【机器视觉】李飞飞最新演讲:视觉智慧是人类和计算机合作沟通的桥梁

AI 科技评论报道:中国计算机学会 CCF 举办的中国计算机大会CNCC 2017已于10月26日在福州市海峡国际会展中心开幕。参加会议的人数众多,主会场座无虚席。 AI 科技评论也派出记者团全程参与大会报道。
26日上午开幕式结束后,多位特邀嘉宾进行了现场演讲,主题涵盖计算机科学发展中的新技术和应用、自然语言利净额、AI如何服务于人、人工智能在信息平台的应用等等。斯坦福大学副教授、谷歌云首席科学家、机器学习界的标杆人物之一的李飞飞进行了题目为「A Quest for Visual Intelligence: Exploration Beyond Objects」的演讲。
李飞飞首先介绍了视觉对生物的重要性,以及计算机视觉在物体识别任务中的飞速发展。然后继续与大家讨论了计算机视觉的下一步目标:丰富场景理解,以及计算机视觉与语言结合和任务驱动的计算机视觉的进展和前景。场景理解和与语言结合的计算机视觉进一步搭起了人类和计算机之间沟通的桥梁,任务驱动的计算机视觉也会在机器人领域大放异彩。李飞飞介绍的自己团队的工作也丰富多样、令人振奋。

李飞飞首先介绍了构建视觉智能中的第一个里程碑,那就是物体识别。人类具有无与伦比的视觉识别能力,认知神经科学家们的许多研究都展示出了这一现象。李飞飞在现场与听众们做了一个小互动,在屏幕上闪过一系列持续时间只有0.1秒的照片,不加任何别的说明,而观众们还是能够识别到有一张中有一个人。
MIT教授Simon Thorpe在1996年的一个实验中,也通过记录脑波的方式表明,人类只需要观察一张复杂照片150ms的时间,就能辨别出其中是否包含动物,不管是哺乳动物、鸟类、鱼,还是虫子。
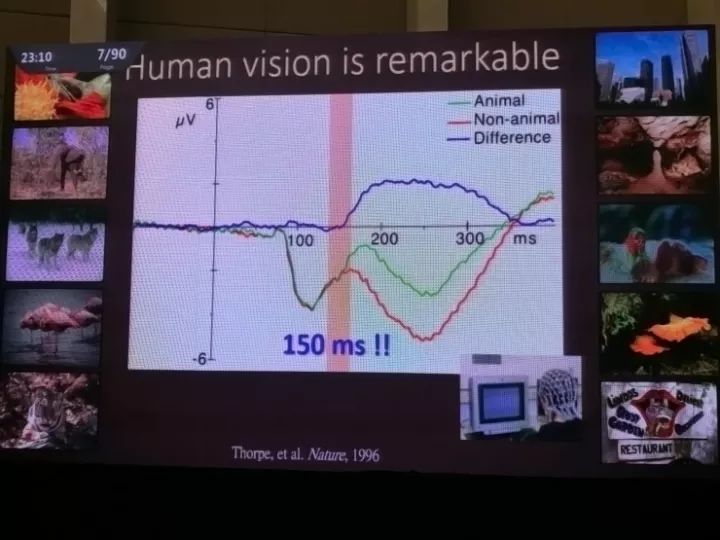
这种对复杂物体的快速视觉识别能力是人类视觉系统的基本特质,而这也是计算机视觉中的“圣杯”。在过去的20年中,物体识别都是计算机视觉社区研究的重要任务。ImageNet就是起到了贡献的数据集之一。
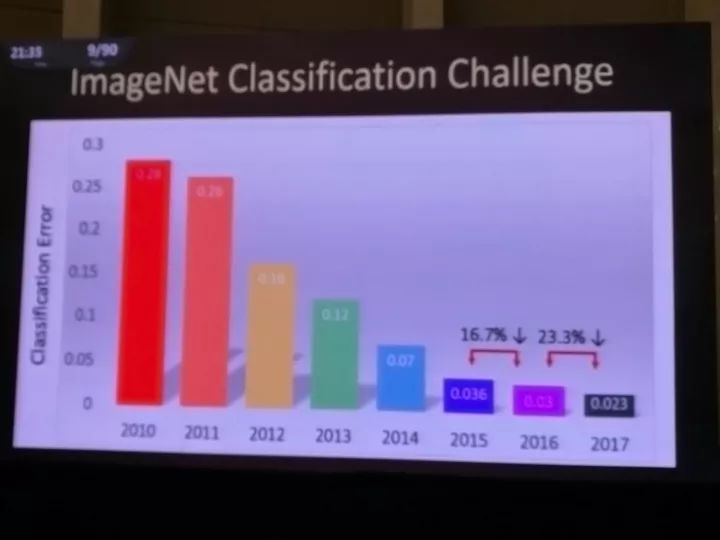
从2010年以来,从 2010 到 2017,ImageNet 挑战赛的物体识别错误率下降到了原来的十分之一。到 2015 年,错误率已经达到甚至低于人类水平。这基本表明计算机视觉已经基本攻克了简单的物体识别问题。
计算机视觉研究当然不会止步于 ImageNet 和物体识别,这仅仅是人类丰富视觉感受的基础。

下一个关键步骤就是视觉关系的识别。这项任务的定义是:“把一张照片输入算法模型中,希望算法可以识别出其中的重点物体,找到它们的所在位置,并且找到它们之间的两两关系”。
两张照片都是人和羊驼,但是发生的事情完全不同。这就是单纯的物体识别所无法描述的了。

在深度学习时代之前,这方面也有不少的研究,但多数都只能在人为控制的空间中分析空间关系、动作关系、类似关系等寥寥几种关系。随着计算力和数据量的爆发,在深度学习时代研究者们终于能够做出大的进展。这需要卷积神经网络的视觉表征和语言模型的结合。
在李飞飞团队ECCV2016的收录论文中,他们的模型已经可以预测空间关系、比较关系、语义关系、动作关系和位置关系,在“列出所有物体”之外,向着场景内的物体的丰富关系理解迈出了坚实的一步。

除了关系预测之外,还可以做无样本学习。举个例子,用人坐在椅子上的照片训练模型,加上用消防栓在地上的图片训练模型。然后再拿出另一张图片,一个人坐在消防栓上。虽然算法没见过这张图片,但能够表达出这是“一个人坐在消防栓上”。

类似的,算法能识别出“一匹马戴着帽子”,虽然训练集里只有“人骑马”以及“人戴着帽子”的图片。

在李飞飞团队的 ECCV 2016 论文之后,今年有一大堆相关论文发表了出来,一些甚至已经超过了他们模型的表现。她也非常欣喜看到这项任务相关研究的繁荣发展。
在物体识别问题已经很大程度上解决以后,李飞飞的下一个目标是走出物体本身。微软的Coco数据集就已经不再是图像+标签,而是图像+一个简短的句子描述图像中的主要内容。
经过三年的准备后,李飞飞团队推出了Visual Genome数据集,包含了10万张图像、420万条图像描述、180万个问答对、140万个带标签的物体、150万条关系以及170万条属性。这是一个非常丰富的数据集,它的目标就是走出物体本身,关注更为广泛的对象之间的关系、语言、推理等等。

