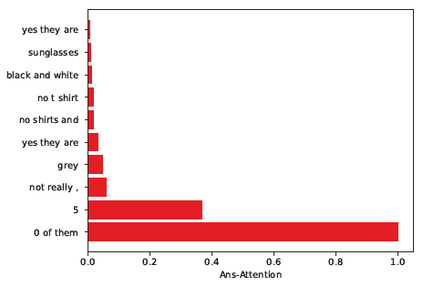
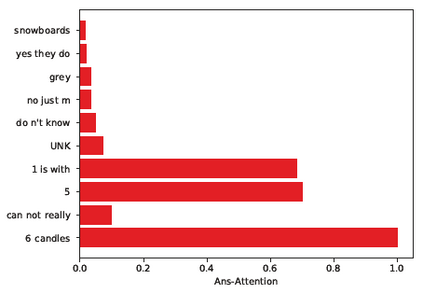
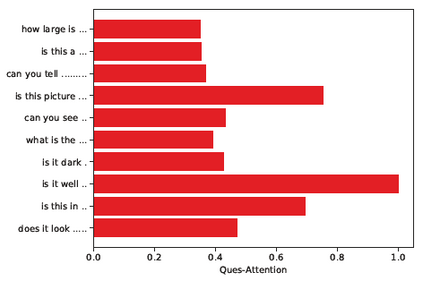
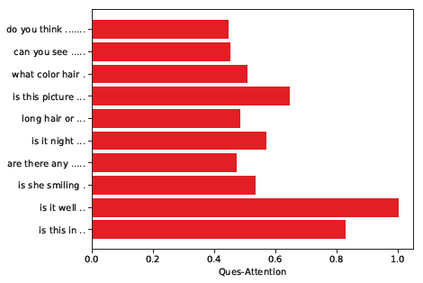
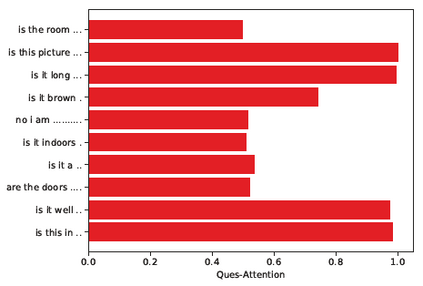
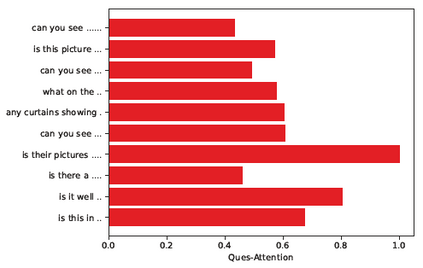
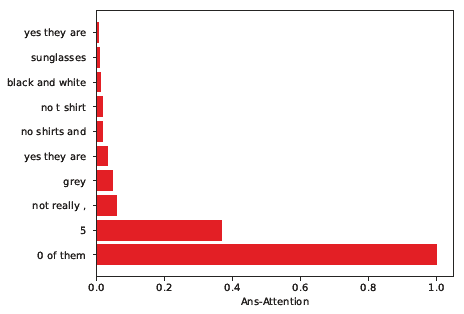
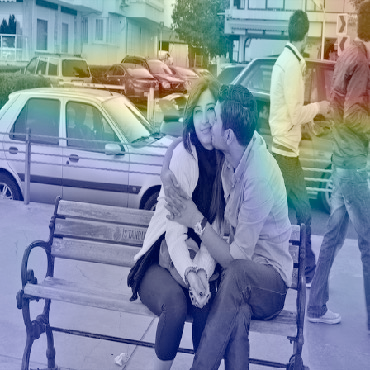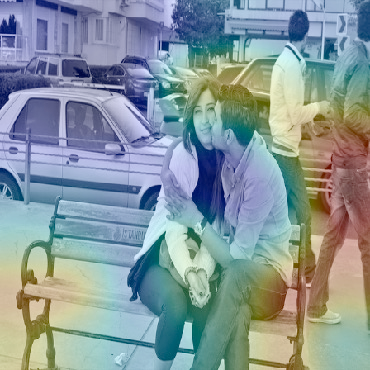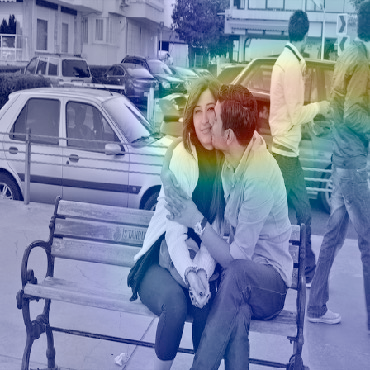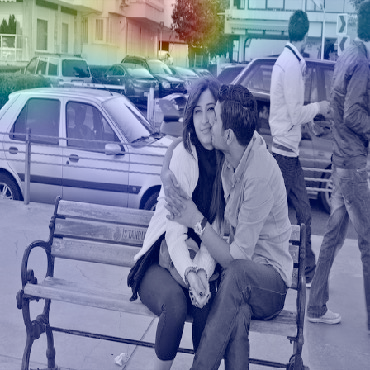Dialog is an effective way to exchange information, but subtle details and nuances are extremely important. While significant progress has paved a path to address visual dialog with algorithms, details and nuances remain a challenge. Attention mechanisms have demonstrated compelling results to extract details in visual question answering and also provide a convincing framework for visual dialog due to their interpretability and effectiveness. However, the many data utilities that accompany visual dialog challenge existing attention techniques. We address this issue and develop a general attention mechanism for visual dialog which operates on any number of data utilities. To this end, we design a factor graph based attention mechanism which combines any number of utility representations. We illustrate the applicability of the proposed approach on the challenging and recently introduced VisDial datasets, outperforming recent state-of-the-art methods by 1.1% for VisDial0.9 and by 2% for VisDial1.0 on MRR. Our ensemble model improved the MRR score on VisDial1.0 by more than 6%.
翻译:对话是交流信息的有效途径,但微妙的细节和细微差别极为重要。 虽然显著的进展为用算法进行视觉对话铺平了一条路径,但细节和细微差别仍然是一个挑战。 注意机制已经显示出令人信服的结果,在直观回答中提取细节,并且由于可解释性和有效性为视觉对话提供了一个令人信服的框架。 但是,视觉对话中的许多数据工具对现有的关注技术提出了挑战。 我们处理这一问题,并为视觉对话开发了一个一般关注机制,在任何数量的数据工具上运作。 为此,我们设计了一个以系数图为基础的关注机制,将任何数量的实用表示方式结合起来。 我们举例说明了拟议方法在挑战性和最近引入的维西亚数据集上的适用性,VisDial0.9比1.1%的最近最新最新最新水平方法,而VisDial1.0的MRR值比比6%以上。 我们的共振模型将VisDial1.0的MRR分数提高了6%以上。