我们真的需要那么多标注数据吗?半监督学习技术近年发展历程&典型算法框架演进
加入极市专业CV交流群,与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度 等名校名企视觉开发者互动交流!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 ,回复 加群,立刻申请入群~
即使在大数据时代,获取大批量高质量的标注数据在实际中往往成本高昂。半监督学习技术作为一类可以同时有效利用有标签数据和无标签数据的学习范式,有希望大大降低监督任务对于标签数据的需求。文本从 2013年所提出的 Pseudo-Label 开始,至 2019 年 Google 所提出的 UDA 技术为止,详细介绍了半监督学习近年来的发展历程,重点关注各技术在核心思想、方法论上的演进。文章最后对半监督学习中涉及到的部分关键细节,如领域外数据等问题进行了详细讨论。
-
1 为什么要了解半监督学习
-
2 典型技术方案的演进历程
-
3 部分关键细节的讨论
-
3.1 类别外数据的处理 -
3.2 一致性正则的数学选择 -
3.3 错误标记数据的影响 -
4 总结
1 为什么要了解半监督学习
什么是半监督学习
半监督学习介于监督学习与无监督学习之间。一般而言,半监督学习的任务与监督学习一致,任务中包含有明确的目标,如分类。而所采用的数据既包括有标签的数据,也包括无标签的数据。
简单理解,可以认为半监督学习就是同时运用了标签数据和无标签数据来进行训练的监督学习。当然,在另外一些研究中,带有约束限制的无监督学习也被视为半监督学习,例如受限的聚类算法。
从半监督学习与监督学习的关系出发,我们可以自然得出半监督学习的几个核心点:
-
如何从无标签数据中获取学习信号来指导监督学习? -
如何平衡运用有标签数据和无标签数据各自的学习信号? -
如何选择无标签数据?
这几个核心点正是半监督学习方法需要解决的主要矛盾,同时也是半监督学习思想的精髓所在。本文在后面介绍各个算法时,将会针对这几个核心点做重点介绍。
半监督学习有什么用
我们知道,即使在大数据时代,想要获取到大批量高质量的标注数据在实际中往往是一件很困难的事,需要花费大量的人力和时间。尤其在垂直领域,例如金融、法律、医学等领域,数据的标注还需要业务人员甚至行业专家的参与才能实现相对准确的数据标注,满足业务需求,这使得垂直领域的数据标注成本尤其高昂。
而半监督学习正是为了解决这一类问题而出现的。它的核心目标是,希望通过专家标注的少量有标签数据,结合大量的无标签数据,训练出具备强泛化能力的模型,从而解决实际中的问题。这也正是我们熵简NLP团队探索半监督学习技术的主要动机。
更进一步,半监督学习也是一类更接近于人类学习方法的机器学习范式。试想这样一个场景,我们小时候学习识别小猫、小狗、汽车等等物品时,往往只需要父母进行一两次的指导,我们就能很准确地辨认出什么是猫狗。这背后有一个重要原因是,我们从出生开始就见过很多次小猫、小狗等等动物,虽然还没有人明确告诉过我们这些动物是什么,但我们的大脑已经对于这些事物建立了足够的认识。整个过程抽象出来与半监督学习的思想很相似,父母的指导可视为有标签数据,出生之后的目之所见即为无标签数据,二者结合帮助我们实现快速地学习。
因此,半监督学习技术既是少样本学习的重要路径之一,也有助于帮助我们发展更接近于人类学习范式的机器学习技术。
本文接下来部分重点介绍在深度学习时代,半监督学习技术的发展历程和代表工作。更为全面和基础的介绍,大家可以参考这两本书[1,2],这两本书都出版于2010年之前,基本汇集了半监督学习在前深度学习时代的主要成果。
2 典型技术方案的演进历程
本小节从 2013年所提出的 Pseudo-Label 开始,至 2019 年 Google 所提出的 UDA 技术为止,详细介绍半监督学习近年来的发展历程,重点关注各技术在核心思想、方法论上的演进。
2.1 Pseudo-Label:The Simple and Efficient Semi-Supervised Learning Method for Deep Neural Networks,2013
Pseudo-Label 模型作为一个简单、有效的半监督学习方法早在 2013年就被提出,其核心思想包括两步:
-
