【机器视觉】张长水:图像识别与机器学习
导读: 6月6日清华人工智能论坛上,张钹院士针对当下浮躁的“人工智能热”,告诫我们要冷静地面对人工智能。王生进教授、张长水教授、郑方教授、微软芮勇、搜狗王小川分别发言。学界泰斗与产业嘉宾精彩的演讲,碰撞出一大批关于人工智能过去、现在、未来的真知灼见。
本文内容选自清华大学自动化系张长水教授于“清华人工智能”论坛上所做的题为《图像识别与机器学习》的演讲。
整理:李柯南
校对:郭芯芮
编辑:张梦
图像识别是人工智能领域非常核心的一个课题。同时从研究的角度来看,机器学习也是人工智能下的一个研究方向。因此,这个题目会更容易引起大家的共鸣。

一、 什么是图像识别?
图像识别是什么?以这张图像为例,第一个问题是:在这个图像里面有没有街灯。在学术研究中,我们把这个问题叫作图像检测。第二个问题就是把街灯的位置给找出来,这叫做定位。第三个问题是物体的分类和识别,指出这是山,这是树,这个是招牌,建筑。我们可能还会对整张图片做一个场景的分类,是在什么环境下拍照的。它可能是一个室外的图像,关于城市的生活等等。基本上这些就是我们在图像识别里面涉及到的一些可能的研究问题。

二、 图像识别有什么应用?
做这些研究可以有哪些用途?比如无人驾驶汽车:如果汽车上有一个带有摄像头的辅助系统,能够识别这个场景下所有的情况,包括车道线,交通标识,障碍物等,这样能够让我们驾驶汽车更方便、更轻松。
另外,一些相机在拍照的时候,在用户摁下快门到一半的时候,相机就会去找到这个图像的人脸在什么地方。找到人脸以后把焦点对焦在脸上,使这个图像能够让人更清楚一点。
还有,我们的计算机里面往往会有成千上万的照片,怎么组织它们,从而用户快速找到一张照片?如果有这样的图像识别系统,我可能会告诉计算机,我要找的照片里有两个人,这个照片是在颐和园照的。
三、图像识别的困难在哪里?
图像识别有很多难点。第一个困难就是它的视点变化很多。当我们对同样一个物体拍照的时候,因为视点不同,得到的图像外观是不一样的。所以对同一个物体这样看或者那样看,看外观非常不一样。但是也许两个不同的物体,外观又可能会很相近。所以这是造成图像识别的一个困难。
第二个难点就是尺度问题。物体在图像中近大远小,这给我们做图像识别会带来一定的难度。
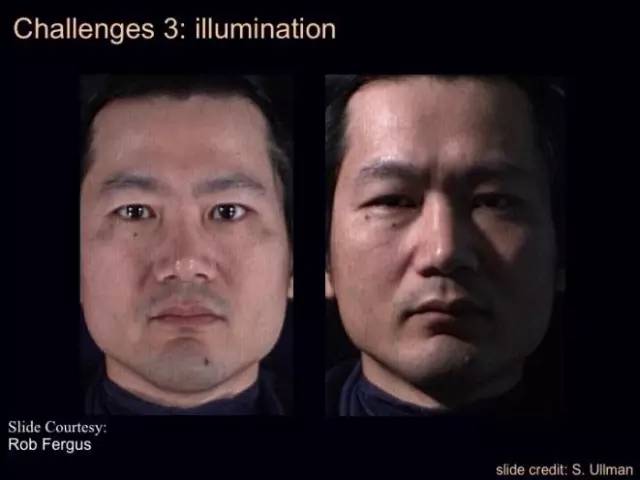
第四个难点是背景复杂。在复杂背景下,找到某一个人带着拐杖,找到一个戴帽子的人难度很大。

第五个难点是遮挡。遮挡是计算机视觉特别关心的一个难点。比如说,这个图片里熙熙攘攘的人中,我们知道这大概是一个女孩:她有棕色的头发,穿着一个短袖衫。我们人的本领很强,这种情况下还能识别出男女。但是计算机现在还做不到这一点。
第六个难点是变形。非钢体在运动的时候会产生变形。同样一匹马在不同的情况下的图像表现会非常不一样。
四、图像识别的发展历史
图像识别刚开始的时候是从单一的物体识别做起。上边这张图像展示的是传统的几何方法的结果。我们的客观世界那么复杂、那么多样,我们该怎么做识别呢?那就先从特别简单的问题做起。这也是我们做科学研究的一般的方法:从简单的问题着手。比如从做积木的识别入手。因为积木有很规范的几种形状。上图是识别出的简单的剃须刀。这些人造的非常规范的几何体的组合,只要识别出长方形、矩形、正方形、三角形等,就会把剃须刀,工具检测和识别得非常好。另外一种方法,是根据外观识别。我不考虑要识别的物体的几何结构,仅仅看它外观长什么样。这里列出的是做人脸检测的例子。