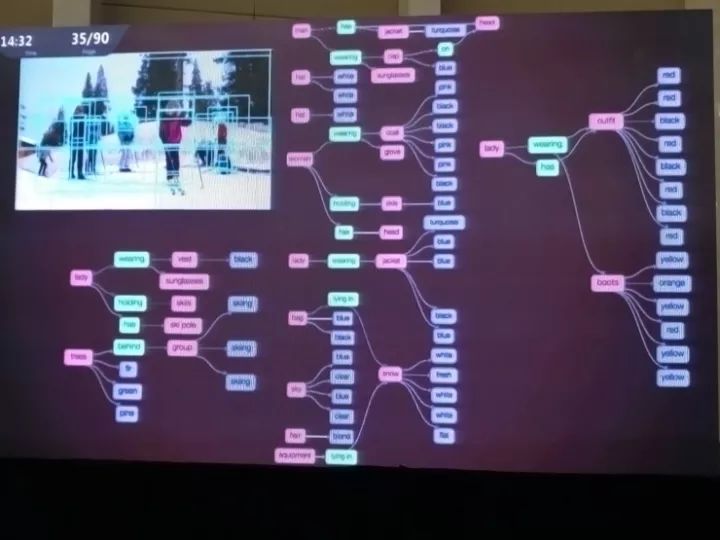
在Visual Genome数据集之后,李飞飞团队做的另一项研究是重新认识场景识别。
场景识别单独来看是一项简单的任务,在谷歌里搜索“穿西装的男人”或者“可爱的小狗”,都能直接得到理想的结果。
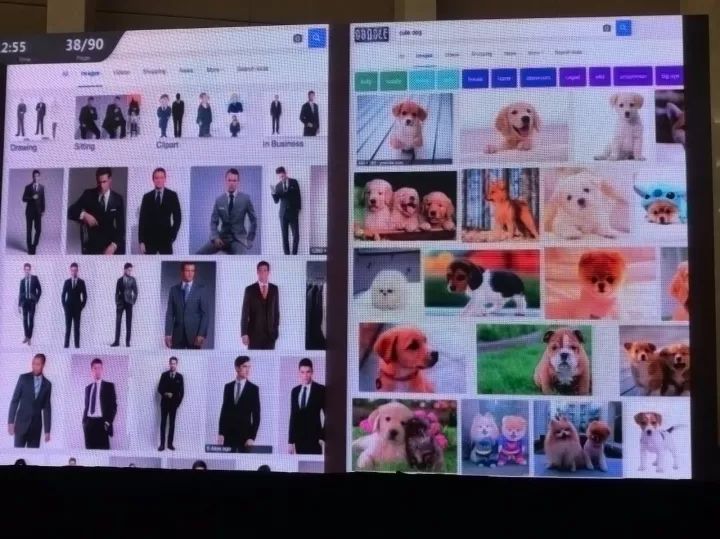
但是当你搜索“穿西装的男人抱着可爱的小狗”的时候,就得不到什么好结果。它的表现在这里就变得糟糕了,这种物体间的关系是一件很难处理的事情。
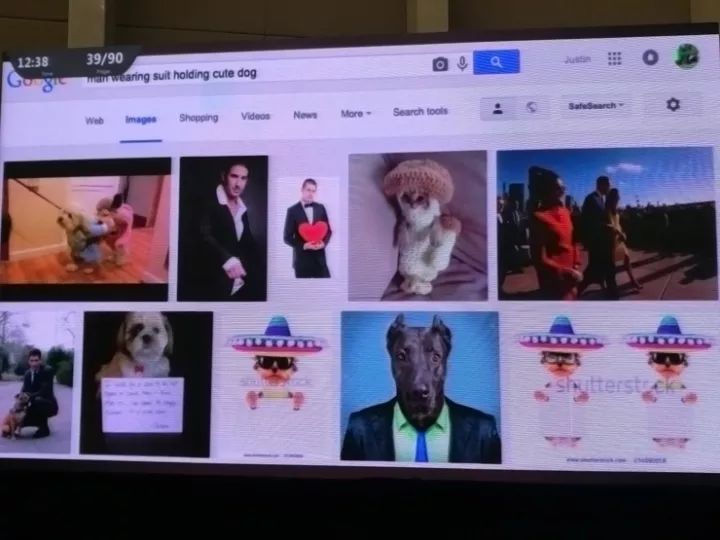
如果只关注了“长椅”和“人”的物体识别,就得不到“人坐在长椅上”的关系;即便训练网络识别“坐着的人”,也无法保证看清全局。

他们有个想法是,把物体之外、场景之内的关系全都包含进来,然后再想办法提取精确的关系。

如果有一张场景图(graph),其中包含了场景内各种复杂的语义信息,那场景识别就能做得好得多。其中的细节可能难以全部用一个长句子描述,但是把一个长句子变成一个场景图之后,我们就可以用图相关的方法把它和图像做对比;场景图也可以编码为数据库的一部分,从数据库的角度进行查询。
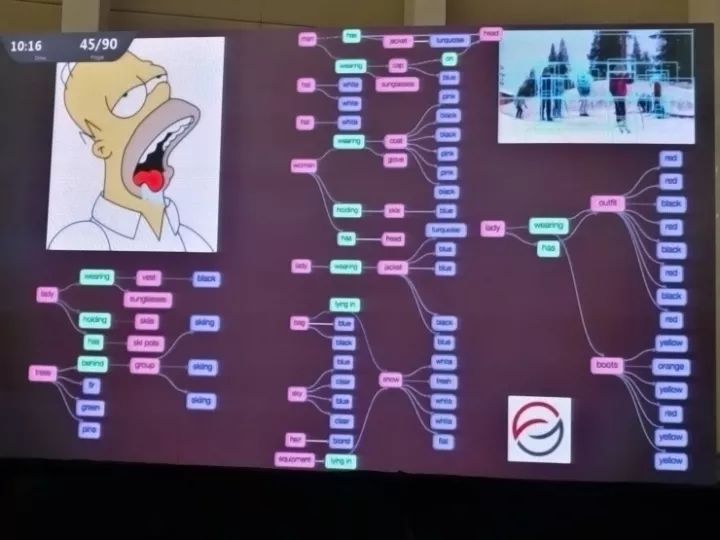
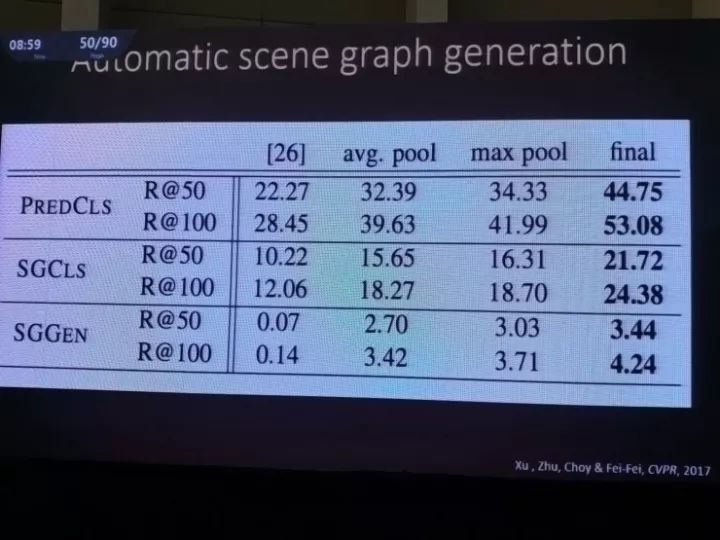
李飞飞团队已经用场景图匹配技术在包含了许多语义信息的场景里得到了许多不错的量化结果。不过,这些场景图是谁来定义的呢?在Visual Genome数据集中,场景图都是人工定义的,里面的实体、结构、实体间的关系和到图像的匹配都是李飞飞团队人工完成的,过程挺痛苦的,他们也不希望以后还要对每一个场景都做这样的工作。所以在这项工作之后,他们也正在把注意力转向自动场景图生成。

比如这项她和她的学生们共同完成的CVPR2017论文就是一个自动生成场景图的方案,对于一张输入图像,首先得到物体识别的备选结果,然后用图推理算法得到实体和实体之间的关系等等;这个过程都是自动完成的。
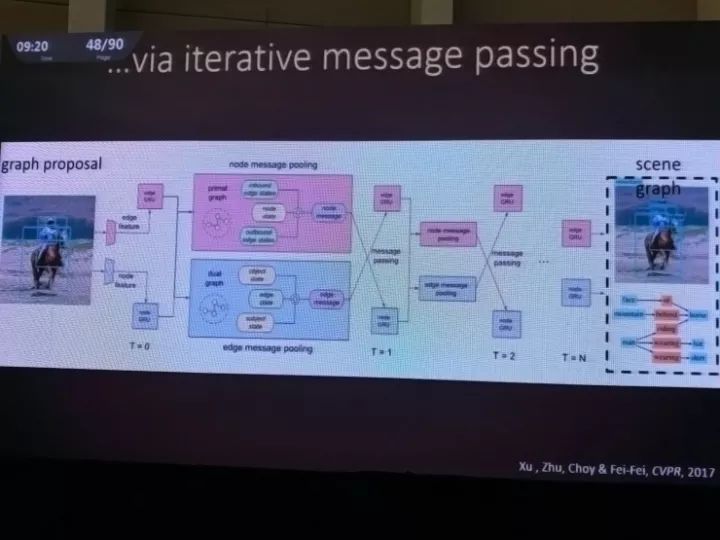
这里涉及到了一些迭代信息传递算法,李飞飞并没有详细解释。但这个结果体现出的是,这个模型的工作方式和人的做法已经有不少相似之处了。