第一步:运用训练出的模型给予无标签的数据一个伪标签。方法很直接:用训练中的模型对无标签数据进行预测,以概率最高的类别作为无标签数据的伪标签; -
第二步:运用 entropy regularization 思想,将无监督数据转为目标函数的正则项。实际中,就是将拥有伪标签的无标签数据视为有标签的数据,然后用交叉熵来评估误差大小。
模型整体的目标函数如下:
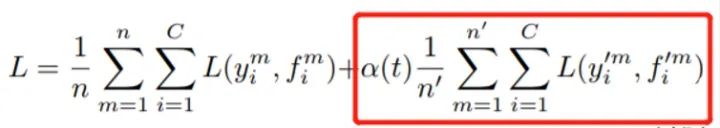
-
其中,左边第一项为交叉熵,用来评估有标签数据的误差。第二项(红框中)即为 entropy regularization 项,用来从无标签的数据中获取训练信号。
为了平衡有标签数据和无标签数据的信号强度,如上所示,算法在目标函数中引入了时变参数 α(t),其数学形式如下:
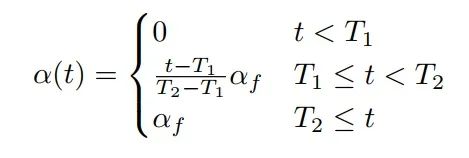
因此,随着训练时间的增加,α(t) 将会从零开始线性增长至某个饱和值,对应无标签数据的信号也将逐渐释放出来。背后的核心想法也很直观,早期模型预测效果不佳,因此 entropy regularization 产生信号的误差也较大,因而 α(t) 应该从零开始,由小逐渐增大。
在实验中,研究人员用 MNIST 数据集进行了实验验证,并尝试了在有标签数据仅为100、600、1000和3000时的情况:
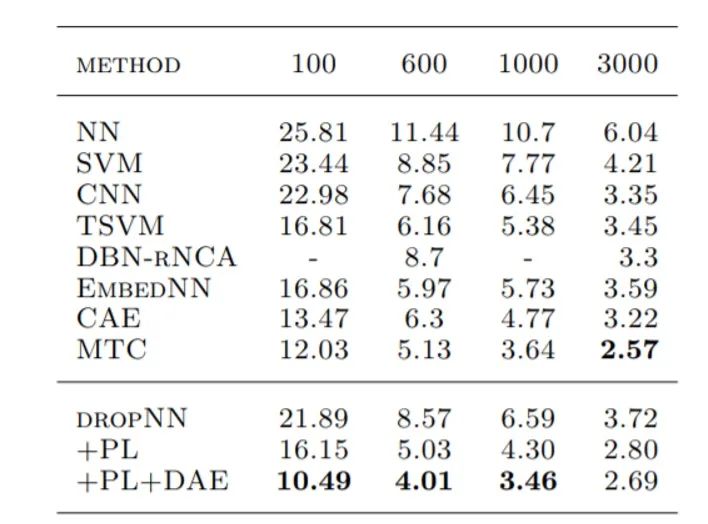
其中,DROPNN、PL 和 PL+DAE 分别是实验中的 baseline 模型、baseline 模型+Pseudo-Label 方法 以及 baseline 模型+Pseudo-Label 方法+ DAE 预训练 方案。
这里我们主要关注Pseudo-Label 方法的效果,其结果如表中倒数第二行所示。从表中可以看出,当有标签数据仅为 600 条时,Pseudo-Label 方法相对于其他公开模型,可以达到最佳的效果。但在其他实验条件下,只能实现相对较好的表现。不过相对于 baseline,此方法在所有情况下均能实现一定的提升。有标签数据量越少,这一提升越明显。这说明 Pseudo-Label 方法确实可以在一定程度上从无标签数据中提取有效信号。
进一步,研究人员通过降维可视化的方式展示了 Pseudo-Label 模型使用前后的效果,实验数据包含 600 有标签数据 + 60000 无标签数据:
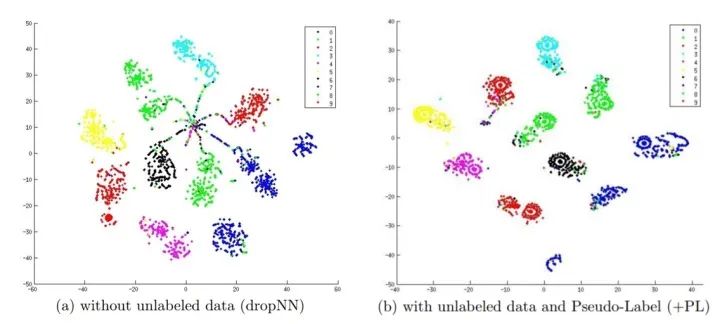
对比上面左右两张图可以看出来, Pseudo-Label 模型相对于单独的有监督模型,可以有效改善各类别数据在空间中的聚集密度。
最后,简单说一下这篇文章存在的明显不足:
-
Pseudo-Label 方法只在训练时间这个维度上,采用了退火思想,即采用时变系数α(t)。而在伪标签这个维度,对于模型给予的预测标签一视同仁,这种方法在实际中存在明显问题。很显然,如果模型对于一个样本所预测的几个类别都具有相似的低概率值,如共有十个类别,每个类别的预测概率值都接近 0.1,那么再以最大概率值对应的类别作为伪标签,是不合适的,将会引入很大的错误信号。
2.2 Γ Model:Semisupervised learning with ladder networks,2015
Γ Model 是 2015年提出的一类基于 Ladder Network 的半监督学习框架。这一模型的核心思想是由无监督学习及表示学习发展而来。作者认为无监督学习和监督学习存在一定程度的冲突,前者希望模型尽可能保留原始信息,而后者则主要保留与监督任务相关的信息,对于其他与任务无关的特征,模型并不关心。因此,半监督学习算法需要同时兼顾这两方面的需求。
在此基础上,作者通过改造 Ladder Network 来实现半监督学习,整体的网络结构如下图所示:
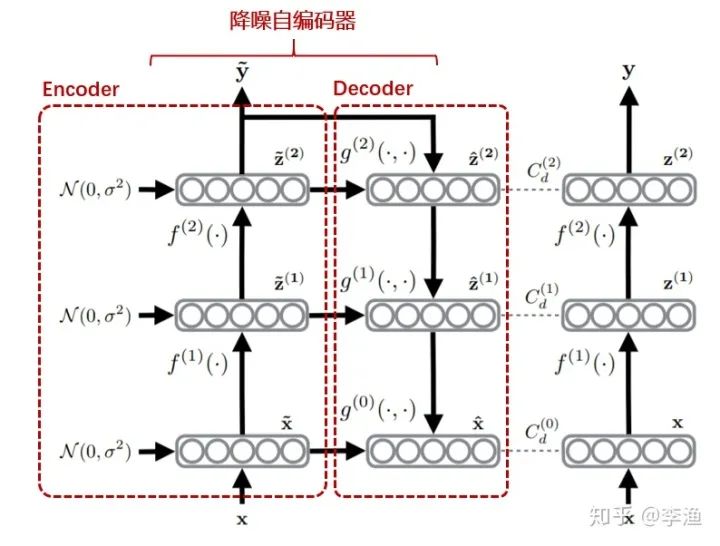
整个网络由两个部分构成,分别是降噪自编码器(Encoder+Decoder)以及无噪的前向网络(网络结构一般与 Encoder 部分一致)。此处不对网络细节做详细介绍,主要给出其中的核心思想:
-
对于有标签数据,数据只会流经降噪自编码器的 Encoder 模块,并通过顶层的输出与原始输入构建有监督的目标函数。 -