另外一个课题就是手写数字识别。手写数字看起来是很简单的事,但是对手写数字识别的研究引发出相当多的研究方法,给我们带来很多的成果,是一个很有意思的课题。此外的课题还有汽车的检测。我这里只是列了这几个。其实同时期还有指纹识别、文字识别OCR等、等。当时有的研究工作已经发展到了产品化的程度,包括OCR和指纹识别。
在2000年之前的图像识别曾经采用过几何的方法、结构的方法、规则的方法,当然也用了一些比较简单的模式识别的方法。
在80年代后期、90年代期间,机器学习领域发生了什么?这个时期的机器学习有了一个飞速的发展,出现了一些了不起的研究成果,包括:支持向量机方法,AdaBoosting方法,计算学习理论等。成果出现。这些都使得机器学习和识别大大的往前走。在2002年后的一段时间里,一个华人女科学家,叫李飞飞,开始用一个新的思路做图像识别。他们希望设计一个统一的框架做图像识别,而不是就事论事地针对一种图像识别任务设计一套专门的方法。他们希望这个统一的框架能识别成千上万种物体。另外,希望机器学习领域的出色成果可以用在图像识别上。她们还借鉴文本分析里的方法-“词袋”(bag of words)的方法用于图像识别。

什么是“词袋”方法?举一个例子。比如要识别一张人脸,我们不考虑人脸结构那么复杂,我们只要看看里面有没有鼻子、眼睛、嘴巴、下巴。有了这些部件,只要这些部件在一起,就说这是一张人脸。你可能会觉得这很简单。
这个方法来源自对文本的研究。在自然语言处理里面,有一个任务是对文本分类。文本分类中就采用了“词袋”方法。
比如说有这样一篇文章,我们想知道这篇文章是属于哪个类别。它是在讨论军事,还是在讨论科学。那么我们怎么做呢?一种办法是按我们通常会想到的方法,就是把每一句话都读懂,做解析,知道句子的语法结构,然后去理解句子的内容。但是,对句子做做语法分析很难,理解句子很难。我们往往做不好,所以就不采用这种方法。实际上,我们可以用一个简单的方法:我们只要看这篇文章出现过哪些词出现的频率高。这篇文章中的高频词是:视觉、感知、脑、神经,细胞,你会说这篇文章属于神经科学类。还有一篇文章,其中的高频词是:中国、贸易、出口、进口、银行、货币等,你会知道这篇文章属于经济类。这个方法不用分析和解析句子和段落的语法结构,而只要把这些高频词放到一块,叫“bag of words”。
怎样把这种方法用于图像识别呢?在识别图像的时候,我们也可以把图像中的“高频词”放在一起来识别图像。这里的“词”是什么?直观地说就是小的图像块。比如我们要识别一张人脸,这样的图像上就会有像皮肤一样,或者像眼睛一样的图像块。而相对来说,如果识别自行车,就会出现和车有关的图像块,如:车座、车梁。这些图像块就是“词”。这样就可以采用“词袋”方法。实际上,图像中的词不是我们说的这么直观,而是下方这样的图像小块。它是很底层的图像块,非常小,3*3,5*5或者7*7大小的图像块。这样小的图像块不表达很抽象的语义。
这种方法提出后,有很多有意思的相关的论文发表。但是这种方法还有缺陷。我们看这样的几个数字,在图像识别领域有一个物体识别比赛,这个比赛就是给你一些图像,让你去设计和训练你的算法。比赛的时候就是提供一些新的图像,要求算法告诉哪张图片是什么类别。如果预测前5个类别中有标准答案,就算预测正确。否则计算错误。这个比赛在2010年的第一名的成绩是72%,到2011年第一名的成绩是74%。我们知道,全世界那么多优秀的团队,有那么好的资源去做这个事,每年的进步大概就是1%-2%的样子。

在2000年之后这些年,机器学习在做什么事?机器学习仍然是做基础研究,出现了很多优秀成果。其中,2006年Hinton在Science上发表了一篇文章介绍他们的深度学习方法。有人建议Hinton用他们的方法试一试这个物体识别问题。结果在2012年的比赛中,他们获得了第一名,成绩是85%的识别率。后来大家发现这个方法原来那么好,所以大家一拥而上,纷纷用这种方法解决各自关心的问题。为什么人工智能现在这么热?主要就是因为这个原因。
张长水教授的实验室也用这个方法做了交通标识的识别,这是基金委的一个项目。花了很大的力气,成果很好,基本上可以到实用的程度。
五、 面临的困难和今后要研究的问题
看起来图像识别已经很好了,很多人很乐观,很多人热血沸腾。其实图像识别还没有做得那么好。有什么样的困难?我们举几个例子。
比如说我们在做图像识别的时候,通常我们要标注数据,就是要标注这是鸟、这是猫。然后用这些图像去做训练。标注数据其实是很头疼的事,很花时间很花钱。李飞飞的项目组收集的第一个数据集有101类物体。这个图像库做得很好,后来一些算法可以在这个数据库上达到99%多的识别率。人们说,这些图像质量太好了,种类也太少。后来她们又做了这个数据库,这个数据库有256种物体,图像也没有对齐得那么好。尽管这样,这个数据库开始太小。


在2009年李飞飞她们发布了新的数据库ImageNet,大概有几千万张图像数据。
标数据是件头疼的事。例如这个数据库就要对每个物体用一个方框框起来,并给出一个类别标号。这是一些典型的图像,给每个物体都要框起来,都要标好这是什么物体。

