附资料包|GAN发展历程综述:送你最易入手的几个架构
本文经AI新媒体量子位(公众号 ID: QbitAI)授权转载,转载请联系出处。
怎样教机器画一张从未见过的人脸呢?我们知道计算机可以存储大量照片,但它并不知道像素与外观是如何关联起来的。多年来,各种各样的生成模型都试图解决这个问题。它们使用不同的假设模拟底层数据分布,但那些假设通常并不实用。
目前的实现方法都不是最优解:隐马尔可夫模型生成的文本非常枯燥,由上一句就能预测下一句;变分自编码器(Variational Autoencoders)生成的图像是模糊的,图像之间尽管名称不同,但实际上变化很小,缺乏多样性。
要解决这些问题就要采用一种全新的方法,生成式对抗网络(GAN)应运而生。
在这篇文章中,我们会全面介绍GAN的基础概念,展示其主要架构,并提供大量能显著优化结果的技巧。
GAN的发明
生成模型主要是用来收集训练样本并表示样本的概率分布,解决方案通常是直接推断其概率密度函数。
生成模型的初学者会好奇,既然有这么多真实的训练案例,那为什么还要去找这些生成模型呢? 这里是一些通过好的生成模型可能实现的应用,也可以算作这个问题的答案:
1.模拟实验可能的结果,降低损耗,加快研究速度
2.能够预测未来的行动规划,想象一个GAN能预先知道下一步“路况”
3.生成缺失的数据和标签:缺乏正确格式的清洗的数据会导致过度拟合
4.生成高质量语音
5.照片的自动优化(图像的超分辨率重建)
2014年,蒙特利尔大学的Ian Goodfellow和他的同事创造了生成式对抗网络(GAN)。它可以通过学习生成逼真物体的底层数据分布。
GAN背后的原理很简单,就是生成器和判别器的相互作用。生成器的目标是生成一个逼真的物体,试图以假乱真。判别器的目标是分辨生成图像和真实图像之间的差异。
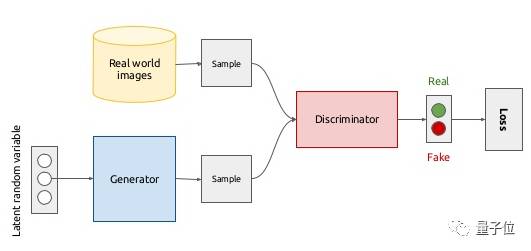
上图是GAN的整体结构。目前最重要的是明白GAN是一种让生成器和判别器协同工作的方法,并且二者都有自己的体系结构。
生成器和判别器
在训练中的每一步,判别器都要辨别训练集中的假图像,所以判别器的判断力会随着训练越来越强。正如统计学习理论中讲到的,这实际上是在学习数据的基本分布。
当生成器足够擅长生成假图像的时,可以骗过判别器吗?答案是肯定的。下面我们看看生成器是如何生成以假乱真的图像的。
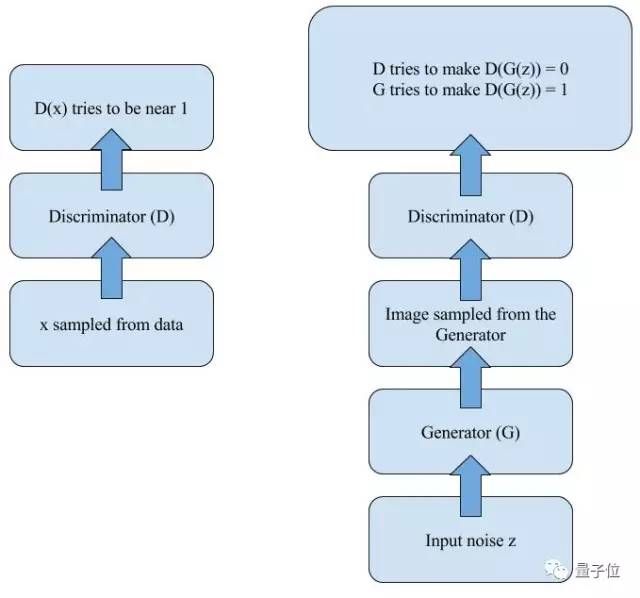
对这个神经网络来说,如果我们训练它的时间足够长,生成器将从样本的真实“分布”中学习,会逐渐生成逼真图像,直到判别器分辨不出图像真假。
有意思的是,量子位之前报道过一篇GAN诞生记,这个目前最火的AI模型竟然来自一群博士的酒后争吵。
最易入手的几个架构
机器学习方面的知识离不开练习,但很多学习者止步于了解理论皮毛。幸运地是,我们找到了一些实用的贴士帮助实践。在这篇文章中,我们先回顾一些GAN的基本架构。
深度卷积生成式对抗网(DCGAN)
Goodfellow的首篇GAN论文发表一年后,大家发现GAN模型不稳定,并且需要大量的技巧。2016年,Radford等人发表了一篇名为《无监督代表性学习与深度卷积生成式对抗性网络》的论文,文中提出了GAN架构的升级版,命名为DCGAN模型。