对于无标签数据,数据经过 Encoder 模块实现了加噪编码,随后经过 Decoder 模块进行逐层解码,并获取到一系列隐层表示,分别是 、 等。另一方面,最右侧无噪的前向网也会对原始无标签数据进行逐层编码 、 等,这正是 Decoder 模块对应隐层的目标值。通过最小化二者的均方误差,即可从无标签数据中提取到学习信号。
由此可以看出,作者通过上述的网络设计,实现了有监督和无监督的部分分离,从而解决前面提到的冲突。最终的目标函数如下所示:
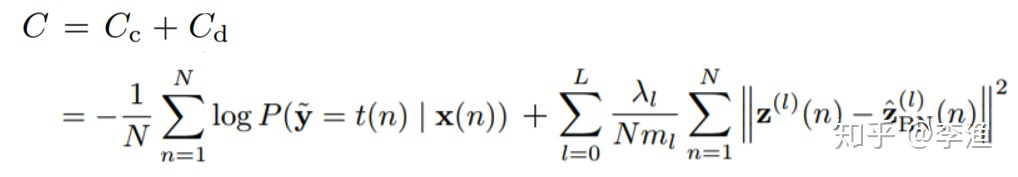
其中,左边第一项为有标签数据的loss项,而第二项则为无标签数据的loss项。
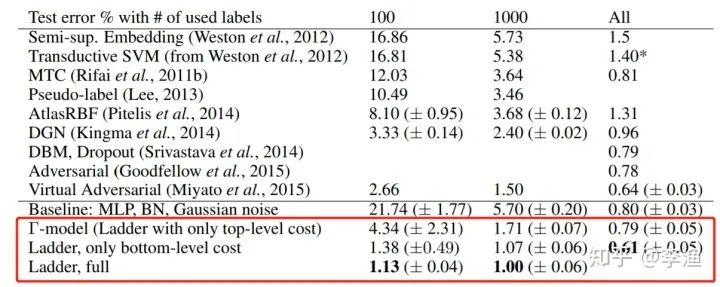
上图给出了该模型在 MNIST 数据集的实验结果。从图中可知,无论是在全数据集下,还是在 100 条的极少数据集下,本研究所提出的模型与一众其他模型相比,表现都是最优的。其中也包括2.1中提到的 Pseudo-Label 模型。尤其值得一提的是,Ladder 仅仅采用了不到 1% 的有标签数据就实现了 1% 的错误率,比完整数据集相比,仅低了 0.5%。
2.3 Π Model & Temporal ensembling Model:Temporal ensembling for semi-supervised learning,2017
这篇研究工作由 NVIDIA 的研究小组完成,其中包含两个半监督算法框架,分别是 Π Model 和 Temporal ensembling Model,二者都可以认为是 Γ Model 的简化版。剔除了 Γ Model 中各种繁复的设计之后,本论文保留了最核心的思想:利用一致性正则(Consistency Regulation)从无标签的数据中提取有效信号。
一致性正则表达了设计者对于模型这样一种先验,即网络在输入数据的附近空间应该是平坦的,即使输入数据发生微弱变化,模型的输出也能够基本保持不变。
这里先介绍 Π Model 的核心思想:

如上图所示,Π Model 包含两个核心点:
-
第一:对每一个参与训练的样本,在训练阶段,进行两次前向运算。此处的前向运算,包含一次随机增强变换和一次模型的前向运算。由于增强变换是随机的,同时模型采用了 Dropout,这两个因素都会造成两次前向运算结果的不同,如图中所示的两个 zi。 -
第二:损失函数由两部分构成,如下图所示。第一项由交叉熵构成,仅用来评估有标签数据的误差。第二项由两次前向运算结果的均方误差(MSE)构成,用来评估全部的数据(既包括有标签数据,也包括无标签数据)。其中,第二项含有一个时变系数,用来逐步释放此项的误差信号。此处的第二项即是用来实现一致性正则。
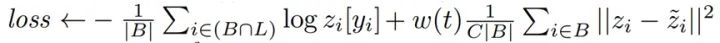
对于 Temporal ensembling Model,其整体框架与 Π Model 类似,在获取无标签数据的信息上采用了相同的思想,唯一的不同是:
-
在目标函数的无监督一项中, Π Model 是两次前向计算结果的均方差。而在 temporal ensembling 模型中,采用的是当前模型预测结果与历史预测结果的平均值做均方差计算。
相对于 Π Model,这种做法有两方面的好处:
-
用空间来换取时间,在相同 epoch 的情况下,总的前向计算次数减少了一半,因而训练速度更快; -
通过历史预测做平均,有利于平滑单次预测中的噪声。
接下来看一下实验结果:
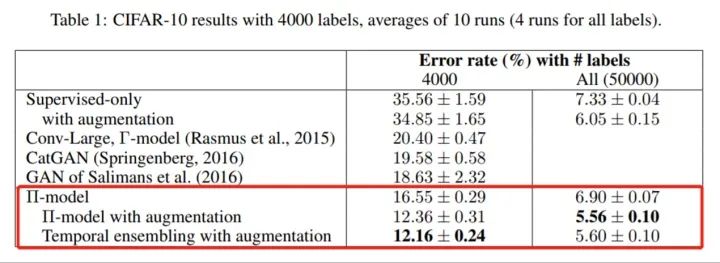
研究人员分别在 CIFAR-10 和 SVHN 数据集上进行了实验。从图中可以看出,对于 CIFAR-10 数据集上,在仅有 10% 的样本下(左边一列),相对于纯监督或者 GAN 的模型,文章所提出的两个算法模型提升了 23~6个百分点不等。即使在完整数据集下,此论文所提出的方法也比纯监督的方法更优,额外提升 0.5 个百分点。这说明本文所采用的一致性正则项完全可以充当通用的正则项,用来约束模型对于输入的局部噪声不敏感。
文本同时对于半监督学习中的其他细节,如错误标签数据的影响、类别外数据的影响等,进行了分析研究,这一部分的结果统一放在第三部分进行讨论。