还有一个图像数据库叫LabelMe。上图是其中一张图像,标得非常细,房屋的外形、轮廓、窗户、汽车、所有草地、马路都标得很清楚。大概有十万多张图片,标得非常好的图像大概一万张。张教授有一次对MIT的一个学生说,你们这个数据库做得真了不起,花了那么大功夫。他说这是另一个学生做的。其实不是那个学生标的图像,大部分图像都是他妈妈标的,他妈妈退休在家,每天给他标数据,做妈妈的多么了不起。
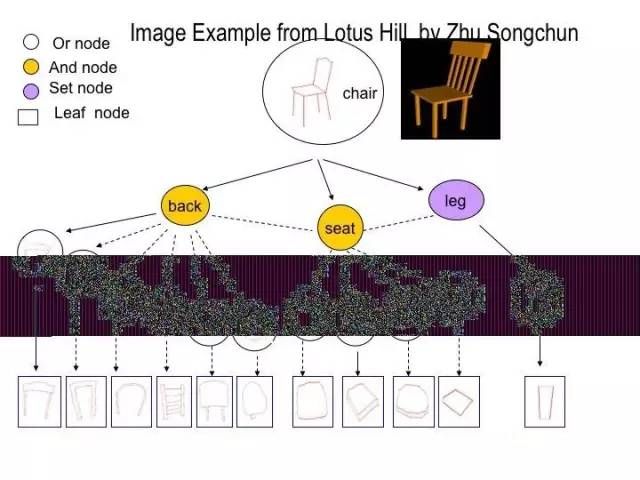
还有一个华人科学家,也很了不起,叫朱松纯。他说我们应该把图像标得更细。例如这张图片,其中的椅子可以标得非常细,座椅、椅背、腿的轮廓都标得很准确。他们还标了各种各样的椅子。他们雇了几十个美工,一天到晚标数据,干了几年,但是数据库才几十万张图片。所以标数据是一个非常花钱的事。因此做机器学习的人就在考虑,能不能不用那么费心去标数据而把图像识别做得更好一点。比如这张图片,只要你就是告诉我,你这张图片有摩托车,你不用说车在哪儿我也能把车检测和识别出来。
现在还有很多问题没解决。比如说我们现在的技术只是对图像做了一些解析,可以识别出这张图中这个部分鸟、这是树,但是没有对这个图片做更深入的理解。例如:这个算法并不知道这些物体之间的关系是什么。而对于我们理解一张图片来说,理解物体之间的关系非常重要。
在这个方面给大家介绍一下我们做的一个工作,叫image caption。这件事好几个单位都在做,微软、百度、Google都在做。给大家看的这些结果是实验室在做的工作。Image caption这是一个什么样的工作呢?就是你给我一张图片,你不需要告诉我这儿有一只狗,它叼的是一个什么样的东西。你只需要告诉我一只狗在叼着一个飞碟就够了。我们现在就利用这八万多张图片和对应的自然语言的句子来设计一个模型,并且训练这个模型,使得当你给我一张新的图片的时候,这个算法能生成一个自然语言的句子来描述它。比如这是针对对这张图片生成的句子:火车站旁边的轨道上停了一辆火车。再比如这个图像:一群斑马彼此很紧密地站在一起。还有这张图片:一只狗嘴里叼着飞碟。不仅如此,在做这个时候,还得到了另外一些有意思的结果。这个算法里有一个视觉的注意模型。这个模型可以自动找到关心的图像块。在对这张图像生成的句子A brown cow is standing in the grass时,我们看到brown,cow, grass都对应着正确的图像块。大家注意,我们在训练数据里面并没有告诉算法哪一块是牛,哪一块是草地。这说明,这个算法学习到了这些概念。既然是这样,除此以外,其他的概念是不是也能找对?我们就把其他的一些词所对应的图像块找出来,看一看。比如说这一排是消火栓这个词对应的图像块。这是黑猫这个概念。结果都找对了。比较有意思的是,除了名词以外,程序还找到了动词对应的概念。比如说fill with(把…填满),你会发现图片全是容器里面盛东西。
这个结果很有意思,非常像小孩在成长过程中学习。我们会教一个一岁多的孩子,告诉他“这是一张桌子”,“这是一个激光笔”。我们不会,也无法说:“一张”是量词,“桌子”是关键词。但是孩子慢慢就能学会这些概念。我们的算法也是这样。
上面列举了我们取得的成果。但是,面前还有很多很多的问题没有解决。比如,我们现在看深度网络很有效,但是它为什么有效?我们还不太明白。除此之外还有其他的模型吗?比如说有一些工程上的问题,那么多数据你能算吗?机器跑得动吗?做机器学习的人非常关心这些问题。

