重要的一点是它们在非均衡状态下运行。也就是说,与中心极限定理(Central Limit Theorem)所在的范围相差还很远。以上信息让我们有理由相信:增量摄动法确实可以躲过统计检测。
然而,如何创建人为分布并不是我们的真正问题。真正的问题在与,整个贝叶斯理论的实践以及相关的信息理论在非线性领域存在着根本性的缺陷。
Sante Fe复杂性科学研究机构的James Crutchfield最近在新加坡做了一个非常有趣的演讲,提到了非线性系统的这些缺陷:
那些在香农熵(Shannon Entropy)或贝叶斯理论中将过去、现在的概率与未来预测联系起来的方程,在非线性纠缠系统中进行预测时,从本质上说是毫无价值的。相关的论文链接(http://csc.ucdavis.edu/~cmg/papers/mdbsi.pdf),这篇论文中的一个图解让“贝叶斯们”开始去质疑他们在18世纪的信仰:
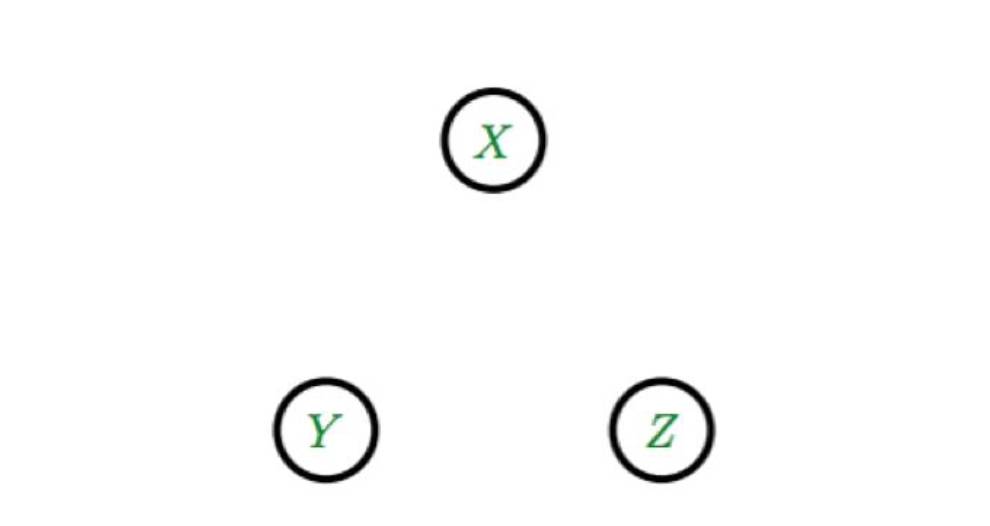
图:图中描述了将多个贝叶斯网络推理算法应用于二元分布和三元分布的结果。该算法认为变量X,Y和Z之间不存在相关关系,所以形成了三个独立的节点。这个算法会出错其实并不意外:因为二元分布和三元分布不能用有向的无环图来表示,但这是贝叶斯网络的基本假设之一。
总而言之,我们只知道这些非线性系统工作得非常好,但我们对它们一无所知。Crutchfield的发现结果(这可以通过模拟来验证,不能用逻辑论证)是概率归纳法并不适用于非线性领域。
事实上这确实是复杂和非线性的,但幸运的是,我们已经找到了一丝光明:可以通过综合措施来消除非线性的影响。因此,概率归纳可以通过类似于使用分段线性段逼近曲线的方法来运行。这听起来有点疯狂,但它在特定情况下确实可以运行。然而,这并不是一个万无一失的方法。
预测系统的研究人员必须提出的问题是:我们能做得更好吗?我们可以使用纯粹的摄动方法而不用概率归纳法吗?概率归纳法的问题在于它是一种“不成熟的优化”。也就是说这种数学方法中考虑了不确定性。所以当我们使用这种数据方法来预测时,就受到了潜在的不确定性处理机制的影响。
我们的大脑并没有使用蒙特卡罗抽样来估算概率,那么它是怎样处理不确定性的呢?