2.4 VAT:Virtual Adversarial Training: a Regularization Method for Supervised and Semi-supervised Learning,2017
在 Temporal ensembling Model 被提出的同年,日本的研究人员从对抗训练的角度出发,提出了 VAT 算法。这一算法的出发点与 Temporal ensembling Model 基本一致,即模型所描述的系统应该是光滑的,因此当输入数据发生微小变化时,模型的输出也应是微小变化,进而其预测的标签也近似不变。
VAT 与 Temporal ensembling Model 的不同之处在于,后者采用数据增强、dropout 来对无标签数据施加噪声,而前者施加的则是模型变化最陡峭方向上的噪声,即所谓的对抗噪声。在作者看来,如果模型在对抗噪声下,依然能够保持光滑,那么整个网络就能够表现出很好的一致性。
在此思路下,VAT 的目标函数与 Temporal ensembling Model 类似,包含有标签数据部分的交叉熵,以及无标签数据部分的一致性正则项。此处一致性正则项的数学形式如下:
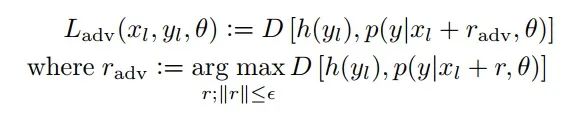
其中,r_adv 代表对输入数据所施加的对抗噪声,而 D 则是 模型对于施加噪声前后两个输入对应输出的非负度量。在 Temporal ensembling Model 中,此项为 MSE,而此处的 VAT 则采用了 KL 散度,即:
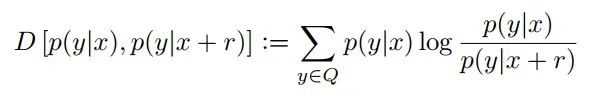
接下来,研究人员在目标函数中加入了第三项 entropy minimization 项,即要求模型无论对于有标签数据还是无标签数据,都要求其熵尽可能小。这个正则项正是 Pseudo-Label 模型中的第二项(红框部分):
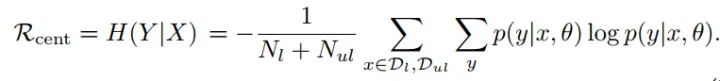
为了表述方便,目标函数中加了第三项的模型,被称为 VAT + EntMin 模型。
简单总结一下,VAT + EntMin 模型的目标函数共包含三项,分别是 有标签数据的交叉熵,施加噪声前后的无标签数据经模型输出后的KL散度,以及 entropy minimization 项。
接下来看一下实验结果:
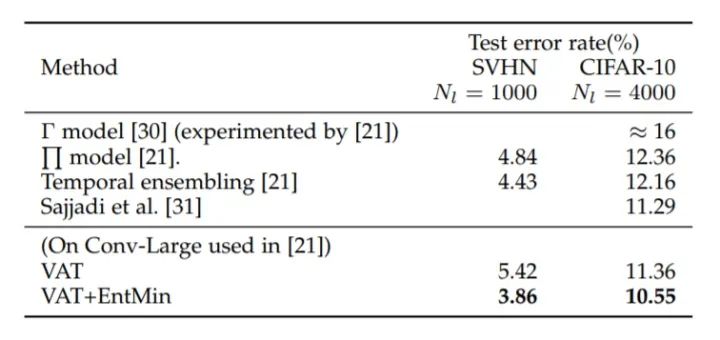
为了和其他半监督学习方法进行对比,研究人员分别在 SVHN 和 CIFAR-10 数据集上进行实验验证。从上表中可以看出,单独的 VAT (目标函数仅包含前两项)与 Temporal ensembling Model 在两个数据集上互有胜负,这取决于具体的数据集特征。而对于 VAT + EntMin 模型,在两个数据集下,相对于其他模型都是最优表现,且平均比第二名高出接近一个百分点。
以上的结果说明,VAT 所用到的 一致性正则 和 最小熵正则 对于从无标签数据中挖掘信息提升模型泛化能力,都有显著的作用。
2.5 Mean Teacher:Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results,2018
Mean Teacher 模型是由芬兰的一家AI初创公司在2018年提出,该模型是在 Temporal ensembling Model 的基础上发展而来,其核心出发点仍然是一致性正则,前面已经提到两次,此处不再赘述。
Mean Teacher 模型主要想解决 Temporal ensembling Model 的一个突出问题,即无标签数据的信息只能在下一次 epoch 时才能更新到模型中。由此带来两个问题:
-
大数据集下,模型更新缓慢; -
无法实现模型的在线训练;
这一模型的核心思想是:
-
模型既充当学生,又充当老师。作为老师,用来产生学生学习时的目标;作为学生,则利用教师模型产生的目标来进行学习。而教师模型的参数是由历史上(前几个step)几个学生模型的参数经过加权平均得到。
因此,Mean Teacher 模型的目标函数的第二项为:
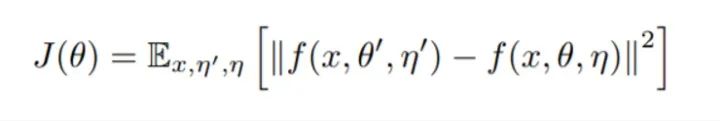
其中,模型参数 θ 的更新方式为:
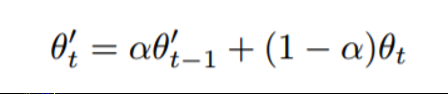