另外,比如说这里有一束花。现在算法可以识别出这是一束花。但是它还不能说出哪里是叶子,哪里是花蕊,哪里是花瓣。我们看起来已经取得了那么多的成果,从某种意义上来说我们也可以把它们做成产品,让他为我们服务,但同时我们看到还有更多的问题没有解决得很好,这就需要我们继续努力。
本文基本上是在讲图像。但是我们看到背后用的很多方法都是机器学习的方法。所以是机器学习人的努力,计算机视觉科学家的努力,大家共同的努力,取得了现在的成果。我们可以用这些成果转化成产品,使我们的生活可以更智能化一点。
Facebook公布了今年入选计算机视觉顶级会议ICCV的15篇研究成果
来源:research.fb.com 编译:弗格森
涉及语义和图像分割、物体识别、图像分类、视觉与语言的结合、图像生成、3D视觉等多个方面。
来自世界各地的计算机视觉专家将于本周聚集在于威尼斯举行的国际计算机视觉会议(ICCV),介绍计算机视觉和相关领域的最新进展。来自Facebook的研究将在15篇经过同行评审的出版物和海报中发表。 Facebook研究人员还将出席众多的研讨会和讲座。
以下是 Facebook 在本年度的 ICCV 上呈现的研究完整列表,根据研究主题进行了整理:
论文:Mask R-CNN
作者:Kaiming He, Georgia Gkioxari, Piotr Dollár, Ross Girshick
论文地址:https://research.fb.com/publications/mask-r-cnn/
这篇论文开发了一种新的系统,对于照片中的每个像素,它可以预测像素会对哪些物体作出反应,也可以预测像素会对哪一个物体作出反应。所以系统不仅会描绘羊,然后告诉你它们是羊(“语义”分割),但它也会告诉你哪些部分的图像对应于哪只羊(“实例”分割)。Mask R-CNN是成功完成此项工作的系统之一。 Facebook的 CTO Mike Schroepfer在今年早些时候在F8的主题演讲中展示了Mask R-CNN的Demo。
论文:Predicting Deeper into the Future of Semantic Segmentation
作者:Pauline Luc, Natalia Neverova, Camille Couprie, Jakob Verbeek, Yann LeCun
论文地址:https://research.fb.com/publications/predicting-deeper-into-the-future-of-semantic-segmentation/
本文开发了一种深度学习模型,从一个视频中的特定帧(静态)尝试预测下一帧将是什么样子。所以在某种意义上,它是试图猜测视频接下来会展示什么内容的。本文表明,研究最后所得到的模型可用于提高计算机视觉系统在语义分割等任务中的质量。
论文:Segmentation-Aware Convolutional Networks Using Local Attention Masks
作者:Adam W. Harley, Konstantinos G. Derpanis, Iasonas Kokkinos
论文地址:https://research.fb.com/publications/segmentation-aware-convolutional-networks-using-local-attention-masks/
在深度神经网络中,网络的层次越深,一个卷积网络中的众多神经元对图像进行“审查”的部分就越大。这可能会导致局部性(localized)变差以及模糊的反应,因为,神经元需要对图像非常大的部分进行“审查”。在这项研究中,我们通过每一个神经元只出现在自己感兴趣的区域,进而锐化这种反应。
论文:Dense and Low-Rank Gaussian CRFs Using Deep Embeddings
作者:Siddhartha Chandra, Nicolas Usunier, Iasonas Kokkinos
论文地址:https://research.fb.com/publications/dense-and-low-rank-gaussian-crfs-using-deep-embeddings/
虽然卷积网络可以非常准确地将图像中的像素分类为不同的类别(汽车,飞机,...),但相邻的决策通常不一致:一半物体可能被标记为“床”,另一半则被标记为“沙发”。本文提出了一种耦合所有像素分类的技术,以非常有效的方式产生一致的预测。
论文:Focal Loss for Dense Object Detection
作者:Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, Piotr Dollár
论文地址:https://research.fb.com/publications/focal-loss-for-dense-object-detection/
本文提出了一种新的物体检测系统。该系统在技术上与现有的目标检测技术不同。当下,大多数系统由多个“阶段”组成,每个阶段都由不同的模型实现,本文开发了一个在单个阶段解决整个对象检测问题的模型。这种简单性很有吸引力,因为它使得系统更容易实现和使用。
论文:Low-shot Visual Recognition by Shrinking and Hallucinating Features
作者:Bharath Hariharan, Ross Girshick
论文地址:https://research.fb.com/publications/low-shot-visual-recognition-by-shrinking-and-hallucinating-features/
物体检测系统通常是基于成千上万的图像进行训练,这些图像中包含了它们需要识别出来的物体。本文着重于解决在仅看到该类别的很少示例之后识别新的对象类型的问题。它通过“设想”我们想要识别的物体的额外例子来实现。
论文:Transitive Invariance for Self-supervised Visual Representation Learning
作者:Xiaolong Wang, Kaiming He, Abhinav Gupta
论文地址:https://research.fb.com/publications/transitive-invariance-for-self-supervised-visual-representation-learning/
本文提出通过观察对象在视频中的外观变化来学习更好的对象检测模型。例如,驾驶的车辆的视频会显示来自不同帧的不同角度的汽车。因为你知道每个框架其实都描述了同一辆车,所以你可以使用这些信息来学习更好地理解同一个物体的不同视角的模型。所得到的模型可用于改进对象检测器。
论文:Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization
作者:Ramprasaath R. Selvaraju, Michael Cogswell, Abhishek Das, Ramakrishna Vedantam, Devi Parikh, Dhruv Batra
论文地址:https://research.fb.com/publications/grad-cam-visual-explanations-from-deep-networks-via-gradient-based-localization/
大多数现代图像分类系统都基于称为卷积网络的模型。这些网络工作得很好,但它们也是一个“黑匣子”的问题。本文开发了一种新技术,可以通过可视化照片中的哪些区域让系统以特定的方式对其进行分类,从而“打开盒子”。
论文:Learning Visual N-Grams from Web Data
作者:Ang Li, Allan Jabri, Armand Joulin, Laurens van der Maaten
论文地址:https://research.fb.com/publications/learning-visual-n-grams-from-web-data/
大多数图像识别系统都是通过手动注释的大型图像集合进行训练。此注释过程繁琐而且不能扩展。本文开发了一种图像识别系统,该系统接受了5000万张照片和用户评论的训练,无需手动注释。该系统可以识别跨越多个单词的对象,地标和场景,例如“金门大桥”或“自由女神像”。
论文:Inferring and Executing Programs for Visual Reasoning
作者:Justin Johnson, Bharath Hariharan, Laurens van der Maaten, Judy Hoffman, Li Fei-Fei, C. Lawrence Zitnick, Ross Girshick
论文地址:https://research.fb.com/publications/inferring-and-executing-programs-for-visual-reasoning/
本论文研究的是视觉推理问题:根据一个图像,它的目的是回答诸如“蓝盒前面的东西的形状是什么”的问题。它通过使用将问题转换为简单的计算机程序的“模块网络”来实现,并且使用神经网络来实现该程序中的每个指令。本文还发布了一个新的视觉推理数据集,称为CLEVR-Human。
论文:Learning Cooperative Visual Dialog Agents with Deep Reinforcement Learning
作者:Abhishek Das, Satwik Kottur, Jos. M. F. Moura, Stefan Lee, Dhruv Batra
论文地址:https://research.fb.com/publications/learning-cooperative-visual-dialog-agents-with-deep-reinforcement-learning/
本文开发了一个chatbot来回答关于图像的问题。例如,你可以问这个chatbot:“那个女人的伞的颜色是什么?”。如果图像中有两个女人,chabot会问:“哪个女人?”你回答:“黑头发的人”,chatbot会告诉你:“伞是蓝色的”。我们还没有真正解决这个问题,但这是试图解决这个问题的首批论文之一。
论文:Learning to Reason: End-to-End Module Networks for Visual Question Answering
作者:Ronghang Hu, Jacob Andreas, Marcus Rohrbach, Trevor Darrell, Kate Saenko
论文地址:https://research.fb.com/publications/learning-to-reason-end-to-end-module-networks-for-visual-question-answering/
本文介绍了一种用于回答诸如“紫色圆柱体左边的球的颜色是什么”的新技术。该技术通过将问题转换为小型计算机程序来实现。然后,程序中的每个指令由神经网络执行。程序“生成器”和程序“执行器”都是从图像和问题的配对中学习的。
论文:Speaking the Same Language: Matching Machine to Human Captions by Adversarial Training
作者:Rakshith Shetty, Marcus Rohrbach, Lisa Anne Hendricks, Mario Fritz, Bernt Schiele
论文地址:https://research.fb.com/publications/speaking-the-same-language-matching-machine-to-human-captions-by-adversarial-training/
本文涉及自动生成标题的问题,即图像的自然语言描述。主要的技术创新是,它试图使系统产生的字幕看起来更像是人类制作的字幕。
论文:Unsupervised Creation of Parameterized Avatars
作者:Lior Wolf, Yaniv Taigman, Adam Polyak
论文地址:https://research.fb.com/publications/generative-collaborative-networks-for-cross-domain-configuration-extraction/
本文开发了一个新的系统,根据你的脸部的常规照片,生成一个像你一样的头像。主要技术创新是系统以“无监督”的方式进行培训。这意味着它没有配对的脸部图像和相应的头像进行训练:它看到的是一堆脸和一堆头像。系统学习自动找出哪些头像对应于哪个脸。
论文:Deltille Grids for Geometric Camera Calibration
作者:Hyowon Ha, Michal Perdoch, Hatem Alismail, In So Kweon, Yaser Sheikh
论文地址:https://research.fb.com/publications/deltille-grids-for-geometric-camera-calibration/
物体的三维模型被用于虚拟现实等应用中。这些模型是通过从“天顶”的角度拍摄物体制作,而不是用数百台相机同时进行拍摄。这些相机需要进行校准,使得将所有图像组合成对象的3D模型的系统准确地知道相机所在的位置。几十年来,这种校准是通过拍摄标准checkerboard来完成的。本论文表明,通过使用带有三角形场的checkerboard,可以更精确地校准摄像机。
Instance-Level Visual Recognition Tutorial
Talks by Georgia Gkioxari, Kaiming He, and Ross Girshick
Closing the Loop between Vision and Language Workshop
Larry Zitnick, Opening keynote
Dhruv Batra, Invited talk
Generative Adversarial Networks Tutorial
Soumith Chintala presents his GANs-in-the-wild paper
Role of Simulation in Computer Vision workshop
Devi Parikh, Invited talk
Workshop on Web-Scale Vision and Social Media
Ang Li, Invited talk on his Facebook internship project
Workshop on Computer Vision for Virtual Reality
Organized by Frank Dellaert and Richard Newcombe
COCO + Places Workshop
Team FAIR presents its competition submission
PoseTrack Challenge Workshop
Yaser Sheikh, Invited talk
Georgia Gkioxari, Rohit Girdhar, Du Tran, Lorenzo Torresani and Deva Ramanan present their challenge submission
图像分类、目标检测、图像分割一文「计算机视觉」全分析