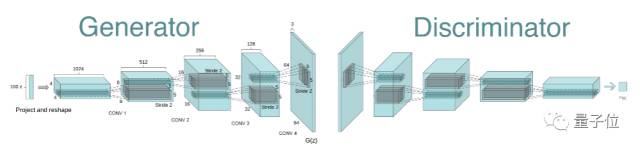
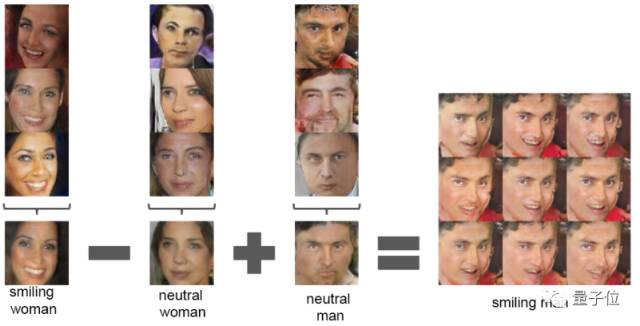
让人欣喜的是,大多数情况下DCGAN架构比较稳定。这是首批证明向量运算可以作为从生成器中学习的固有属性表征的论文,和Word2Vec中的向量技巧类似,只不过是适用于图像的。
DCGAN是我们推荐的入门模型中最简单稳定的。还有一些训练与实现的实用技巧资源,在文章结尾可以查看。
条件生成式对抗网络(Conditional GAN)
条件生成式对抗网络是GAN元架构的扩展形式,它能大幅提高生成图像的质量。如果你有一些数据点的标签,可用它帮助网络构建显著表征。不管使用什么架构,扩展是一样的,都需要向生成器添加另一个输入。
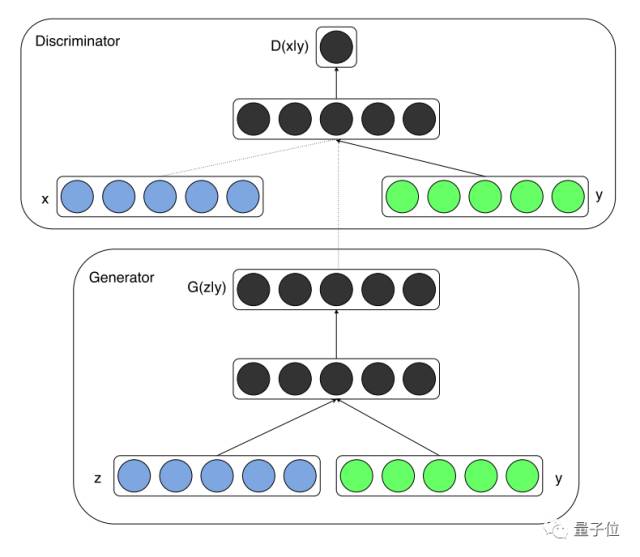
那么,条件生成式对抗网络是怎样应用的?假设你很喜欢猫,而你的模型恰好能生成各种各样的动物。相比把生成噪音传至生成器中,还有一种更好的方法,你可以在第二个输入中加入一些标签或词向量作为猫这个分类的id。在这种情况下,生成器就能根据预设的输入输出特定物体了。
一些技巧
练习是学习GAN不可或缺的一环,仅从论文中学习还是远远不够的。很多时候论文中的方法只适用于论文中的数据集,我们希望提供一组通用工具让入门者直接拿来研究。
一般来说,训练GAN的工作流程简洁明确,大致可分下面三步走:
抽取minibatch的训练示例并估算判别器的评分
生成minibatch的样本并估算判别器的评分
用上两步中累积的梯度完成更新
分别处理训练和生成minibatch并分别计算这些不同批次的batch norm是必要的,可以帮助我们确定判别器的快速初始训练。
下面是一个正确生成minibatch的说明:
在生成器的每一步中判别器运行次数大于1有时是好的,因此,如果您的生成器在有损失函数的情况下能生成出判别器分辨不了的东西,可以考虑这样做。
如果在生成器中使用batch norm层,可能内部批量的强关联,比如下图中的这个例子。

本质上说,每个batch都会产生轻微的变化,怎样避免这种情况发生呢?
一种方法是预计算平均像素和标准偏差并每次都用它,但这种解决方法经常导致过度拟合。因此,我们采用Virtual Batch Norm方法,在开始训练前先定义一个batch R作为参考,对于每个新batch X,利用R和X的关联计算标准化参数。
第二种方法是,从球体而不是立方体中搜集输入的噪音。虽然仅通过控制噪声向量模量就可以实现这种近似,但从高维立方体中均匀采样更可取。
还有一个技巧是避免使用稀疏的梯度,特别是在生成器中。我们可以通过将某些图层转换成“平滑”的类似效果来实现,比如:
ReLU -> LeakyReLU
MaxPooling -> AvgPooling, Convolution+stride
Unpooling ->Deconvolution
相关资料
在这篇文章中,我们解释了生成式对抗模型,并讲解了一些实用技巧。原文中还有一些实现GAN的资料,在七月在线微信公众号(ID:julyedulab)对话界面回复“实现”两个字,可以获得这份学习资源大礼包。
— 完 —
如果
你也想学GAN
下面这个白菜团
必拼啊!
<生成对抗网络>理论+实战带你GAN!