注意,当 α=0 时,Mean Teacher 模型与 Π 模型在形式上等价;
由此可知,Mean Teacher 模型与 temporal ensembling 模型相比,主要区别及优势是:
-
在 temporal ensembling 中,无标签数据的目标标签来自模型前几个epoch预测结果的加权平均。而在 Mean Teacher 中,无标签数据的目标标签来自 teacher 模型的预测结果。 -
由于是通过模型参数的平均来实现标签预测,因此在每个step都可以把无标签中的信息更新到模型中,而不必像 temporal ensembling 模型需要等到一个 epoch 结束再更新。这一特点使得这一算法可以用在大数据集以及在线模型上。
接下来看一下实验结果:
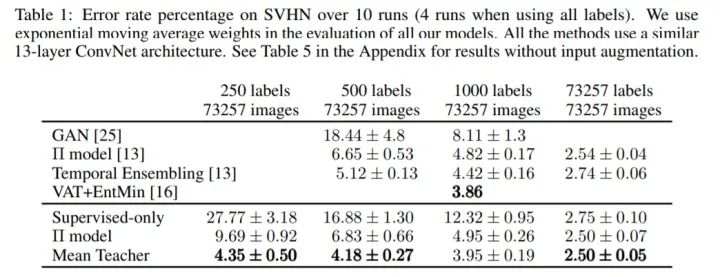
上图是在 SVHN 数据集上的实验结果,有几点重要结论:
-
随着标签数据的逐步减少,Mean Teacher 技术相对于纯监督模型带来的提升越来越显著,最佳情况下可以实现 22 个百分点的提升; -
对比完整标签集和250个标签集的情况,Mean Teacher 技术仅仅利用了不到 1% 的标签数据,就实现了 4.3 的错误率,仅比全标签集低 2 个百分点,这一点在数据标注昂贵的场景下很有价值。 -
与其他技术方案相比,在某些情况下,Mean Teacher 技术 没有 VAT 的方案表现优秀。对于这一点,论文作者也提到,由于两个方案切入维度不同,因而二者完全可以互补,从而带来更大的模型提升。
2.6 MixMatch: A Holistic Approach to Semi-Supervised Learning, 2019
时间到了 2019 年,Google 的研究团队先后提出了两个半监督学习技术,分别是 MixMatch 和下面一小节要介绍的 UDA 技术。
MixMatch 可以认为是近几年半监督学习技术的集大成者,融入了前面提到 Consistency Regulation、伪标签思想、entropy regularization 以及 MixUp 技术,最终实现了显著优于之前半监督学习技术的效果。
MixMatch 技术的核心思想包括两点:
-
伪标签生成:相对于早期的 Pseudo-Label 模型,MixMatch 做了两点改进。第一,运用数据增强技术对无标签数据进行K次的变换,模型分别对 K 次变换进行预测,然后取这K次结果的平均作为无标签的期望结果。第二,在此基础上,运用 entropy regularization 思想,对于K平均之后的结果,再进行锐化操作,使得各类别上的概率值差别更为明显。整体流程如下图所示:
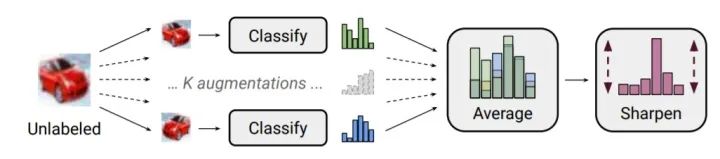
-
数据的 MixUp 变换:MixUp 会按照一定比例将有标签的数据和无标签的数据进行混合以构成新的样本对。MixUp 变换本身可以视为一种正则化技术。直观来看,它要求,当模型的输入为另外两个输入的线性组合时,其输出也是这两个数据单独输入模型后,所得输出的线性组合。学过信号与系统的同学应该知道,这其实就是要求模型近似为一个线性系统。
MixMatch 技术的目标函数与上述的 Π Model 接近:
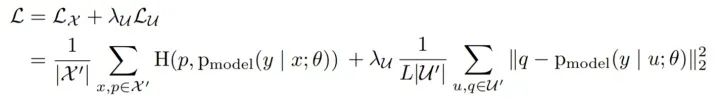
其中,第一项为交叉熵,用于计算有标签数据的误差;第二项为 MSE,用来计算无标签数据与伪标签之间的均方误差,对应前面提到的 Consistency Regulation。
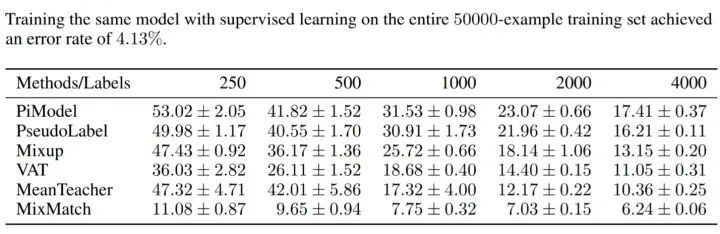
上图是 CIFAR-10 数据集上的实验结果。从图中可以看出,MixMatch 技术显著优于先前的半监督技术,尤其有标签数据量少的情况下,MixMatch 的优势尤其明显。例如在仅有 250 条有标签数据下,MixMatch 的表现相对于第二名高了近 25 个百分点。
此外,研究人员运用控制变量法对于 MixMatch 中用到的各类技术进行单独研究,结果如下图所示:
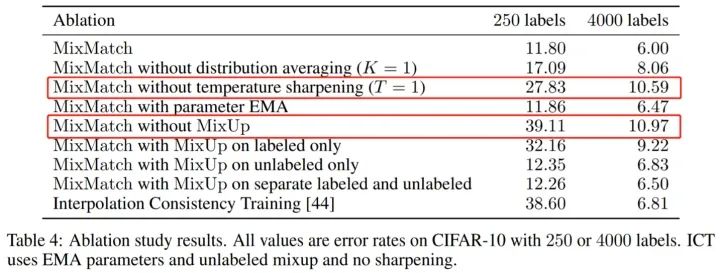
图中红框标记的两个部分,自上而下分别代表着 在伪标签中运用锐化操作 以及 MixUp 操作 对于模型错误率的影响。从中可以看出,锐化 和 MixUp 作为本模型的核心思想之一,对于模型性能起着决定性的作用。