原文来源:Deep Dimension
作者:Shravan Murali
「机器人圈」编译:嗯~阿童木呀、多啦A亮
相信大家都有所了解,迄今为止,在至少约十年的时间里,用于解决计算机视觉领域问题的技术已经有了很大的改进。那对于计算机视觉领域存在的问题有哪些呢?一些显著的问题是:图像分类、目标检测、图像分割、图像生成、图像说明等。在本文中,将对这些问题进行简要介绍,并且尝试从人类是如何解读图像的角度去比较和对比一下这些技术。同时,在本文中还将涉及一些关于AGI(通用人工智能)的相关知识,并就此提出一些个人观点和想法。
目的
在深入了解之前,我们可以先从一些公司是如何创造性地使用计算机视觉的获得动力的。从我的角度来说,最酷的初创企业之一是clarifai.com。Clarifai是由Matthew Zeiler(马修•泽勒)创立的,他和他的团队在2013年期间连续赢得了imageNet的挑战赛的胜利。他的模型在上一年的最佳准确度的基础上将图像分类的错误率降低了近4%。Clarifai基本上是一家人工智能公司,为视觉识别任务(如图像和视频标签)提供API。Clarifai在这里有演示。这家公司是非常有前途的,它的图像和视频识别技术是非常准确的。现在我们来看看Facebook的自动图像标记,下次你登录Facebook帐户时,右键点击任何图片,然后点击“检查元素”(这是针对Chrome浏览器而言的;在其他浏览器上也会有相同的东西)。查看img标签中的alt属性(应该看起来像这样<img src = “…” alt = “…” />)。你会发现alt属性有这样的文本前缀“Image may contain : …..”。这项技术也是非常准确的,可以识别人、文、山、天空、树木、植物、户外和自然等等。而另一个很酷的技术就是Google的了。点击photos.google.com进去之后,然后在搜索栏中输入内容。假设你输入了“山脉”,那么你就可以在包含山脉的搜索结果中准确地找到所有的照片。Google图片搜索也是如此。关于图像搜索的最好部分,反之亦然,即你可以上传图像并获得图像的最佳描述,同时还可获取与上传图像相似的图像,这个技术也是很重要的。