它的工作方式和“乐观交易”处理不确定性的方式相同,也与任何强大且可扩展的系统处理故障的方式相一致。任何强大的系统都假设会发生故障,因为配置有相应的调整机制。我们的大脑在遇到意外的情况时会进行补偿标记。它通过摄动方法来学习自我纠正。这也是深度学习系统在做的事情,和概率计算无关。这只是一大堆“无限小”的增量的调整。
摄动系统可能有点让人讨厌,因为它们像迭代函数系统(IFS)一样。任何自我迭代或拥有内存的系统都可能成为混沌行为或通用机器的候选对象。我们应该接受现实,这些系统已经脱离了概率方法可分析的范畴。然而,“贝叶斯们”似乎有着无懈可击的信仰,还在坚持他们的方法是普遍适用的。
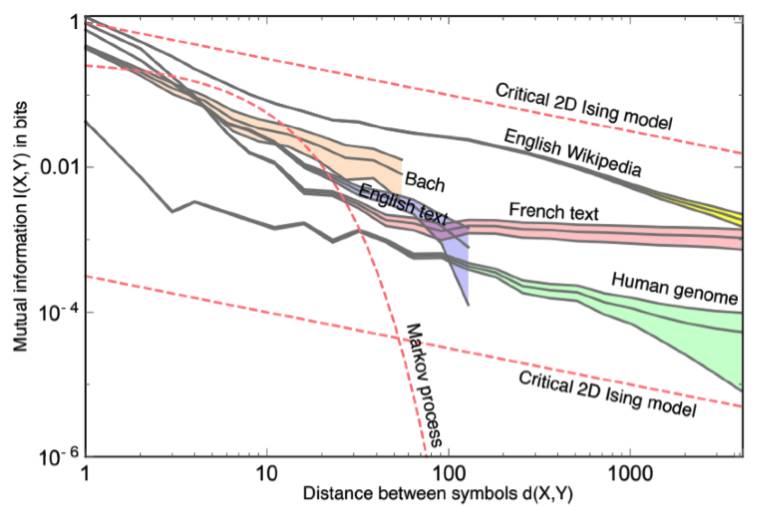
这篇Max Tegmark et al.的论文(链接:https://arxiv.org/pdf/1606.06737v3.pdf)研究了各种语言之间的点互式信息。注意到这里马尔科夫过程(Markov processes)的表现并不好。简而言之,如果你的预测器是无记忆的,那么它就不能预测复杂的行为。
然而我听说有人认为概率归纳法(probabilistic induction)/贝叶斯法则(Bayes rule)在某些领域适用。这样的领域都有哪些呢?Bernard Sheolkopf准确地告诉了你概率归纳法到底适用于哪些领域(链接:http://ml.dcs.shef.ac.uk/masamb/schoelkopf.pdf)。其实就是那些表现出反因果的领域。
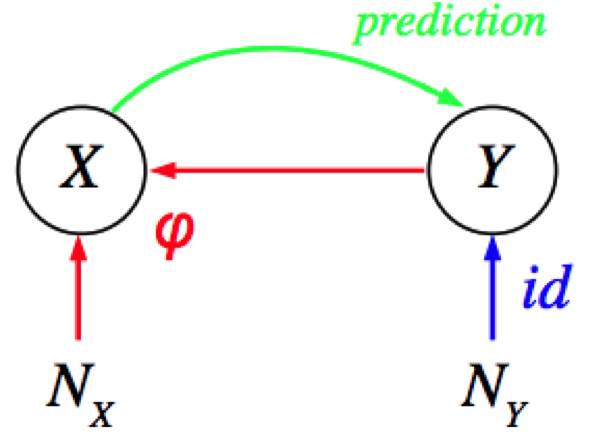
简单地说,由于Y是X(输入)的原因,所以你可以预测Y。因此实际上,关于在哪里能够应用概率归纳法,你得非常小心,即使是对于线性系统也是这样。所以当我们试着应用概率归纳法区分恐龙、星星、椭圆和叉号时,我们发现我们做不到。为什么呢?这是因为观测到的输入(即X)并不是由这里的原因(即Y)直接造成的。也就是说Y不是X的分布的原因。更确切地说,这其中有另一种扰动机制造成了这种混淆。
然而如果你掌握了关于这一扰动机制的输入的信息,那会怎么样呢?
你能利用所生成的分布预测输入吗?答案显然是yes!