2.7 Unsupervised Data Augmentation for Consistency Training, 2019
UDA 在19年刚被提出来时,吸引了一大波关注,主要原因有两个:
-
效果足够惊人。在 CV 上,超越了包括 MixMatch 在内的一众半监督学习框架,成为新的 SOTA 技术。在文本分类问题上,仅用20条有标签数据,就超过了有监督学习下采用2.5万完整标签集的情况。 -
Google 出品。
而 UDA 的训练框架本身又足够简单,整体框架如下图所示:
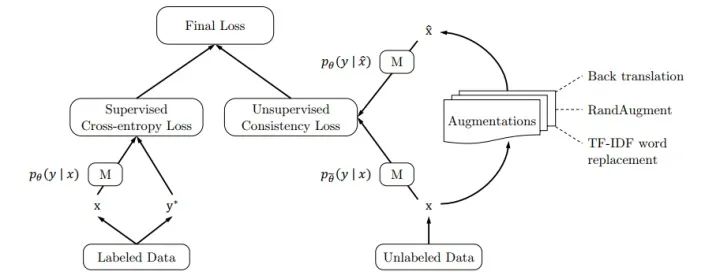
从上图可知,UDA 与 15 年就提出的 Π Model 在算法框架基本一致,唯一的区别在于,在无监督loss中,UDA 采用了 KL 散度来度量差异,而 Π Model 采用了 MSE 来度量。而且目前看起来,用 MSE 会更优。关于这一点,本文会在第三部分进行了详细讨论。
既然在算法框架上并没有太大改进,为何 UDA 可以脱颖而出,成为新的 SOTA 技术。我们认为大概有以下三点原因:
-
采用了最先进的数据增强技术,在CV上运用了19年刚被提出来的 RandAugment,在NLP上则综合运用了 Back Translation 和 非核心词替换。这些技术可以保证无标签数据在语义不变的情况下,极大地丰富数据的表现形式。这使得 Consistency Regulation 可以从无标签数据中更有效地捕捉到数据的内在表示,这一点是早前如 Π Model 所无法实现的。 -
采用了最新的迁移学习模型。在文本分类任务上,研究人员采用 BERT-large 作为基础模型进行微调,由于 BERT 已经在海量数据上进行了预训练,本身在下游任务上就只需要少量数据,再与 UDA 合力,因而可以在 20条有标签数据上实现 SOTA 的表现。 -
采用了一系列精心设计的训练技巧。这包括平衡控制有监督信号和无监督信号的 TSA 技术,基于 Entropy Regularization 的锐化技术,无标签数据的二次筛选 等等。这些技巧或许是打败同年出生的 MixMatch 的主要原因。
由此可知,UDA 与前面提到几个半监督模型相比,本身在半监督学习框架上并没有太大的创新,其贡献更多的是将近年来深度学习领域其他的新技术和新思想结合进半监督学习中。
最后,我们看一下 UDA 的实验效果:
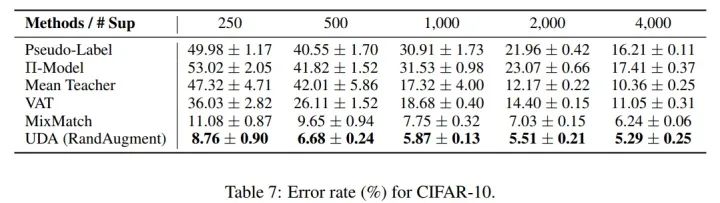
为了和前面的技术做对比,这里展示了 UDA 在 CIFAR-10 上的实验结果。从表中可知,UDA 在 MixMatch 的基础上又往前走了一步。尤其在少标签数据的情况下, UDA 技术相对于其他技术具有不可比拟的优势。
从 MixMatch 和 UDA 的实验结果来看,深度学习时代的半监督技术似乎已经具备了与监督学习相比拟的优势。那么,半监督学习在面临真实问题时,是否依然可以发挥出独特的优势,有效降低对于标签数据的需求,我们拭目以待。
3 部分关键细节的讨论
文本的第二部分对过去几年中典型的半监督学习技术进行了详细介绍,重点放在了算法框架、核心思想的梳理。实际上,在算法的实践过程中,有一些关键细节对于算法最终的效果有着很大的影响,我们统一在这一部分对其中的部分关键细节进行详细讨论。
类别外数据的处理
在真实场景中,由于无标签数据没有经过人工筛选,因此数据中不可避免地会混入类别外的数据甚至领域外的数据。这些类别外的数据给模型带来的潜在影响是我们在面临真实问题时,必须要仔细处理的问题。
在 Temporal ensembling Model 这篇论文中,研究人员对比了引入类别外的无标签数据和类别内的无标签数据对于模型的影响,实验结果如下图所示:

其中,左右两列分别对应着引入类别外和类别内数据各自的实验结果。从实验结果来看,无标签数据是否是类别内数据对于模型的表现没有显著影响。
但是,更多的研究认为,如果无标签数据中混入了类别外的数据,会导致模型的表现下降,因此在实际中应该注意对无标签数据进行筛选[8-10]。
前面提到的 UDA 技术对于类别外无标签数据的筛选提供了一个简单有效的处理方式:
-