我希望你现在已经拥有了足够的动力,当然肯定还有一大堆其他技术被我忽略了。实际上是因为有很多非常相似的技术,一篇文章是很难涵盖一切的。
那么,我们现在就来了解一些计算机视觉的相关问题!
计算机视觉
图像分类
图像分类主要是基于图像的内容对图像进行标记,通常会有一组固定的标签,而你的模型必须预测出最适合图像的标签。这个问题对于机器来说相当困难的,因为它看到的只是图像中的一组数字流。

上图片来自于Google Images
而且,世界各地经常会举办多种多样的图像分类比赛。在Kaggle中就可以找到很多这样的竞赛。最著名的比赛之一就是ImageNet挑战赛。ImageNet实际上是一个很神奇的图像库(截止到编辑本文时,其中就约有1400万张图像),拥有超过20000个图像标签。这是由斯坦福大学计算机视觉实验室维护的。ImageNet挑战或大规模视觉识别挑战(LSVRC)都是一个年度竞赛,其中具有诸如目标分类,目标检测和目标定位等各种子挑战。LSVRC,特别是目标分类的挑战,自从2012年,Alex Krizhevsky实施了著名的AlexNet,将图像的错误率降低到15.7%(在当时从未实现),便开始获得了很多关注。而最新的结果显示,微软ResNet的错误率为3.57%,Google的Inception-v3已经达到3.46%,而Inception-v4则又向前进了一步。
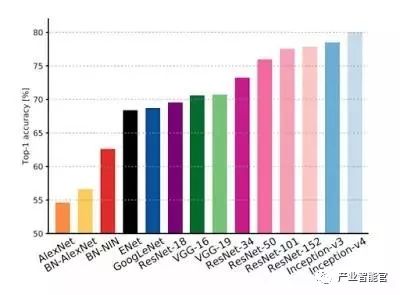
来源于Alfredo Canziani,Adam Paszke和Eugenio Culurciello于2017年撰写的文章《实际应用中深度神经网络模型的分析》(https://arxiv.org/pdf/1605.07678.pdf)
目标检测
图像中的目标检测涉及识别各种子图像并且围绕每个识别的子图像周围绘制一个边界框。这里有一个例子:
上图片来自于Google Images
与分类相比,这个问题要稍微复杂一点,你必须对图像进行更多的操作和处理。现在最著名检测方法叫做Faster-RCNN。RCNN是局部卷积神经网络,它使用一种称为候选区域生成网络(Region Proposal Network,RPN)的技术,实际上是将图像中需要处理和分类的区域局部化。后来RCNN经过调整效率得以调高,现在称之为faster – RCNN,一种用作候选区域生成方法的一部分用以生成局部的卷积神经网络。目前最新的image-net挑战(LSVRC 2017)有一个目标检测的挑战赛的冠军,被一个名为“BDAT”的团队所囊括,该团队包括来自南京信息工程大学和伦敦帝国理工学院的人员。
图像/实例分割
图像分割或实例分割包括对具有现有目标和精确边界的图像进行分割。

图片来自于是Google Images
它使用了一种叫做Mask R-CNN的技术,实际上就是我们前面看到的R-CNN技术上的几个卷积层。微软、Facebook和Mighty AI联合发布了这个称为COCO的数据集。它与ImageNet很相似,但它主要用于分割和检测。
图像说明
这是我前面所说的具有一系列自然语言处理的最酷的计算机视觉问题之一。这其中包括生成一个最适合你的图像的标题。