这代表着一组全新的可能性来到了人类面前。借助场景图,们可以做信息提取、可以做关系预测、可以理解对应关系等等。
QA问题也得到了更好的解决。

还有一个研究目标是,给图片配上整段的说明文字。
当李飞飞在加州理工学院读博士的时候做过一个实验,就让人们观察一张照片,然后让他们尽可能地说出自己在照片中看到的东西。当时做实验的时候,在受试者面前的屏幕上快速闪过一张照片,然后用一个别的图像、墙纸一样的图像盖住它,它的作用是把他们视网膜暂留的信息清除掉。
接下来就让他们尽可能多地写下自己看到的东西。从结果上看,有的照片好像比较容易,但是其实只是因为我们选择了不同长短的展示时间,最短的照片只显示了27毫秒,这已经达到了当时显示器的显示速度上限;有些照片显示了0.5秒的时间,对人类视觉理解来说可算是绰绰有余了。

对于这张照片,时间很短的时候看清的内容也很有限,500毫秒的时候他们就能写下很长一段。进化给了我们这样的能力,只看到一张图片就可以讲出一个很长的故事。
在过去的3年里,CV领域的研究人员们就在研究如何把图像中的信息变成故事。

他们首先研究了图像说明,比如借助CNN把图像中的内容表示到特征空间,然后用LSTM这样的RNN生成一系列文字。这类工作在2015年左右有很多成果,从此之后我们就可以让计算机给几乎任何东西配上一个句子。

比如这两个例子,“一位穿着橙色马甲的工人正在铺路”和“穿着黑色衬衫的男人正在弹吉他”。


这都是CVPR2015上的成果。两年过去了,李飞飞团队的算法也已经不是最先进的了,不过那时候确实是是图像说明这个领域的开拓性工作之一。
沿着这个方向继续做研究,他们迎来的下一个成果是稠密说明,就是在一幅图片中有很多个区域都会分配注意力,这样有可以有很多个不同的句子描述不同的区域,而不仅仅是用一个句子描述整个场景。在这里就用到了CNN模型和逻辑区域检测模型的结合,再加上一个语言模型,这样就可以对场景做稠密的标注。
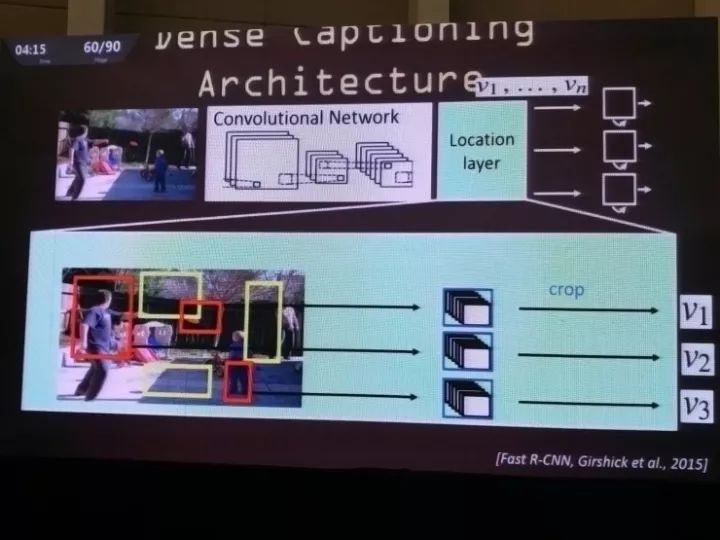
比如这张图里就可以生成,“有两个人坐在椅子上”、“有一头大象”、“有一棵树”等等

另一张李飞飞的学生们的室内照片也标出了丰富的内容。

在最近的CVPR2017的研究中,他们让表现迈上了一个新的台阶,不只是简单的说明句子,还要生成文字段落,把它们以具有空间意义的方式连接起来。这样我们就可以写出“一只长颈鹿站在树边,在它的右边有一个有叶子的杆子,在篱笆的后面有一个黑色和白色的砖垒起来的建筑”,等等。虽然里面有错误,而且也远比不上莎士比亚的作品,但我们已经迈出了视觉和语言结合的第一步。

而且,视觉和语言的结合并没有停留在静止的图像上,刚才的只是最新成果之一。在另外的研究中,他们把视频和语言结合起来。

比如这个CVPR2017的研究,可以对一个说明性视频中不同的部分做联合推理、整理出文本结构。这里的难点是解析文本中的实体,比如第一步是“搅拌蔬菜”,然后“拿出混合物”。如果算法能够解析出“混合物”指的是前一步里混合的蔬菜,那就棒极了。

在语言之后,李飞飞还介绍了任务驱动的视觉问题。对整个AI研究大家庭来说,任务驱动的AI是一个共同的长期梦想,从一开始人类就希望用语言给机器人下达指定,然后机器人用视觉方法观察世界、理解并完成任务。
这是一个经典的任务驱动问题,人类说:“蓝色的金字塔很好。我喜欢不是红色的立方体,但是我也不喜欢任何一个垫着5面体的东西。那我喜欢那个灰色的盒子吗?” 那么机器,或者机器人,或者智能体就会回答:“不,因为它垫着一个5面体”。它就是任务驱动的,对这个复杂的世界做理解和推理。

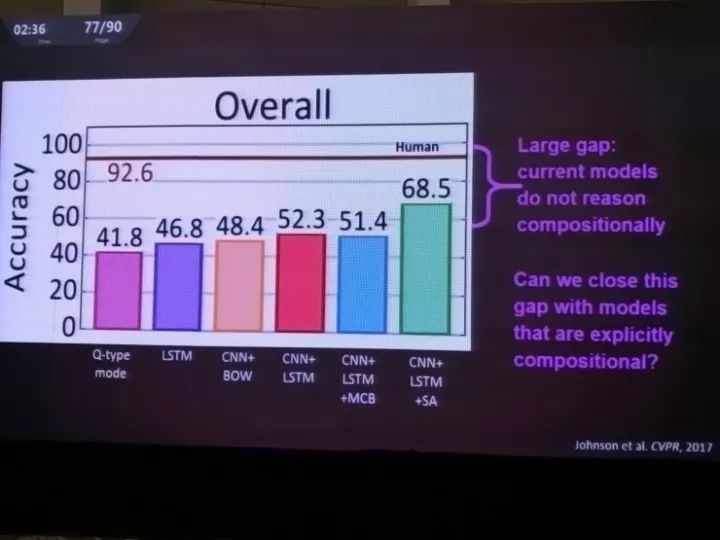
李飞飞团队和Facebook合作重新研究这类问题,创造了带有各种几何体的场景,然后给人工智能提问,看它会如何理解、推理、解决这些问题。这其中会涉及到属性的辨别、计数、对比、空间关系等等。

在这方面的第一篇论文用了CNN+LSTM+注意力模型,结果算不上差,人类能达到超过90%的正确率,机器虽然能做到接近70%了,但是仍然有巨大的差距。有这个差距就是因为人类能够组合推理,机器则做不到。
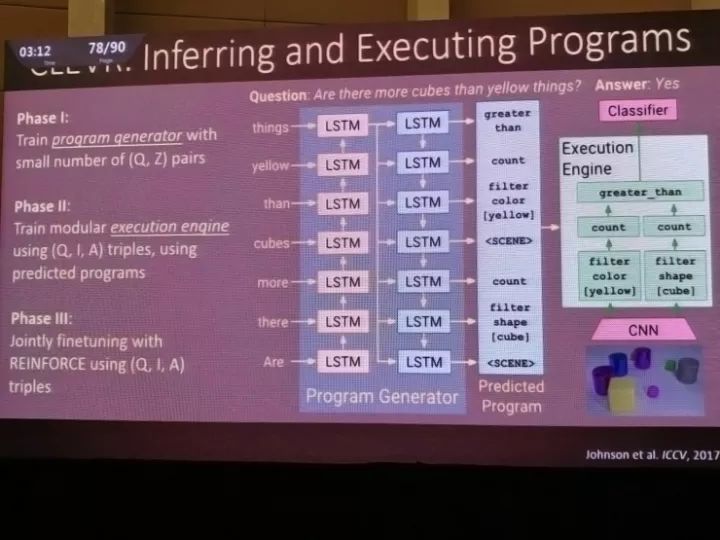
而在ICCV 2017上,他们介绍了新一篇论文中的成果。借助新的CLEVR数据集,把一个问题分解成带有功能的程序段,然后在程序段基础上训练一个能回答问题的执行引擎。这个方案在尝试推理真实世界问题的时候就具有高得多的组合能力。
在测试中也终于超出了人类的表现。
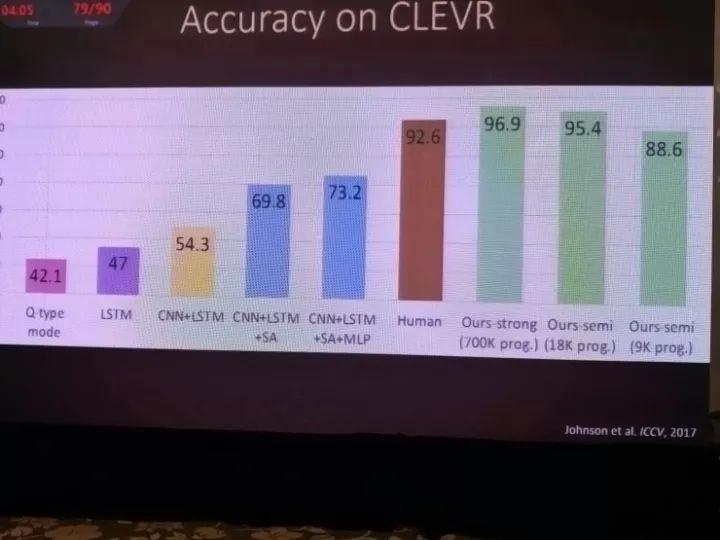
模型的实际表现当然不错。比如这个例子里,我们提问某种颜色的东西是什么形状的,它就会回答“是一个立方体”这样,表明了它的推理是正确的。它还可以数出东西的数目。这都体现出了算法可以对场景做推理。热力图也展示出了模型正确地关注了图中的区域。