运用当前训练的模型对于无标签数据进行类别预测,只保留那些预测概率值超过一定阈值的无标签数据。对于这一部分数据,可以认为其分布特征与当前类别具有较高的相关度,因此可以参与训练。
一致性正则的数学选择
从第二部分的分析可以看出,一致性正则 (Consistency Regulation) 是半监督学习技术用来从无标签数据中提取信号的主要方法之一。自然,对于其数学形式的选择值得我们专门讨论。
从前面提到的几类典型半监督技术来看,一致性正则的数学形式大致分为两种:
-
一种是 MSE,对应的半监督框架有:Π Model,Temporal ensembling Model,Mean Teacher,MixMatch -
一种是 KL 散度,对应的半监督框架有:VAT,UDA
文献[5]对于这两种形式进行了对比研究,实验结果如下:
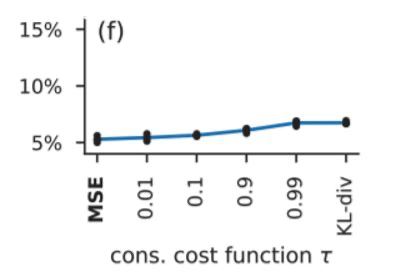
从上图的结果可知,至少在这个实验中,MSE 的表现优于 KL 散度两个百分点。对于这背后的原因,一个直观的解释是,相对于 KL 散度,MSE 的计算方式使得模型对于无标签数据的预测错误,敏感度更低。
我们的建议是,MSE 和 KL 散度各有优劣,二者的选取与数据集的实际分布特征关系很大,在实践中不妨进行对比测试。
错误标记数据的影响
在实际中,数据的标签很难保证绝对的正确,因此更一般的情况是,标签数据中总会混有一定比例的错误标签数据,那么这部分错误标签数据对于模型的影响在半监督学习框架下到底有多大,也是一个很有意思的问题。
Temporal ensembling Model 这篇论文对这一问题也进行了对比实验:
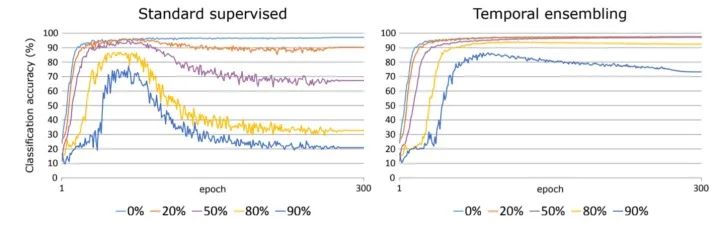
研究人员以 SVHN 数据集作为研究对象,对数据的原始标签进行了不同比例的随机打乱,之后测试模型在纯监督和半监督框架下的表现。
左边这张图展示了标准监督方法的表现。可以看出来,模型对于标签的准确性很敏感,即使只有 20% 的数据标签被打乱,模型的性能也会下降10%。
右边则展示了 temporal ensembling 的表现。这一模型对抗标签的错误标注是惊人的。从图中可以看出来,即使有一半标签是错误的情况下,模型最终的表现也与无错误的情况一致。即使在 80% 标注错误的情况下,其模型的错误率也下降不到 10%。
上述的结果好到令人质疑,文章作者对于这一现象的解释是:一致性正则 可以充分利用所有数据的信息(包括有错误标签的数据),使得网络的函数在输入数据的附近空间平坦。而目标函数中针对有标签数据的交叉熵,则是将输入映射到具体的类别上。因此,前者用来平滑网络,后者通过正确的标签将各个流形关联到具体的类别上。二者结合,可以有效抵抗错误的标签。
这样的解释显然还不足以让人信服,我们将在后续的研究中对这部分工作进行详细的实验,有兴趣的同学也可以自己动手试一试。
4 总结
文本首先介绍了半监督学习的概念及其应用场景,接下来详细介绍了2013年至2019年之间,几类典型的半监督学习技术在算法框架和核心思想上的演进,最后对半监督学习中涉及到的部分关键细节,如领域外数据等问题进行了详细讨论。希望本文对于半监督学习技术在产业中的应用落地有所帮助。
最后,再对半监督学习技术做一点讨论和总结:
-
第一,在半监督学习框架中,从无标签数据中提取有效信号的一般思路可以概括为:在保证语义不变的情况下,运用加噪、数据增强等手段对无标签数据进行变换,然后通过一致性正则等方法来约束模型对于变换前后的数据保持不变性,进而从中提取出信号。 -
第二,与半监督学习相关的正则技术至少有两类,分别是 Entropy Minimization 和 Consistency Regulation。前者要求模型的决策边界不应该穿过数据分布的高密度区域,后者要求模型应该是光滑的,当输入数据发生微弱变化时,模型的输出也近似不变。 -
第三,在第二部分提到研究中,除了UDA以外,其他模型的实验都集中在图像问题上。因此,在NLP的应用问题上,目前仍然有大量工作值得探索。
参考文献
[1] Zhu, Xiaojin, and Andrew B. Goldberg. "Introduction to semi-supervised learning." Synthesis lectures on artificial intelligence and machine learning 3.1 (2009): 1-130.