图像来自于Google Images
图像说明是基本图像检测+说明。图像检测通过我们前面看到的相同的Faster R-CNN方法完成。字幕使用RNN(循环神经网络)完成。为了更加精确,使用作为RNN的高级版本的LSTM(长短期记忆网络)。这些RNN非常类似于我们的常规深度神经网络,除了这些,RNN取决于网络的先前状态。你可以想象它更像一个神经网络,神经元随着时间的推移与空间建立。在结构上,RNN看起来像这样:
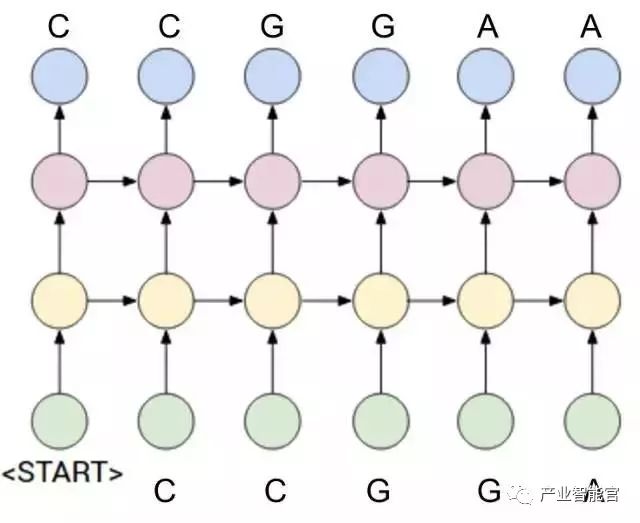
通常,这些RNN用于你的数据与时间相关的问题。例如,如果你想预测一个句子中的下一个单词,那么新单词取决于在之前的时间步骤中出现的所有单词。
现在让我们稍微切换一下主题,看看人类的视觉理解。
为什么人类的视觉理解更好?
在深入了解人类大脑的细节之前,我想讨论一下深度神经网络的缺点。
虽然深度神经网络看起来奇妙而神奇,但不幸的是它们很容易被愚弄。看看这个:

以上图片来自Andrej Karpathy的博客
如图所示,每张图像强加一个噪音图像,视觉上不会改变原始图像,但被错误分类为鸵鸟!
这种攻击被称为深度神经网络的对抗攻击。他们最初由Szegedy等人提出,随后在2013年,由Goodfellow等人进一步研究。基本上发现,通过优化图像中的像素强度,我们可以找到最小的噪声信号,从而优先考虑一个不同类别的深度神经网络,而不是当前的、。这使得生成式模型的快速增长。目前有3种众所周知的生成模型,即Pixel RNN / Pixel CNN,变分自动编码器(Variational Auto-encoders)和生成对抗网络(Generative Adversarial Networks)。
人类视觉理解
虽然我们在开发与计算机视觉相关的酷炫技术方面已经取得了长足的进步,但从长远来看,人类在图像理解方面比任何技术都要好得多。这是因为,机器是非常狭隘的,在某种意义上说,他们只是通过学习固定的图像类别来学习东西。虽然他们可能从大量的图像中学习(代表性的是ImageNet挑战赛中大约有一百万张图像),但它离人类所能做的还很远。我主要把这归因于人脑,确切地说是人脑中的新皮层(neocortex)。新皮层是大脑的一部分,负责识别模式、认知和其他高阶功能,如感知。我们的大脑是如此复杂的设计,它可以帮助我们记住东西,而不是直接转储所需的数据到内存中,就像硬盘一样。大脑相当于存储我们所目击事物的模式,并在必要的时候检索它们。
此外,人类在生活中的每一个时刻都在不断地收集数据(例如,通过视觉采集图像),这与机器不同。我们来举个例子,我们大多数人几乎每天都能看到狗,同样我们会看到狗的不同姿势和不同角度。这意味着,鉴于有狗的图像,我们很可能在图片中识别出一只狗。机器不是这样。机器可能只是针对一定数量的狗的图像进行了训练,因此可能容易被愚弄。如果你提供同一只狗的图像略有不同的姿势,那么可能就会被错误分类。
AI真的可以与“人脑”抗衡吗?
嗯,在过去这是一个非常有争议的话题。我们来分析一下!
在Jeff Dean的演讲中,他提到了自2011年以来大部分已发表的组成深度神经网络的参数数量。如果你注意到,对于人类来说,他提到了“100万亿”。虽然他似乎认为有些像一个笑话,但考虑到人脑所能处理的复杂事物的数量,这似乎是千真万确的。假设我们的大脑是复杂的,设计一个具有这么多参数的系统是否更为实用?
那么在人工智能领域有一些重大的突破,如AlphaGo在围棋游戏中打败世界冠军,OpenAI的Dota2机器人在游戏中多次打败职业玩家。然而,在某种意义上这些东西似乎非常适用,因为Dota2机器人是符合Dota2特性的,而不适用于其他任何东西。相反,人类的大脑是非常通用的。你会用你的大脑进行几乎所有的日常活动。由此我想推断的是,为了与哺乳动物的大脑竞争,我们需要通用人工智能!
一些随想
我会说使用强化学习(RL)(特别是深度加强学习:DRL)使我们更加靠近解决通用智能。 在RL中,智能体自己发现了采取行动的最佳方式。这似乎类似于也是人类如何学习。人类通过了解他们的行为是否正确来学习做事情。以同样的方式,在强化学习中,智能体执行随机动作,每个动作都具有相关的奖励。智能体从获得的动作中学习,即以这样的方式选择一个动作,使其获得的未来全部奖励最大化。
目前这是一个活跃的研究领域,涉及DeepMind和OpenAI等巨头。事实上,DeepMind的主要目标是“解决通用人工智能”!
点击链接查看原文:https://medium.com/deep-dimension/an-analysis-on-computer-vision-problems-6c68d56030c3。

