
文本分类,是NLP的基础任务,旨在对给定文本预测其类别。然而,基础任务不代表简单任务:文本来源复杂多样,文本粒度有大有小,文本标签之间也有各种关系。面对各种问题,文本分类,仍在飞速发展中。来自美国弗吉尼亚大学的Kamran Kowsari博士等人,用了68页A4纸的篇幅,从0开始,细致的总结了文本分类近些年的发展,循序渐进,新手友好!
近年来,复杂文档和文本的数量呈指数级增长,需要对机器学习方法有更深刻的理解,才能在许多应用中准确地对文本进行分类。许多机器学习方法在自然语言处理方面取得了卓越的成绩。这些学习算法的成功依赖于它们理解复杂模型和数据中的非线性关系的能力。然而,为文本分类找到合适的结构、体系和技术对研究人员来说是一个挑战。本文简要介绍了文本分类算法。本文概述了不同的文本特征提取、降维方法、现有的分类算法和技术以及评估手段。最后,讨论了每种技术的局限性及其在实际问题中的应用。
成为VIP会员查看完整内容


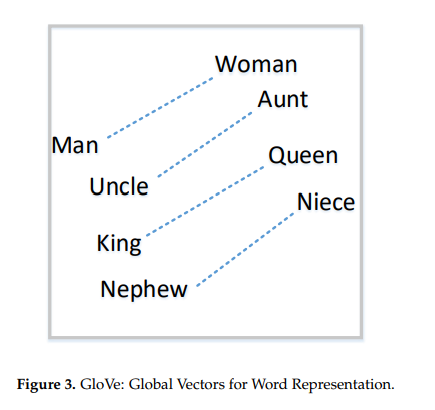
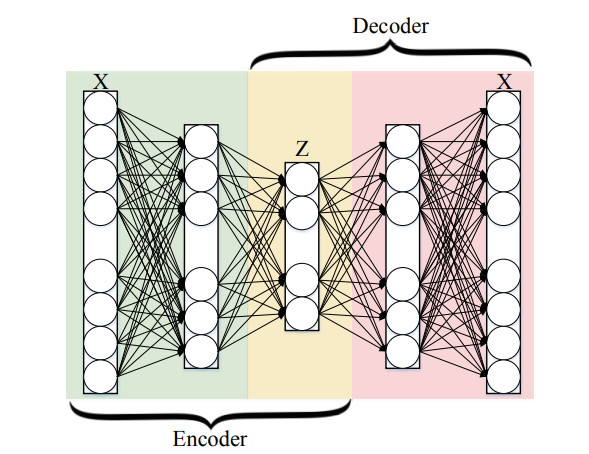
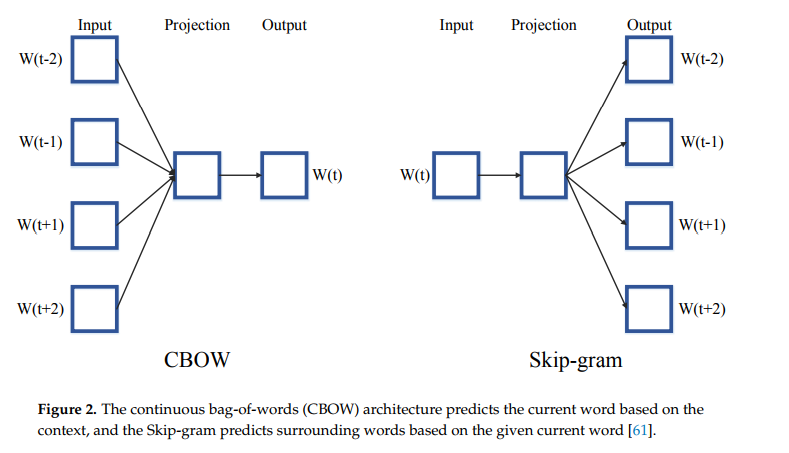
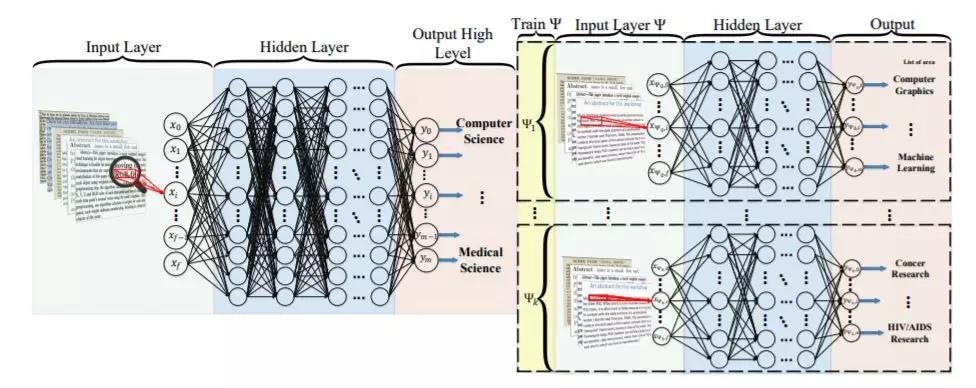
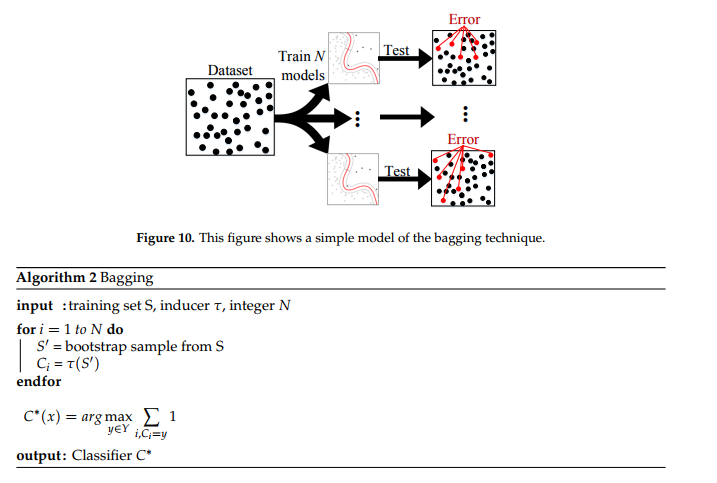
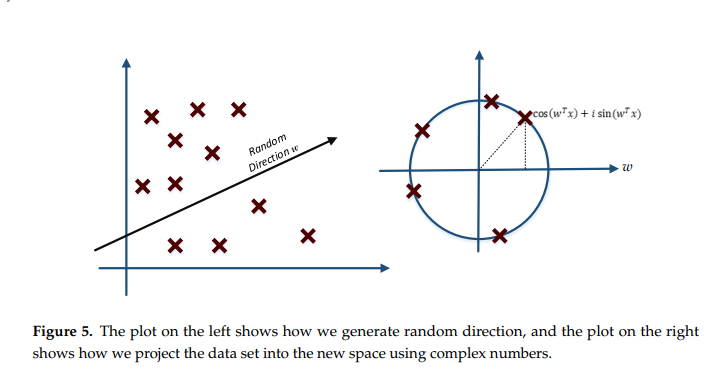
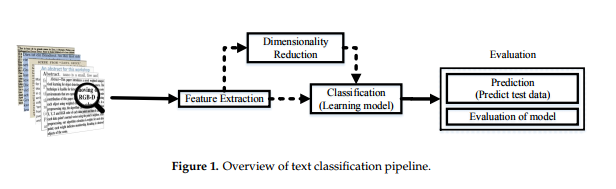
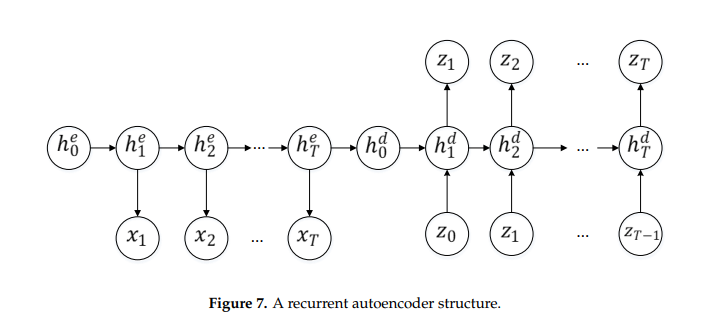
相关内容
Arxiv
20+阅读 · 2020年3月10日
Arxiv
5+阅读 · 2019年11月1日



相关VIP内容
相关资讯
相关论文
Arxiv
20+阅读 · 2020年3月10日
Arxiv
5+阅读 · 2019年11月1日