图像相关的任务说了这么多,李飞飞把它们总结为了两大类
首先是除了物体识别之外的关系识别、复杂语意表征、场景图;
在场景gist之外,我们需要用视觉+语言处理单句标注、段落生成、视频理解、联合推理;

李飞飞最后展示了她女儿的照片,她只有20个月大,但视觉能力也是她的日常生活里重要的一部分,读书、画画、观察情感等等,这些重大的进步都是这个领域未来的研究目标。

视觉智慧是理解、交流、合作、交互等等的关键一步,人类在这方面的探索也只称得上是刚刚开始。

(完)
复旦大学Ph.D沈志强:用于目标检测的DSOD模型(ICCV 2017)
AI科技评论按,目标检测作为一个基础的计算机视觉任务,在自动驾驶、视频监控等领域拥有非常广泛的应用前景。目前主流的目标检测方法都严重依赖于在大规模数据集(如ImageNet)上预训练初始模型。而在DSOD: Learning Deeply Supervised Object Detectors from Scratch这篇论文中,作者通过分析深度检测模型从头训练存在的问题,提出了四个原则,他们根据这些原则构建了DSOD模型,该模型在三个标准数据集(PASCAL VOC 07, 12和COCO)上都达到了顶尖的性能。这篇论文已被ICCV2017收录。
在近期雷锋网 AI研习社的线上分享会上,该论文的第一作者——复旦大学Ph.D沈志强为我们带来了对DSOD的详细解读,与此同时也介绍了他在CVPR 2017和ICCV 2017上的一些其它研究工作。
沈志强,复旦大学Ph.D,UIUC ECE系访问学者,导师Thomas S. Huang教授。研究兴趣包括:计算机视觉(目标检测、视频描述、细粒度分类等),深度学习,机器学习等。他曾在因特尔中国研究院(Intel Labs China)进行为期一年的实习研究,期间合作者包括研究院Jianguo Li博士和在读博士生Zhuang Liu等。
分享内容:
很高兴与大家分享我们的最新的工作DSOD,这篇论文已经被ICCV 2017 所收录。

众所周知,计算机视觉有几个比较重要的分类,包括目标分类、定位、目标检测、实例分割,前两个分类是针对单个目标,后两个分类是针对多个目标,DSOD主要是针对目标检测。
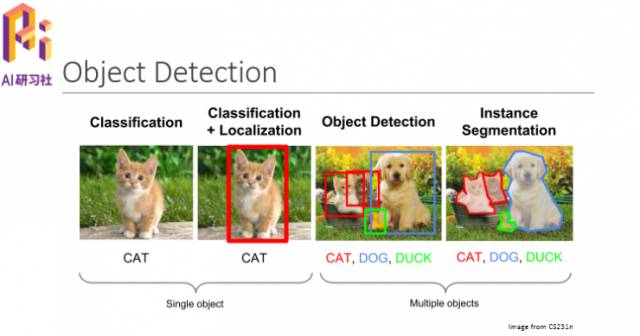
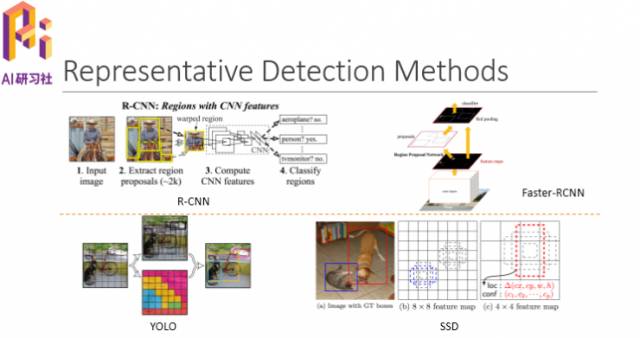
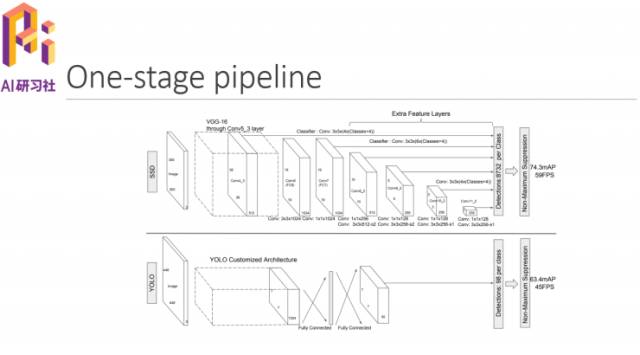
说到目标检测,大家可能会想到如下几个比较有代表性的方法:R-CNN、Faster-RCNN、YOLO、SSD。下图是关于他们的一些介绍。
ImageNet预训练模型的限制:一是模型结构是固定的,你不可能改变它的结构,二是会有learning bias,三是会出现domain不匹配的情况。我们的思路是从头训练检测器,但是我们用R-CNN和Faster-RCNN都没能得到较好的表现。

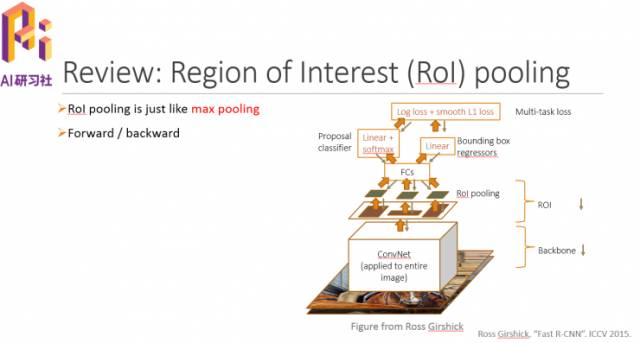
简单回顾下Rol pooling,如下图所示:
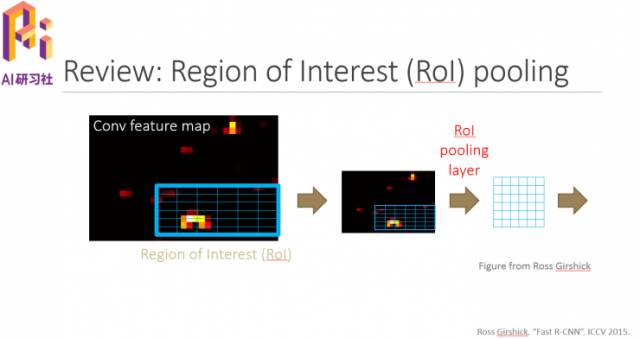
它其实就是一个max pooling:
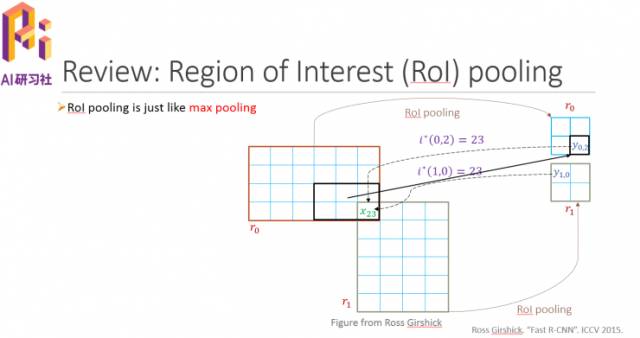
可以在下图中看到forward和backward情况,把Rol pooling去掉这个框架就类似于YOLO和SSD。
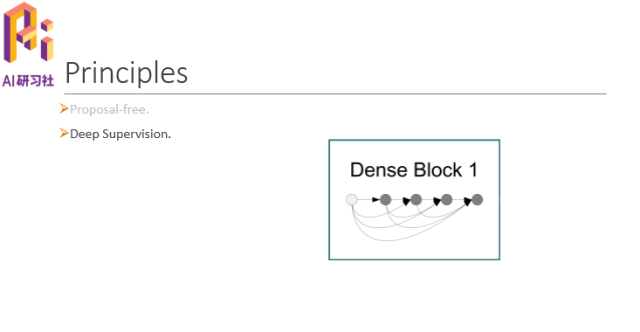
几个原则:一是Proposal-free。去掉Rol pooling,虽然对模型的表现影响不大,但这一点非常重要。