人工智能赛博物理操作系统
AI-CPS OS
“人工智能赛博物理操作系统”(新一代技术+商业操作系统“AI-CPS OS”:云计算+大数据+物联网+区块链+人工智能)分支用来的今天,企业领导者必须了解如何将“技术”全面渗入整个公司、产品等“商业”场景中,利用AI-CPS OS形成数字化+智能化力量,实现行业的重新布局、企业的重新构建和自我的焕然新生。
AI-CPS OS的真正价值并不来自构成技术或功能,而是要以一种传递独特竞争优势的方式将自动化+信息化、智造+产品+服务和数据+分析一体化,这种整合方式能够释放新的业务和运营模式。如果不能实现跨功能的更大规模融合,没有颠覆现状的意愿,这些将不可能实现。
领导者无法依靠某种单一战略方法来应对多维度的数字化变革。面对新一代技术+商业操作系统AI-CPS OS颠覆性的数字化+智能化力量,领导者必须在行业、企业与个人这三个层面都保持领先地位:
重新行业布局:你的世界观要怎样改变才算足够?你必须对行业典范进行怎样的反思?
重新构建企业:你的企业需要做出什么样的变化?你准备如何重新定义你的公司?
重新打造自己:你需要成为怎样的人?要重塑自己并在数字化+智能化时代保有领先地位,你必须如何去做?
AI-CPS OS是数字化智能化创新平台,设计思路是将大数据、物联网、区块链和人工智能等无缝整合在云端,可以帮助企业将创新成果融入自身业务体系,实现各个前沿技术在云端的优势协同。AI-CPS OS形成的数字化+智能化力量与行业、企业及个人三个层面的交叉,形成了领导力模式,使数字化融入到领导者所在企业与领导方式的核心位置:
精细:这种力量能够使人在更加真实、细致的层面观察与感知现实世界和数字化世界正在发生的一切,进而理解和更加精细地进行产品个性化控制、微观业务场景事件和结果控制。
智能:模型随着时间(数据)的变化而变化,整个系统就具备了智能(自学习)的能力。
高效:企业需要建立实时或者准实时的数据采集传输、模型预测和响应决策能力,这样智能就从批量性、阶段性的行为变成一个可以实时触达的行为。
不确定性:数字化变更颠覆和改变了领导者曾经仰仗的思维方式、结构和实践经验,其结果就是形成了复合不确定性这种颠覆性力量。主要的不确定性蕴含于三个领域:技术、文化、制度。
边界模糊:数字世界与现实世界的不断融合成CPS不仅让人们所知行业的核心产品、经济学定理和可能性都产生了变化,还模糊了不同行业间的界限。这种效应正在向生态系统、企业、客户、产品快速蔓延。
AI-CPS OS形成的数字化+智能化力量通过三个方式激发经济增长:
创造虚拟劳动力,承担需要适应性和敏捷性的复杂任务,即“智能自动化”,以区别于传统的自动化解决方案;
对现有劳动力和实物资产进行有利的补充和提升,提高资本效率;
人工智能的普及,将推动多行业的相关创新,开辟崭新的经济增长空间。
给决策制定者和商业领袖的建议:
超越自动化,开启新创新模式:利用具有自主学习和自我控制能力的动态机器智能,为企业创造新商机;
迎接新一代信息技术,迎接人工智能:无缝整合人类智慧与机器智能,重新
评估未来的知识和技能类型;
制定道德规范:切实为人工智能生态系统制定道德准则,并在智能机器的开
发过程中确定更加明晰的标准和最佳实践;
重视再分配效应:对人工智能可能带来的冲击做好准备,制定战略帮助面临
较高失业风险的人群;
开发数字化+智能化企业所需新能力:员工团队需要积极掌握判断、沟通及想象力和创造力等人类所特有的重要能力。对于中国企业来说,创造兼具包容性和多样性的文化也非常重要。
子曰:“君子和而不同,小人同而不和。” 《论语·子路》云计算、大数据、物联网、区块链和 人工智能,像君子一般融合,一起体现科技就是生产力。
如果说上一次哥伦布地理大发现,拓展的是人类的物理空间。那么这一次地理大发现,拓展的就是人们的数字空间。在数学空间,建立新的商业文明,从而发现新的创富模式,为人类社会带来新的财富空间。云计算,大数据、物联网和区块链,是进入这个数字空间的船,而人工智能就是那船上的帆,哥伦布之帆!
新一代技术+商业的人工智能赛博物理操作系统AI-CPS OS作为新一轮产业变革的核心驱动力,将进一步释放历次科技革命和产业变革积蓄的巨大能量,并创造新的强大引擎。重构生产、分配、交换、消费等经济活动各环节,形成从宏观到微观各领域的智能化新需求,催生新技术、新产品、新产业、新业态、新模式。引发经济结构重大变革,深刻改变人类生产生活方式和思维模式,实现社会生产力的整体跃升。
产业智能官 AI-CPS
用“人工智能赛博物理操作系统”(新一代技术+商业操作系统“AI-CPS OS”:云计算+大数据+物联网+区块链+人工智能),在场景中构建状态感知-实时分析-自主决策-精准执行-学习提升的认知计算和机器智能;实现产业转型升级、DT驱动业务、价值创新创造的产业互联生态链。


长按上方二维码关注微信公众号: AI-CPS,更多信息回复:
新技术:“云计算”、“大数据”、“物联网”、“区块链”、“人工智能”;新产业:“智能制造”、“智能农业”、“智能金融”、“智能零售”、“智能城市”、“智能驾驶”;新模式:“财富空间”、“特色小镇”、“赛博物理”、“供应链金融”。
点击“阅读原文”,访问AI-CPS OS官网
本文系“产业智能官”(公众号ID:AI-CPS)收集整理,转载请注明出处!
版权声明:由产业智能官(公众号ID:AI-CPS)推荐的文章,除非确实无法确认,我们都会注明作者和来源。部分文章推送时未能与原作者取得联系。若涉及版权问题,烦请原作者联系我们,与您共同协商解决。联系、投稿邮箱:erp_vip@hotmail.com





