干货来袭:漫谈概率统计方法与因果关系

【数据猿导读】 因果关系分析一直以来都是社会经济科学的圣杯,因为社会经济学家关心的不是事物之间如何共同发生的,而是关心事物之间的关系是如何相互传递的
作者 | 数尊数据科学团队
官网 | www.datayuan.cn
微信公众号ID | datayuancn
2017年9月初,人工智能领域的大神级人物Yann LeCun在Cognitive Computational Neuroscience (CCN) 2017上发表了题为《为什么大脑能短时间内学习如此多东西?》的演讲。其中,他表达的对当前业界内概率统计方法应用的隐忧,也许会改变整个人工智能领域的发展方向。简单来说,主流的概率统计方法仅仅是分析的工具,当我们无从窥见或者忽视事件发生的本质,而仅仅关注统计意义上的关系,其结论往往是带有误导性的。但概率统计方法作为工具本没有错,错的是滥用方法草率得出结论的使用者。
在小编看来,LeCun的话大可不必做过多的解读,其实不仅仅局限于人工智能领域,关于概率统计方法的使用的谨慎性讨论早就被各个领域所重视,LeCun的担忧也是特定场景下对方法使用者提出的警醒而不是对概率统计方法敲响的丧钟。为了简明扼要的说明问题,我们绕过复杂的数学证明和枯燥的数值例子,从社会经济学的视角来回顾下关于概率统计方法应用的讨论。
因果关系分析一直以来都是社会经济科学的圣杯,因为社会经济学家关心的不是事物之间如何共同发生的,而是关心事物之间的关系是如何相互传递的。打个简单的比方,假想有一家礼品公司,完全不了解市场的文化习惯,但是他们从大数据发现,每当12月份临近月底的时候公司的礼品销量都会猛增,而过了月底之后数量就会缓慢下降直至正常水平。于是这家礼品公司的市场部门得出一个结论,“我们的礼品销售增量成功诱发了一个叫做圣诞节的特殊日子,我们在未来应该针对这个日期提前做出优化的生产,销售方案”。从预测的角度来看,这么做似乎没有什么错,但是一个社会学家显然不会做出礼品销量的增长引发节庆这样无视因果关系的草率结论。而更多的时候,这个看起来“无害”的预测实际上是有害的。
因为这样的预测成立的条件是,当A导致了B且我们看不到A的时候,用B来估计A。而如果A还没有发生,就用B来预测A,又会怎么样呢?显然,A发生时的B和A事件之前的B是不一样的,因此所谓无害的“预测”(事实上不是对未来的预测,而只是对已发生事件的推断)只存在于我们说的第一种情况,对我们讨论的第二种情况无能为力甚至是有害的。在社会经济学领域,关于这样的讨论非常之多,往往一个谨慎的研究其价值就是成功找到适合的概率统计策略得到正确的因果关系推断。
我们用常用的回归方法为切入来审视这个问题。在回归理论中,最简单的OLS(最小二乘法)的使用必须满足一系列强假设条件,其中一个条件关系到因果关系的推断的正确性,即E(u|X)=0,其数学语言是回归的误差项与输入变量相互独立。当此条件不满足时,就会导致内生性偏差(endogenous bias),见公式1。
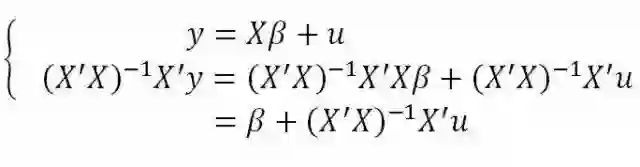
显然,当u不独立于X时:
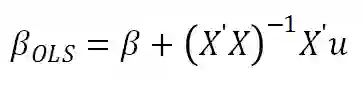
其中等号右的第二项其数学期望不为零,beta参数的最优OLS估计等于真实beta加上一个不为零的偏差项(bias)。那么当u不独立于X意味着什么呢?一般来说有三种可能,1)测量误差(measurement error);2)互为因果(mutual endogeneity);3)不可观测因素同时影响输入(自变量X)与输出变量(因变量y)。我们先跳过第一种情况,重点放在后面两种情况。为了更好的说明问题,小编来举几个栗子:
一个著名的研究是发表在1998年的American economic review 上的文章“Children and their parents' labor supply: evidence from exogenous variation in family size”,作者Angrist (Mostly harmless econometrics作者)and Evans。要解决的问题是研究子女数量对父母的劳动供给的影响。在这个问题里,子女数量与父母劳动力供给的关系也是内生的,为什么这么说呢?因为不仅仅孩子数量多消耗了父母更多的精力以至于降低劳动供给,而劳动供给也会影响父母对孩子数量的选择,况且还有价值观,宗教等许多因素同时影响了劳动力供给与孩子数量。那么Angrist and Evans是如何解决这个问题的呢?他们找到了一个特殊的变量,这个变量叫做工具变量(IV,Instrument variable)。那么这个变量的要求与作用是什么呢?