二是Deep Supervision。采用Dense Block,能避免梯度消失的情况。
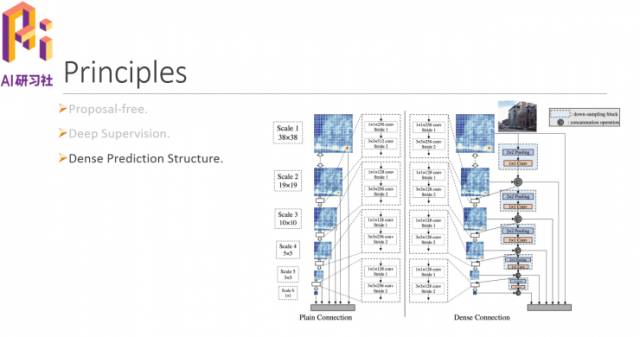
三是Dense Prediction Structure。大大减少了模型的参数量,特征包含更多信息。
四是Stem Block。采用stem结构,好处是能减少输入图片信息的丢失。
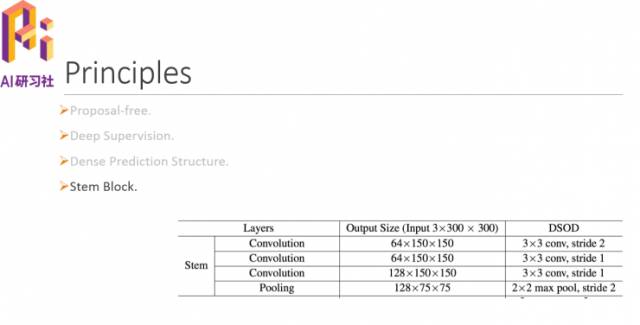
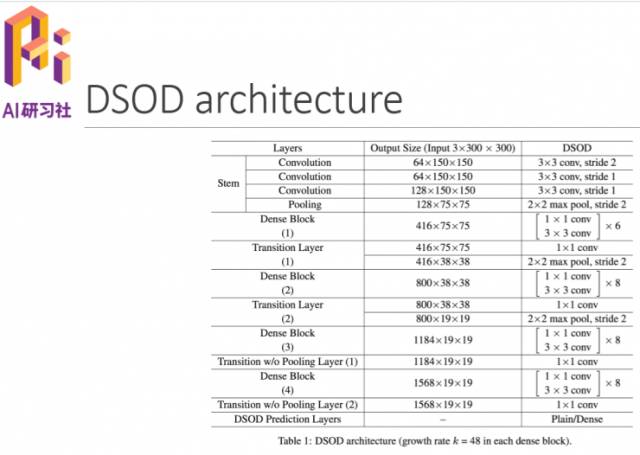
下面是DSOD整体结构:
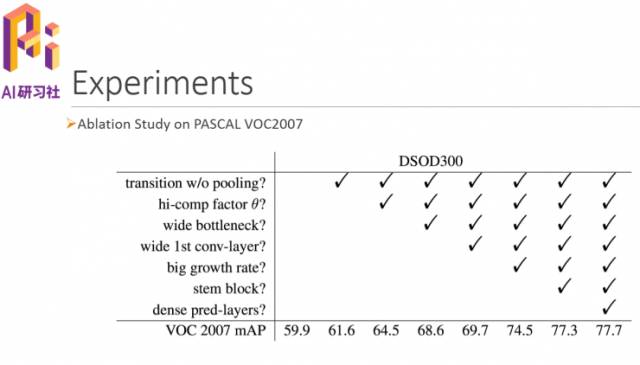
这是我们做的一些对比实验,可以看到增加这些结构之后性能提升的百分点:
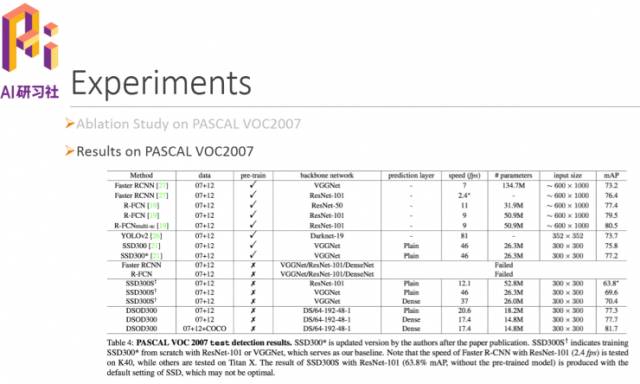
下面是在PASCAL VOC2007上的实验结果,可以看到Faster-RCNN和R-CNN速度很慢,YOLO和SSD的速度非常快,但是mAP不高。最下面是我们没有用预训练模型做的一些对比实验,可以看到Faster-RCNN和R-CNN均以失败告终,最后的一行的实验加入COCO后mAP值提升,说明DSOD模型本身的泛化能力非常强。
下面是在PASCAL VOC2012上的实验结果,可以看到DSOD有不错的mAP值。

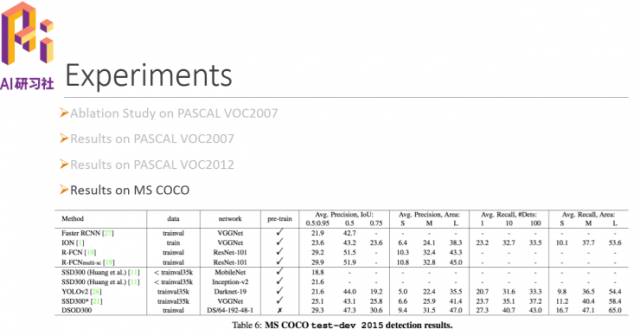
接下来是在COCO上面的一些结果,对比起来DSOD的也有很好的性能。
最后是一些实际的检测结果,可以看到bounding box对目标的检测非常贴合。

论文地址: https://arxiv.org/abs/1708.01241
代码:https://github.com/szq0214/DSOD
模型可视化示例:http://ethereon.github.io/netscope/#/gist/b17d01f3131e2a60f9057b5d3eb9e04d

