KDD 2018 | 微软推出用于因果推断的Python库——DoWhy
随着计算机系统在各领域(例如医疗、教育、政府机关)的应用,正确预测并理解这些设备的因果影响是非常重要的。没有A/B测试,建立在模式识别和相关性分析上的传统的机器学习方法,是不足以解释因果推理的。
与用来预测的机器学习库类似,微软研究院推出的DoWhy是一种引起因果思考和分析的Python库,它提供了一个统一的界面进行因果推理,并对许多假设进行自动测试,让非专业人士也能进行推理。该成果在最近举办的KDD 2018上做出了展示,以下是论智对其进行的大概介绍。

在《告别曲线拟合:因果推断和do-Calculus简介》一文中我们讲到,因果推断区分了人们可能想要估计的两种条件分布。在机器学习中,我们通常只会估计一种分布,但在某种情况下,我们可能也需要估计第二种。因果推断关注的是一些基础问题,它能帮我们回答“如果我们对x做了什么,那……”的问题,而这些问题通常需要对照试验和明确的干预措施来解决。
几十年来,社会科学和生物医学中,因果推断方法的使用十分广泛。随着计算机在我们的工作和日常生活中所占比例越来越大,因果关系问题在计算机科学中的重要性也不断增加。为了解决这个广泛的问题,我们推出了一个新的软件库——DoWhy(名称来源于Judea Pearl的do-calculus)。除了为常见的因果推断方法提供一个程序设计界面,DoWhy的设计还是为了显示常被忽略的因果分析假设。所以,DoWhy的特点之一就是会让潜在的假设更容易理解。另外,DoWhy可以进行敏感度分析和其他鲁棒性检查。我们的目的是让人们关注他们在对因果推断做假设时的思考而不是其中的细节
过去几年对因果推断的研究,让我们产生了创造DoWhy的想法,不论是估计推荐系统的影响,还是预测可能的成果,都对此有所启发。在每项研究中,我们总会重复以下步骤:找到正确的辨别策略、设计最合适的估计器、检查鲁棒性,每次都要从头开始。有时,面对大量有关因果推理的材料,进行实证推理就非常困难。想要理解我们的假设并证明它们,是很有挑战性的工作。
所以我们思考,能否创建一个软件库,通过简单的界面进行因果推断。但不幸的是,因果推断取决于对未知数量的估计,这也是因果推断的基本问题。与监督学习不同,我们无法从现有的测试集中得出客观的评估,所以,在因果推断中无法建立即时可用的方法。例如,对任何方法来说,例如新的算法或医疗处理过程,人们可以观察当他们被干预时发生了什么,或不被干预时会发生什么,但无法同时观察两种情况。所以,因果分析和数据生成过程中的假设有着重要的关系。
为了达到我们的目标,我们明白假设应该是因果推断库中最重要的因素。我们在设计DoWhy时考虑了两个指导原则——让因果假设易于理解,同时测试预测对违反假设的鲁棒性。
首先,DoWhy对辨别(identification)和估计(estimation)做了区分。对因果效应进行标人需要对数据生成过程做假设,同时还要从虚拟表示中具体说明目标被估量。估计过程完全是数据问题,所以辨别过程是最耗时的。为了正式表示假设,DoWhy利用贝叶斯图模型框架,从中用户可以详细了解他们想知道的东西,更重要的是,知道他们此前不知道的有关数据生成过程的事。对于估计,我们提供了基于潜在输出框架的方法,例如匹配、分层和辅助变量。使用DoWhy时还有一个“愉悦”的副作用,那就是你会发现看似分散的图模型和潜在输出框架其实是互通对等的。
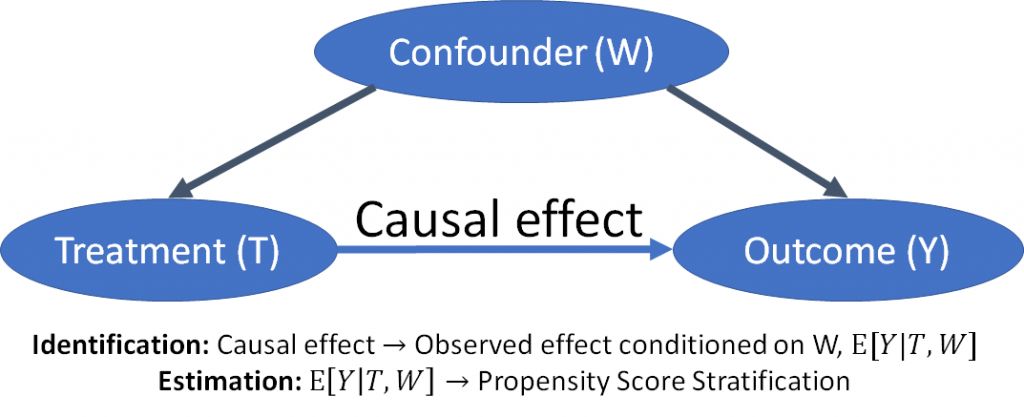
然后,一旦做出了假设,DoWhy会提供鲁棒性检测和敏感性检查,来检查估计的可靠性。由于潜在的假设多种多样,你可以测试估计是如何变化的,例如,通过加入一个新的干扰项或用“安慰剂”进行替换。不论哪种方法,DoWhy库都会基于图模型的假设自动检查得出的估计的有效性。不过我们依然知道自动检测不完美。所以,DoWhy会着重对输出进行解读。在分析的任何阶段,你都可以查看未经测试的假设、经过辨认的被估量以及得出的估计(如果有的话)。
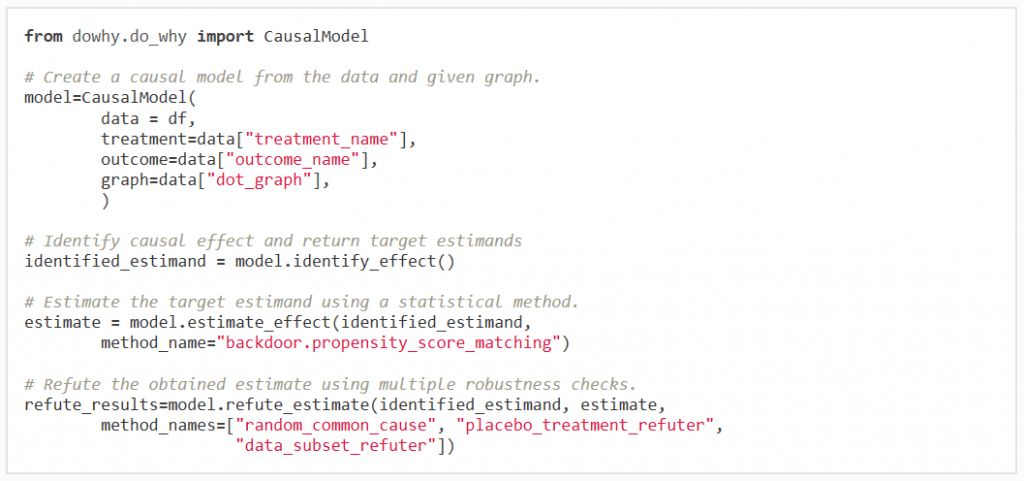
在四行代码中进行因果推断。DoWhy的简单运行
未来,我们期待在库里增加更多特征,包括支持更多的估计和敏感性的方法,以及与其他可用的估算软件进行互通。
Jupyter notebook:causalinference.gitlab.io/dowhy/
原文地址:www.microsoft.com/en-us/research/blog/dowhy-a-library-for-causal-inference/?OCID=msrblogdowhyKDDtw






