【泡泡一分钟】Deep MANTA:一个针对单目图像联合2D-3D车辆检测的粗到精的多任务网络(CVPR-29)
每天一分钟,带你读遍机器人顶级会议文章
标题:Deep MANTA: A Coarse-to-fine Many-Task Network for joint 2D and 3D vehicle analysis from monocular image
作者:Florian Chabot, Mohamed Chaouch, Jaonary Rabarisoa, Celine Teuli ´ ere, Thierry Chateau
来源:CVPR 2017
编译:李仕杰
播音员: 王肃
欢迎个人转发朋友圈;其他机构或自媒体如需转载,后台留言申请授权

摘要

今天介绍的文章是“Deep MANTA: A Coarse-to-fine Many-Task Network for joint 2D and 3D vehicle analysis from monocular image”——Deep MANTA:一个针对单目图像联合2D-3D车辆检测的粗到精的多任务网络,该文章将发表在CVPR2017。
在这篇文章里,我们提出了一个新颖的方法叫做Deep MANTA (Deep Many-Tasks)。这个方法是用来对给定图片进行多任务车辆检测。
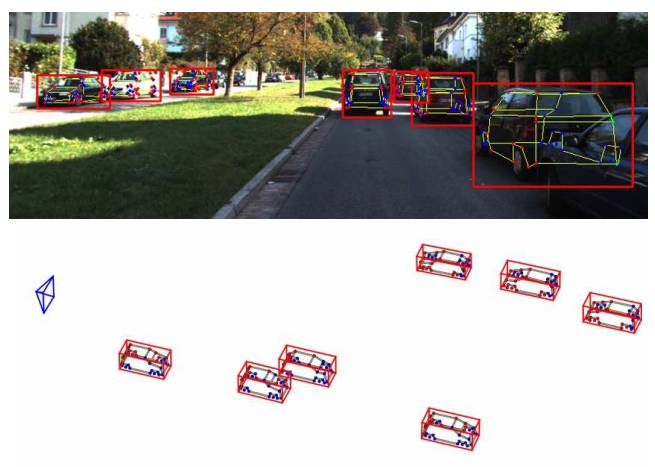
图1.系统输出
一个鲁棒的神经网络在这里被用来同时进行车辆检测,局部定位,视觉可视化和三维估计。它的架构基于一个新的粗到精的物体检测网络以提升车辆检测的准确度。与此同时,Deep MANTA网络可以在图像中定位车辆。即使车辆是不可见的。在推断过程中,网络的输出作为一个鲁棒的实时位姿估计算法的输入,来进行姿态估计和三维车辆定位。
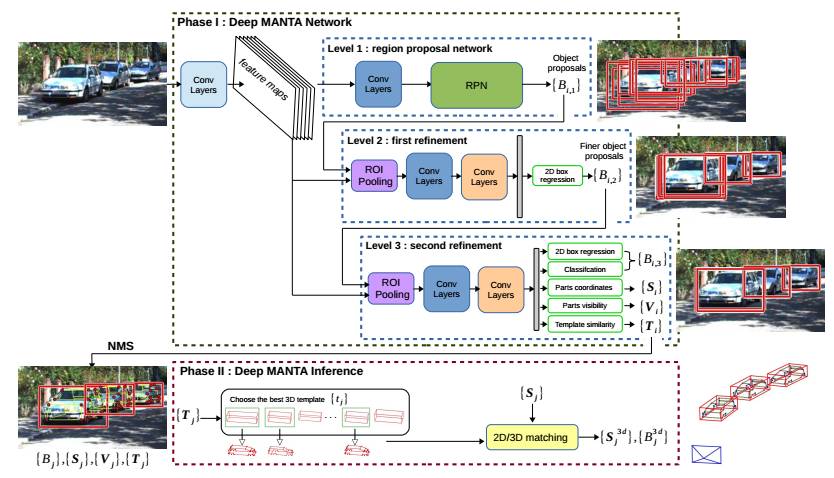
图2.系统架构
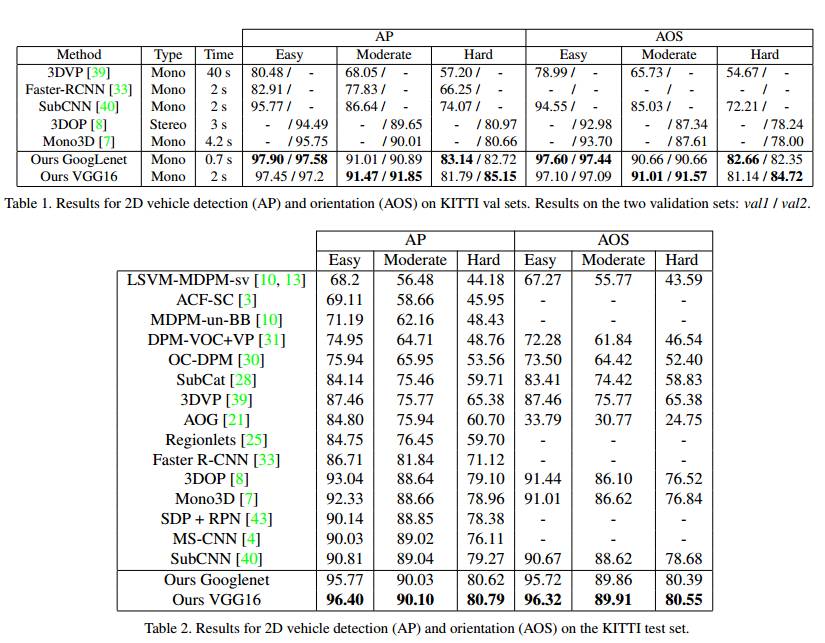
图3.实验结果
我们在实验中展示了我们的方法比其他的单目的state-of-the-art方法在车辆检测,三维定位和姿态估计等几个方面效果要好。我们的实验是在KITTI上进行的。
如果你对本文感兴趣,想要下载完整文章进行阅读,可以关注【泡泡机器人SLAM】公众号。
回复关键字“DeepMANTA”,即可获取本文下载链接。

泡泡机器人SLAM的原创内容均由泡泡机器人的成员花费大量心血制作而成,希望大家珍惜我们的劳动成果,转载请务必注明出自【泡泡机器人SLAM】微信公众号,否则侵权必究!同时,我们也欢迎各位转载到自己的朋友圈,让更多的人能进入到SLAM这个领域中,让我们共同为推进中国的SLAM事业而努力!
商业合作及转载请联系liufuqiang_robot@hotmail.com