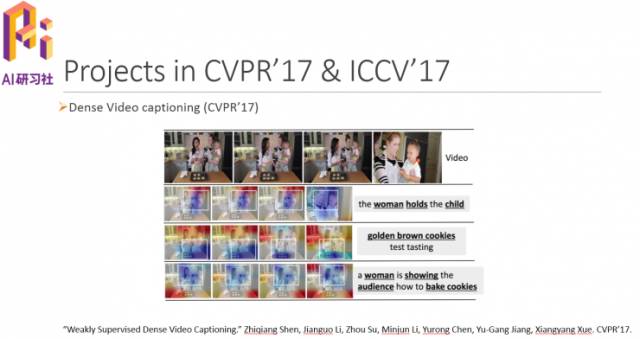
最后简单介绍下我们在CVPR 2017的相关工作Dense Video captioning,主要是做视频描述。在视频当中包含很多内容,而这些内容并不一致,因此视频描述相对来说会比较困难。下图是一些示例。
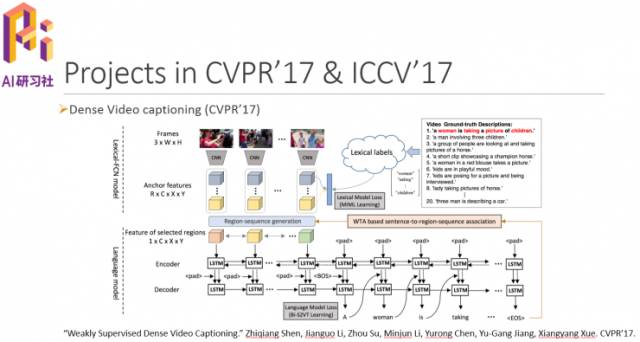
网络结构如下图所示。具体细节大家可以参见我们的论文Weakly Supervised Dense Video Captioning,论文地址:https://arxiv.org/abs/1704.01502
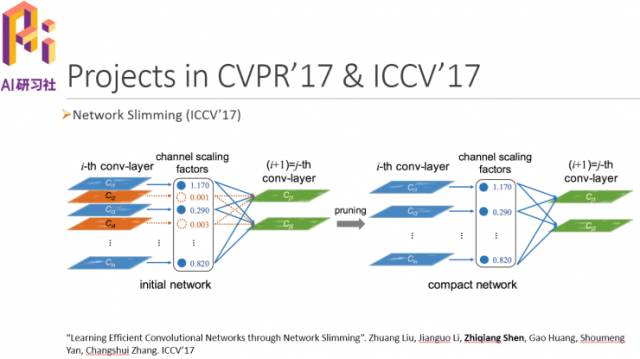
接下来是我们在ICCV 2017上的工作,主要是做网络压缩。我们用了一个衡量channel是否重要的值来训练模型,然后剔除掉不太重要的特征层。论文代码我们也放在github上了。具体细节大家可以参见论文Learning Efficient Convolutional Networks through Network Slimming,论文地址:https://arxiv.org/abs/1708.06519
本次分享的视频如下:
AI科技评论整理编辑。
CVaaS计算机视觉即服务 ——从算法,应用到服务的技术演变
本文是大数据杂谈5月4日社群分享内容整理。
我先自我介绍一下,我叫罗韵,是深圳极视角科技有限公司联合创始人,我们公司是一家做人工智能和计算机视觉应用的创业公司,我们平台目前服务各个细分领域,其中包括零售行业、工业、智能家居、餐饮、安防等,提供图像处理和视频分析的服务。作为一家创业公司,极视角荣登"2016 中国人工智能创业公司 Top50"以及入选"2017 国内最值得关注的 AI 视觉创业项目 Top20"。当前我们正在做的事情就是希望让计算机视觉变成一种可以服务于各行各业的服务平台——极市平台 cvmart.net。
今天给大家介绍内容包括四个部分(如上图),其中是一环扣一环步步递进的,从两个算法 (并非原创算法) 切入,我们看一个算法如何被应用,然后基于各种应用的需求,算法又如何转化成为一个服务去服务更多的社会需要。

我的分享总体来说会更偏应用性,因为我们主要就是做 CV 应用。
首先,给大家介绍一个很常见而非常有应用前景的算法应用案例:识别一个图片或者画面、视频里面可能有什么东西?例如如图:

要实现这样识别算法,当前我们可以结合深度学习的目标检测算法,例如有 R-CNN,SPP-Net,Fast R-CNN,Faster R-CNN,以及在 PASCAL VOC、MS COCO、ILSVRC 数据集上取得领先的基于 Faster R-CNN 的 ResNet 等。
以上的方法都可以归纳为一个基本流程:proposal 候选框 + 分类器,只是有的候选框从原图就定位了,而有的 bounding box 候选框则是通过 feature map 来定位。而这样的流程在运行速度上会存在着比较大的局限。当然,大家也在不断的往更快的速度去优化。
而我们今天先不讨论上述的方法,而是讨论两个运行速度更快的目标检测模型。
第一个是,YOLO(You Only Look Once),YOLO 是一个可以一次性预测多个 Box 位置和类别的卷积神经网络,能够实现端到端的目标检测和识别,其最大的优势就是速度快。目标检测的本质其实也是回归,因此一个实现回归功能的 CNN 并不需要复杂的设计过程。
YOLO 没有选择滑窗或提取 proposal 的方式训练网络,而是直接选用整图训练模型。这样做的好处在于可以更好的区分目标和背景区域,相比之下,采用 proposal(选定候选集) 训练方式的 Fast-R-CNN 常常把背景区域误检为特定目标。
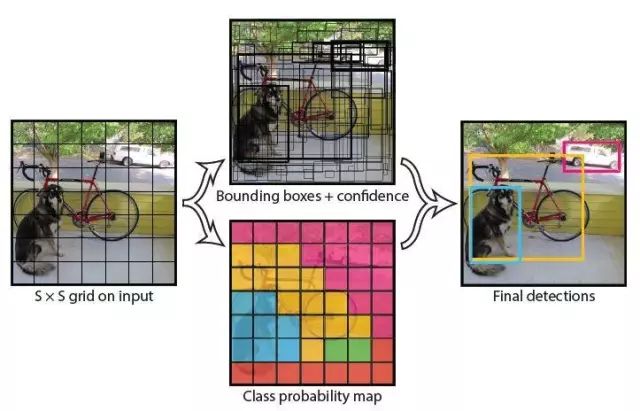
YOLO 的设计理念遵循端到端训练和实时检测。YOLO 将输入图像划分为 S*S 个网络,如果一个物体的中心落在某网格 (cell) 内,则相应网格负责检测该物体。
在训练和测试时,每个网络预测 B 个候选区域,每个候选区域对应 5 个预测参数,分别是候选区域 (bounding box) 的中心点坐标 (x,y), 宽高 (w,h) 和置信度评分。
这里的置信度评分:
(Pr(Object)*IOU(pred|truth))
综合反映基于当前模型候选区域内存在目标的可能性 Pr(Object) 和候选区域 (bounding box) 预测目标位置的准确性 IOU(pred|truth)。
如果候选区域内不存在物体,则 Pr(Object)=0。如果存在物体,则根据预测的候选区域 (bounding box) 和真实的区域 (bounding box) 计算 IOU,同时会预测存在物体的情况下该物体属于某一类的后验概率 Pr(Class_i|Object)。
假定一共有 C 类物体,那么每一个网格只预测一次 C 类物体的条件类概率 Pr(Class_i|Object), i=1,2,...,C; 每一个网格预测 B 个候选区域 (bounding box) 的位置。即这 B 个候选区域 (bounding box) 共享一套条件类概率 Pr(Class_i|Object), i=1,2,…,C。
基于计算得到的 Pr(Class_i|Object),在测试时可以计算某个候选区域 (bounding box) 类相关置信度:
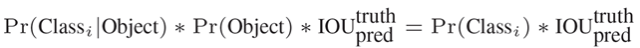
如果将输入图像划分为 7*7 网格(S=7),每个网格预测 2 个 bounding box (B=2),有 20 类待检测的目标(C=20),则相当于最终预测一个长度为 S*S*(B*5+C)=7*7*30 的向量,从而完成检测和识别任务。
第二个同样是目标检测的算法,SSD(Single Shot MultiBox Dectector)。这是另一个基于深度学习的物体检测模型,他的特点主要是检测的速度在能保证精度下保持非常快的速度,除此之外,该物体检测算法在大目标的检测下有比较好的效果。
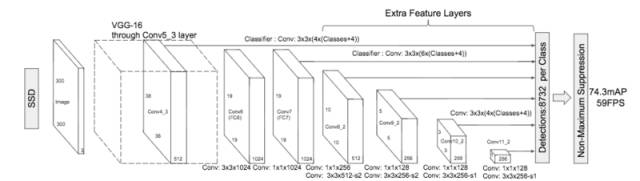
而我们发现,往往我们的照片中,大目标比比皆是。SSD 比原先最快的 YOLO: You Only Look Once 方法,还要快,还要精确。保证速度的同时,其结果的 mAP 可与使用 region proposals 技术的方法(如 Faster R-CNN)相媲美。
SSD 方法的核心就是预测物体,以及其归属类别的得分;同时,在 feature map 上使用小的卷积核,去预测一系列候选区域的位置。
SSD 为了得到高精度的检测结果,在不同层次的 feature maps 上去 预测物体类别和物体位置。
SSD 这些改进设计,能够在当输入分辨率较低的图像时,保证检测的精度。同时,这个整体端到端的设计,训练也变得简单。在检测速度、检测精度之间取得较好的平衡。
然而,以上的仅仅是一个照片内容识别的算法,还没有真正的成为到了一个解决实际问题的应用,接下来,我们将讲解的就是利用这样的识别技术,我们进一步可以解决的问题就是:
在印刷行业或者快照行业,会陆续推出一项产品——电子相册。
而电子相册从技术层面主要是要解决两个问题,1. 照片裁剪,2. 相框的匹配。
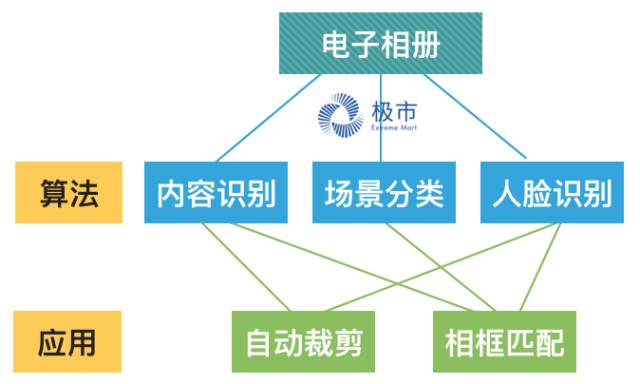
而当前,这些工作都是人工去完成,随着日益增长的电子图片的需求量,制作电子相册的人力成本越来越大,而这个时候,利用之前所述的内容识别算法,我们可以帮助电脑自动实现图片的裁剪,因为自动裁剪最大的担忧可能是担心把照片内的人裁剪掉了。
另一方面,我们进而可以结合图片场景分类和人脸识别等算法技术,使用标签匹配方法去自动匹配与照片本身更搭配的相框。
如上,我们就以快照印刷行业的电子相册作为一个行业应用的例子,但其实还有很多行业内容其他的应用例子不胜枚举。
算法本身我们可以做出很多技术,例如使用物体检测我们可以实现内容识别、除此之外我们还实现场景分类、人脸的识别、颜色的分类、人物表情等等。
而技术项目的组合,可以帮助我们是去实现更多行业内的目前人工完成的工作,例如实现自动裁剪、通过根据图片的内容、场景的分类、人脸信息等,匹配出合适的相框作为推荐,根据不同颜色的印刷材料做不同的印刷批次排序等等。
于是,一个简单的印刷快照行业的升级,我们可以归纳为如图:
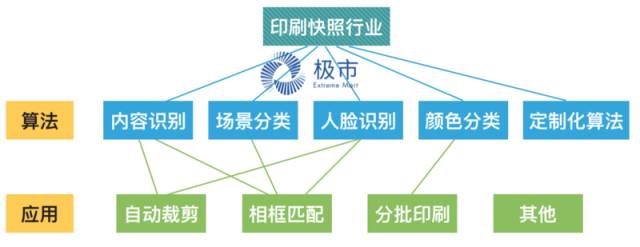
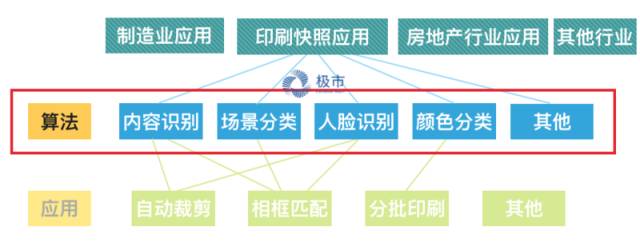
而由图中,我们可以看到,技术和应用本质上是完全可以分开做横向拓展的,于是我们可以看到同样的技术可以用在不同的行业,也可以有很多不同行业特定的算法技术,如图:
CVaaS 是我概括出来的一个词语,第一次介绍给大家,意思就是计算机视觉算法即服务的意思,在过往,我们可能听说过,IaaS(Infrastructure as a Service),PaaS(Platform as a Service),SaaS(Software as a Service), 大家都把不同层次的标准化模块变成一种服务在提供。
而 CVaaS 就是 Computer Vision as a Service, 我们把 CV 的部分标准化成为了一种服务,而每一个行业可以在这里找到自己行业需要的和图像处理、视频处理、计算机视觉相关的算法服务,然后他们可以整合这些算法服务成为他们需要的应用。
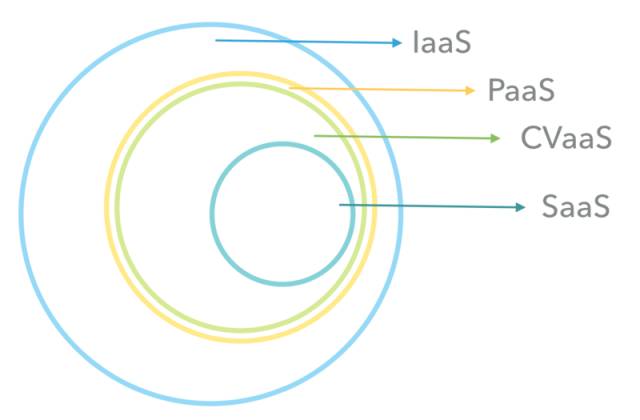
而 CV 算法更接近于一种平台运行的服务,提供运算性能的横向拓展,提供运算的底层开发环境,甚至乎直接提供可开发测试的 sandbox, 所以,CVaaS 也是 PaaS 的一种。
各行各业都有他需要的和 AI 取代的工作,从而提升行业的效率,正如李开复老师说的,50% 的工作会被 AI 取代,而评判的标准就是“五秒钟准则”。
“五秒钟准则”:一项本来由人从事的工作,如果人可以在 5 秒钟以内对工作中需要思考和决策的问题做出相应的决定,那么这项工作就非常大的可能被人工智能技术全部或部分取代。
而 CVaaS 的目的,就是让各行各业可以以最快的形式和方式完成这要的一些工作的转变。
例如,在零售行业,我们选择可以选择人脸识别做 VIP 识别,选择行人识别做客流统计,选择性别、年龄识别做顾客分类或者顾客肖像。
在安防行业,我们选择动作 (打架) 识别、行人跟踪、姿态识别等做安全的防范和预警。
再例如,在房地产领域做场景图片的分类 (例如哪些图片是卧室,客厅,厨房),优质 (封面) 图片的挑选;印刷行业根据图片的内容做自动裁剪;等等。

极市 CVaaS 平台主要面向三个群体,具有算法服务开发能力的开发者,需要使用算法服务的行业用户以及海量和我们对接的硬件厂商。对于开发者,平台设计基于 Gitlab 的代码 (SDK) 管理,版本管理,Gitlab 是目前比较流行的开源类 Github 代码管理平台。
开发者可以提交自己认为满意的版本,对于不想提供源码的,可以提供 SDK 即可。对自己的算法的数据输入端,使用平台提供的输入 SDK 对接,可以对自己的算法进行场景使用和介绍做详细的描述,就想我们去 APP Store 提交一个 APP 一样。
此外,开发者拥有自己的管理后台,每天可以查询到自己的算法被使用和应用的情况,以及最新的收入。
我们也知道,对于 CV 或者 AI 类算法,最重要的莫过于数据集,所以,在平台设计中,我们增加了海量测试数据的模块,可以提供给不同应用的开发者测试集。
而每一个算法服务的运行,则基于 docker 的隔离运行,docker 用来隔离应用还是很方便的,一来本身的操作较为简单,二来资源占用也比虚拟机要小得多,三来也较为安全,因为像数据库这样的应用不会再全局暴露端口,同时应用间的通信通过加密和端口转发,更加安全。
基于海量硬件与我们系统的无缝链接,每一个在平台上的算法应用,即可面向近百万摄像机用户的使用可能。
所有平台的设计最终都是为了服务社会和个人,而 AI 作为当前的与社会紧密相同的技术,我们希望使得更多不同的行业用更轻松简单的方法与技术相结合,而我们这些懂技术的人,也可以有更多的方式去贡献我们的能力,这个就是我们极视角和我们的产品“极市”的初衷。
罗韵:开源社区其实有非常多非常优秀的项目,一开始如果能力不够,可以从看别人的代码开始,如果渐渐能读懂别人的代码,一般成熟的开源项目都有开发计划的,而且是公开的,有些功能是专门公开给社区去实现的,那就可以自己去实现,还有一种情况就是你发现了项目本身存在的问题或者 bug,然后你去完善好。
罗韵:是的。
罗韵:首先先确定你是有耐心和恒心愿意去读 PhD,毕竟也是好几年光阴,其次就是我觉得还是个人需要有自己的一点点小成果或者做出一点可以打动导师的东西,最后就是,工作中的积累也是很有用的,个人愚见,这个问题因人而异的。
罗韵:这个问题有点太泛了,具体还要看图像识别分类,做的是什么分类,分多少类,整体的项目程序的复杂度等,一般如果部署成功了,很多时候也要看具体场景的要求,例如场景要求实时,但是速度上就是无法支持,这个也是其中一些难点所在。
罗韵:优势有几个方面,第一,作为一个 CVaaS 其实就是一个连接技术与需求的桥梁,所以,我们首先已经拥有了大量的场景的硬件(摄像头)作为用户,所以,在这里的所有 Service 都不基本不用担心是否有人使用的问题,只要是好的 CV Service,都有对应的潜在用户。
第二,你的运算能力方面和运维都有我们整个平台作为支持,开发者可以更加关注算法的研发。
第三,我们目前应该是拥有着最大量的一线数据可以做算法测试。
罗韵:这个,今天没有说到,但是这个确实是我们公司的其中一个产品,新零售的解决方案,主要解决三个核心问题,全自动采集数据 + 构建数据分析框架 + 业务驱动的数据分析。
罗韵:作为开发者,不用太担心什么算法可以放到我们平台,我们底层会对算法做自动测试与审核,审核通过了,自然就是被使用的。
罗韵:嗯!加油!可以从写项目文档开始其实,很多入门的开源社区的新手都是先从帮项目写文档开始的,当然,写之前就意味着你要先慢慢理解每一个 sample/demo。
罗韵:我们官网(http://www.extremevision.com.cn/)上展示出来的客户名单,国内外的知名零售连锁品牌都有是我们客户,太多,我这里就不一一罗列,运营效果,我觉得还是市场说的算,目前我们的客户增长率就是最好的证明。
罗韵:两个技术没有冲突,其实都是可以应用的,物体检测主要是用于对图像做自动裁剪比较多,图像语义理解更多的是为了还要做搜索或者推荐,如果是以搜索为主要任务的话,做检测后加上语义理解会更好。
作者介绍
罗韵,极视角科技联合创始人,香港科技大学人工智能 PhD candidate,TensorFlow contributor。实现过基于云端的计算机视觉分析系统和企业早期计算机视觉的算法研发。接触过接近百种人工智能算法的应用,覆盖行业包括零售、交通、安防、公共资源、环境、金融、医疗、娱乐等,对 AI 算法的应用化场景了解丰富,目标是让未来的 AI 产品可以和 APP Store 里面的应用一样丰富。著有知乎专栏人工智能应用系列(https://zhuanlan.zhihu.com/ai4application)。
本文授权转自大数据杂谈(微信号:BigdataTina2016)。