[2] Chapelle, Olivier, Bernhard Scholkopf, and Alexander Zien. "Semi-supervised learning (chapelle, o. et al., eds.; 2006)[book reviews]." IEEE Transactions on Neural Networks 20.3 (2009): 542-542.
[3] Lee, Dong-Hyun. "Pseudo-label: The simple and efficient semi-supervised learning method for deep neural networks." Workshop on challenges in representation learning, ICML. Vol. 3. 2013.
[4] Rasmus, Antti, et al. "Semi-supervised learning with ladder networks." Advances in neural information processing systems. 2015.
[5] Laine, Samuli, and Timo Aila. "Temporal ensembling for semi-supervised learning." arXiv preprint arXiv:1610.02242 (2016).
[6] Miyato, Takeru, et al. "Virtual adversarial training: a regularization method for supervised and semi-supervised learning." IEEE transactions on pattern analysis and machine intelligence 41.8 (2018): 1979-1993.
[7] Tarvainen, Antti, and Harri Valpola. "Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results." Advances in neural information processing systems. 2017.
[8] Berthelot, David, et al. "Mixmatch: A holistic approach to semi-supervised learning." Advances in Neural Information Processing Systems. 2019.
[9] Xie, Qizhe, et al. "Unsupervised data augmentation for consistency training." (2019).
[10] Oliver, Avital, et al. "Realistic evaluation of deep semi-supervised learning algorithms." Advances in Neural Information Processing Systems. 2018.
[11] Sajjadi, Mehdi, Mehran Javanmardi, and Tolga Tasdizen. "Regularization with stochastic transformations and perturbations for deep semi-supervised learning." Advances in neural information processing systems. 2016.
推荐阅读

添加极市小助手微信(ID : cv-mart),备注:研究方向-姓名-学校/公司-城市(如:目标检测-小极-北大-深圳),即可申请加入极市技术交流群,更有每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、行业技术交流,一起来让思想之光照的更远吧~

△长按添加极市小助手

△长按关注极市平台,获取最新CV干货
觉得有用麻烦给个在看啦~