简单说,一个好的工具变量应当是可以有效地解释内生变量X而又只通过内生变量影响y。这么做的结果是什么?当我们用内生变量对IV做回归,并获得这个内生变量在IV上的投影,再放回到原始的回归方程代替原来的内生变量X,因为IV独立于u(且我们知道IV不直接作用于y),因此X在其上的投影也独立于u,所以我们可以发现,beta_ols=beta+0。看,此时beta的OLS估计量等于真实的beta,而原来数学期望不等于零的偏差项的数学期望为零。好了,我们说完理论,那么这个研究高明在哪里呢?就是找到了一个具有说服力的工具变量IV:头两个孩子的性别构成。理论是这样的:父母(当然我们这里说的研究场景是美国而不是中国)一般希望子女性别的构成多样化,所以如果头两胎的孩子性别相同,就会有较高的再生育意愿。而头两胎孩子的性别是完全随机的(姑且这么认为,哪怕美国有些州是允许堕胎的),因此不直接影响父母劳动供给,而只通过数量增加占用父母精力来影响其劳动供给。
类似的有趣研究还有很多,亮点都在于找到一个巧妙的IV变量。我们再结合历史看看这个问题。香港科技大学的龚启圣教授发表的论文“Diffusing knowledge while spreading god's message: Protestantism and economic prosperity in China,1840-1920”中研究了基督教传教对近代中国经济的发展影响。这里学者遇到的问题是传教地区的选择可能与地区经济的自然禀赋相关。那么如何找到一个好的工具变量来识别传教对经济繁荣的贡献呢?龚教授的切入点是一个著名的历史事件:从山东兴起并烧遍中国北方的大部分地区的义和团运动。义和团运动的爆发对传教人员的人身与财产安全带来了巨大的威胁,而运动爆发后鉴于清政府对地方控制能力的降低与义和团运动本身的破坏性,南方诸省地方私自结成联盟保护(东南互保)从北方南逃的传教人员,而不管是义和团的爆发还是东南互保的建立都是独立于地区经济水平的。因此通过东南互保的保护地区识别基督教传教势力的迁徙,进一步识别出传教对地区经济繁荣的影响。可见,如何找到一个具有说服力的工具变量是解释A与B之间因果关系的一个重要方法。这里,我们用一个简单的例子考考大家:当我们想知道粮食产出对价格的影响时,您是否也能找到一个合适的工具变量,既解释了粮食的产量,又不直接影响粮食价格呢?
再回到风控场景下,我们也面临着同样的问题。例如,作为违约行为良好预测依据的负债水平,是风控人员在决策借款人信贷审批时的重要决定因素。然而频繁的举债行为与高违约风险本身都可能是借款人的还款能力变化导致的,又或者是因为借款人的还款意愿发生了变化。因此,过于依赖以负债水平作为新贷款的审批依据就会导致不可观测因素(还款能力变化还是意愿变化?)带来内生估计偏差。因此,为了识别出不同的举债原因,我们没有止步于负债变化这个现象,而是在行为数据中细分出不同的场景,例如我们可以通过借款人的搜索内容来识别还款意愿变化。同时我们也尝试通过收入水平变动来识别还款能力变化。通过这些手段,我们不仅成功地区分了举债行为的原因,更发现了他们导致最终违约行为的不同影响机制,避免了使用因不同原因产生的类似结果来预测违约行为的内生风险。
直到目前为止,我们并没有讨论高深的数学问题,只是应用了简单的概率统计方法避免因为忽视因果关系带来的统计偏差,可见关于概率统计方法导致的谬误信息着实是冤枉了概率统计这个好工具。事实上为了获得因果关系,学者们贡献了大量的研究智慧与精力,发展出五花八门的方法,有如我们之前提到的IV法或DID法,也有更依赖概率统计模型本身达到识别目的的方法。让我们把视角再放大到社会经济学之外更广阔的领域来看概率统计的应用。比如在药物的临床实验设计里,为了获得药物疗效的临床效果统计,实验设计者需要通过各种实验设计手段来保证处理组与对照组之间的可比性,这个可比性的前提就是除了是否给药的事实之外,尽量排除其他干扰因素(著名的Ceteris paribus条件),例如实验样本的选择应当保证尽可能的随机性,使用双盲实验手段排除安慰剂效应与偏见或暗示效应等等手段。通过一系列手段来排除可能对结果产生影响的不可控因素之后才可以获得令人信服的药物疗效统计结果。
可见,这里起到关键作用的不是比较处理组与对照组之间生理指标的t检测,而是其背后科学严谨的实验设计。而回到社会经济学问题或者商业数据挖掘场景来看,正因为我们通常是被动获得数据并加以挖掘,研究者需要面对的数据是远远复杂并且远远“脏”于实验条件下的数据,这就需要研究者在用好概率统计方法的基础上更要对研究或挖掘对象本身拥有更高要求的理解与感悟,否则难免贻笑大方。
注:本文由数尊数据科学团队授权并投递数据猿发布

金猿榜往期的获奖名单,将会在峰会现场隆重发布,期待我们的见面👇