人工智能赛博物理操作系统
AI-CPS OS
“人工智能赛博物理操作系统”(新一代技术+商业操作系统“AI-CPS OS”:云计算+大数据+物联网+区块链+人工智能)分支用来的今天,企业领导者必须了解如何将“技术”全面渗入整个公司、产品等“商业”场景中,利用AI-CPS OS形成数字化+智能化力量,实现行业的重新布局、企业的重新构建和自我的焕然新生。
AI-CPS OS的真正价值并不来自构成技术或功能,而是要以一种传递独特竞争优势的方式将自动化+信息化、智造+产品+服务和数据+分析一体化,这种整合方式能够释放新的业务和运营模式。如果不能实现跨功能的更大规模融合,没有颠覆现状的意愿,这些将不可能实现。
领导者无法依靠某种单一战略方法来应对多维度的数字化变革。面对新一代技术+商业操作系统AI-CPS OS颠覆性的数字化+智能化力量,领导者必须在行业、企业与个人这三个层面都保持领先地位:
重新行业布局:你的世界观要怎样改变才算足够?你必须对行业典范进行怎样的反思?
重新构建企业:你的企业需要做出什么样的变化?你准备如何重新定义你的公司?
重新打造自己:你需要成为怎样的人?要重塑自己并在数字化+智能化时代保有领先地位,你必须如何去做?
AI-CPS OS是数字化智能化创新平台,设计思路是将大数据、物联网、区块链和人工智能等无缝整合在云端,可以帮助企业将创新成果融入自身业务体系,实现各个前沿技术在云端的优势协同。AI-CPS OS形成的数字化+智能化力量与行业、企业及个人三个层面的交叉,形成了领导力模式,使数字化融入到领导者所在企业与领导方式的核心位置:
精细:这种力量能够使人在更加真实、细致的层面观察与感知现实世界和数字化世界正在发生的一切,进而理解和更加精细地进行产品个性化控制、微观业务场景事件和结果控制。
智能:模型随着时间(数据)的变化而变化,整个系统就具备了智能(自学习)的能力。
高效:企业需要建立实时或者准实时的数据采集传输、模型预测和响应决策能力,这样智能就从批量性、阶段性的行为变成一个可以实时触达的行为。
不确定性:数字化变更颠覆和改变了领导者曾经仰仗的思维方式、结构和实践经验,其结果就是形成了复合不确定性这种颠覆性力量。主要的不确定性蕴含于三个领域:技术、文化、制度。
边界模糊:数字世界与现实世界的不断融合成CPS不仅让人们所知行业的核心产品、经济学定理和可能性都产生了变化,还模糊了不同行业间的界限。这种效应正在向生态系统、企业、客户、产品快速蔓延。
AI-CPS OS形成的数字化+智能化力量通过三个方式激发经济增长:
创造虚拟劳动力,承担需要适应性和敏捷性的复杂任务,即“智能自动化”,以区别于传统的自动化解决方案;
对现有劳动力和实物资产进行有利的补充和提升,提高资本效率;
人工智能的普及,将推动多行业的相关创新,开辟崭新的经济增长空间。
给决策制定者和商业领袖的建议:
超越自动化,开启新创新模式:利用具有自主学习和自我控制能力的动态机器智能,为企业创造新商机;
迎接新一代信息技术,迎接人工智能:无缝整合人类智慧与机器智能,重新
评估未来的知识和技能类型;
制定道德规范:切实为人工智能生态系统制定道德准则,并在智能机器的开
发过程中确定更加明晰的标准和最佳实践;
重视再分配效应:对人工智能可能带来的冲击做好准备,制定战略帮助面临
较高失业风险的人群;
开发数字化+智能化企业所需新能力:员工团队需要积极掌握判断、沟通及想象力和创造力等人类所特有的重要能力。对于中国企业来说,创造兼具包容性和多样性的文化也非常重要。
子曰:“君子和而不同,小人同而不和。” 《论语·子路》云计算、大数据、物联网、区块链和 人工智能,像君子一般融合,一起体现科技就是生产力。
如果说上一次哥伦布地理大发现,拓展的是人类的物理空间。那么这一次地理大发现,拓展的就是人们的数字空间。在数学空间,建立新的商业文明,从而发现新的创富模式,为人类社会带来新的财富空间。云计算,大数据、物联网和区块链,是进入这个数字空间的船,而人工智能就是那船上的帆,哥伦布之帆!
新一代技术+商业的人工智能赛博物理操作系统AI-CPS OS作为新一轮产业变革的核心驱动力,将进一步释放历次科技革命和产业变革积蓄的巨大能量,并创造新的强大引擎。重构生产、分配、交换、消费等经济活动各环节,形成从宏观到微观各领域的智能化新需求,催生新技术、新产品、新产业、新业态、新模式。引发经济结构重大变革,深刻改变人类生产生活方式和思维模式,实现社会生产力的整体跃升。
产业智能官 AI-CPS
用“人工智能赛博物理操作系统”(新一代技术+商业操作系统“AI-CPS OS”:云计算+大数据+物联网+区块链+人工智能),在场景中构建状态感知-实时分析-自主决策-精准执行-学习提升的认知计算和机器智能;实现产业转型升级、DT驱动业务、价值创新创造的产业互联生态链。


长按上方二维码关注微信公众号: AI-CPS,更多信息回复:
新技术:“云计算”、“大数据”、“物联网”、“区块链”、“人工智能”;新产业:“智能制造”、“智能农业”、“智能金融”、“智能零售”、“智能城市”、“智能驾驶”;新模式:“财富空间”、“特色小镇”、“赛博物理”、“供应链金融”。
点击“阅读原文”,访问AI-CPS OS官网
本文系“产业智能官”(公众号ID:AI-CPS)收集整理,转载请注明出处!
版权声明:由产业智能官(公众号ID:AI-CPS)推荐的文章,除非确实无法确认,我们都会注明作者和来源。部分文章推送时未能与原作者取得联系。若涉及版权问题,烦请原作者联系我们,与您共同协商解决。联系、投稿邮箱:erp_vip@hotmail.com