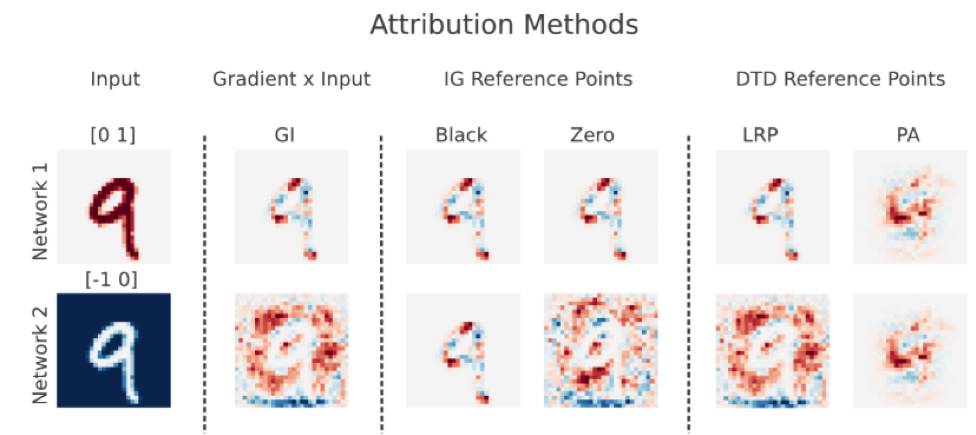
一篇新的论文研究了显著性方法(saliency method)的不可靠性。在深度学习网络中,显著性用于强调对网络预测起到最大作用的输入。它被多次提出以用来解释网络的行为。有趣的是,这篇论文展示了对输入的一个简单变换(即常数变换)会导致归因的失败。
这确实是一个很有趣的发现,同时也揭示了我们对深度学习网络的因果关系的理解还在婴儿阶段。过分地要求贝叶斯推断或概率归纳法作为深度学习网络背后的指导原则只是一个几乎没有什么证据支撑的假设。概率归纳法从来不是自然的基本准则,因此当用它来解释复杂系统的时候,应该小心一些。
在这里我引用Judea Pearl的两段话,把它们送给你:
回顾过去,我所遇到的最大挑战是摆脱概率思维并接受两点:第一,人们并不总是从概率角度思考,而是因果效应的角度思考;第二,因果的思维很难用概率的语言描述,它需要一种属于它自己的正式的语言。
人们并不使用概率思维,这是事实。
第二段话是关于概率和现实的本质:
我现在把因果关系作为物理现实和人类对现实的理解的根本基石,把概率关系看作是推动我们理解世界的因果机制的表层现象。
这段话揭示了物理学家是怎样看待热力学和统计力学之间的关系的。这其中可能会出现的认知偏差是他们不仅仅把那些指标当作是系统的结果,还把他们当作是对系统的解释。更确切地说,不要用概率论去解释复杂的非线性现象,如认知过程。更糟的是,不要把概率方法作为机理来构建你的人工智能机器。如果你手头上的是一个简单不那么复杂的问题,你可以随意使用合适的工具。但尽管你的锯子能够砍树,这并不意味着它就能切割钛。
反馈循环处于智能的核心地位,这就意味着一个循环依赖的非线性系统。概率理论只是一个工具,而非现实或智能系统的基本特征。作为一个工具,它就存在应用领域的限制。因此我们应该谨慎使用这一工具作为理解复杂系统的动力。几十年来人工智能一直艰难前行,也许突破口就在于重新审视和质疑我们自己的科研偏差。
原文地址:https://medium.com/intuitionmachine/why-probability-theory-should-be-thrown-under-the-bus-36e5d69a34c9?source=linkShare-9549803b36be-1510196607
精品课程
数据科学实训营第4期
优秀助教推荐|姜姜
作为一枚对数据分析的理解仅限于Excel的小白,曾经一直认为通过写代码来分析数据是件无比高大上的事。可是,在文摘的数据科学实训营居然就实现了!
手把手的教学方式,助教和同学们热烈的交流讨论,让我慢慢地觉得一行行代码如此亲切。而当把自己头脑中的构思通过代码实现,看到结果的那一刻,真是无比激动!
经过Kaggle、天池的案例的历练,对这些数据比赛也开始兴趣盎然,有没有小伙伴有兴趣一起去玩一玩的?
作为第4期的北美地区助教,寄语各位学员:前方高能,请准备好足够的时间,如果你能按时提交作业,结业时一定脱胎换骨。

志愿者介绍
回复“志愿者”加入我们



往期精彩文章
点击图片阅读






