完整学习目标检测中的 Recalls, Precisions, AP, mAP 算法(Part1)
点击上方“CVer”,选择加"星标"或“置顶”
重磅干货,第一时间送达

作者:Yanpeng Sun
https://zhuanlan.zhihu.com/p/79186684
本文已由作者授权,未经允许,不得二次转载
学习目标检测一定少不了的评测方式, 就是透过recalls, precisions, 来计算出类别的AP, 以及最后所有AP的平均值 mAP(mean Average Precision) 也就是我们最关心的数值
这边先简单的了解一下confusion matrix, 也就是所谓的混肴矩阵, 我个人不觉得这是一个很好的翻译, 最好记得英文就行, 在分类任务中这是一个非常重要的评测指标
下图是一个基本的confusion matrix
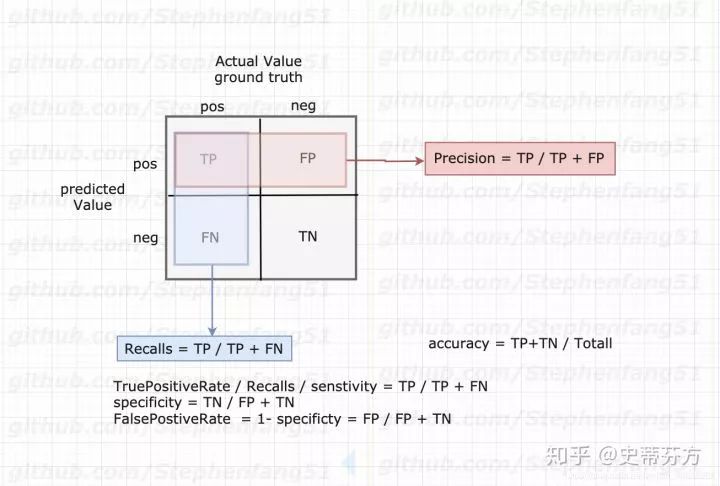
下面我直接带入例子会比较好解释
假设你的数据集一共是2分类, 第一类是人, 第二类是汽车
而测试集只有两张图片
Actual Value and Predicted Value
Actual value :实际的值, 在目标检测领域中, 我们可以理解为ground truth, 就是人或者是汽车在图片上的真实坐标
predicted value:这个就很好理解了, 就是指我们模型预测出来的坐标
pos 和 neg 这边不先定义, 我讲下去你就知道了
TP FP FN TN
这里通常很容易被弄混, 难怪叫做混肴矩阵, 跟着我的步伐走就没问题,强烈建议拿出纸笔把矩阵画一次就清楚了
TP (TruePositive): 正确预测出类别的 (正确识别为人或是汽车)
FP (FalsePositive):错误预测类别的 (人当成汽车)
FN(FalseNegative): ground truth中没有被检测到的
TN(TrueNegative):理论上来讲就是检测出不是这个类别的数量, 但是并不适用在目标检测领域, 因为通常一张图后会有非常多的bbox是没有检测到groundtruth的, 所以这无法计算, 并不影响, 因为也用不上
Recalls and Precisions
Recalls
可以叫做查全率又或者是召回率, 可以当做是所有类别x中预测为正确的
也就是
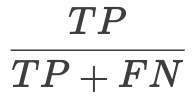
, 对应图片的蓝框公式很直观, 就是所有的ground truth(所有测试集中的样本每张图片上的人 或者 汽车的总数)里面检测出人 或者 汽车的数量
比如图中有5个标注为汽车的ground truth, 那么你检测到的汽车有两个, 那么对于这张图, 汽车类的 recalls 就是 2/5
Precisions
可以叫做精准率, 就是你检测到结果里面, 实际上真的正确的为多少?
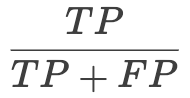
TP就是检测正确的, FP就是检测错误的, 那么加起来不就是你所有检测的结果? 对应图中红框
比如图中有3个人的ground truth, 你检测到的也是三个框, 但是其中只有一个框检测吻合到你的ground truth,另外两个检测成人了, TP = 1, FP = 2, 那么precision 就是 1/3
到这边如果没明白就先理清楚在往下看吧
首先来用mmdetection 的检测代码mean_ap.py来说明会更清晰
我不打算放出全部代码, 这样太乱了 我们看最主要的部分加深印象就行 !
首先看到eval_map这个函数, 看名字就很直观 evaluation mAP
1def eval_map(det_results,
2 gt_bboxes,
3 gt_labels,
4 gt_ignore=None,
5 scale_ranges=None,
6 iou_thr=0.5,
7 dataset=None,
8 print_summary=True):
说几个重要的参数就好
det_results 就是检测到的结果
gt_bboxes 就是ground truth 的框
gt_labels 就是类别标签, 比如人是1, 汽车是2
gt_ignore 这如果没有标注difficulty 不用理会
iou_thr 就是检测出的和groud truth 的 iou 阈值
也就是说如果要检测出recall precision mAP这些指标, 就要以上这些重要的值
那么计算recall precision 之前 我们就得先算出 TP FP FN 这些重要的指标, 所有一开始的矩阵是不是很重要?
函数tpfp_default 就是负责计算出TP FP的
我们需要以下参数, 注意该函数是针对单张图像的
1def tpfp_default(det_bboxes,
2 gt_bboxes,
3 gt_ignore,
4 iou_thr,
5 area_ranges=None):
我们的训练集只有两张
如果人label = 1, 汽车label=2, 下面直接用vector表示
第一张图label = [1, 1, 2, 1, 1] 也就是说有四个人一台车, 一共五个ground truth
第二张图 label = [2, 2, 1, 2] 三台车 一个人的ground truth
搬出ground truth
ground truth 最后面的#1 or #2表示label
1#groubd
2gt_bbox1 = np.array([[358, 288, 498, 387], #1
3 [356, 425, 525, 570], #1
4 [377, 119, 478, 189], #2
5 [180, 68, 314, 142], #1
6 [417, 159, 575, 240]], dtype=np.float32)#1
7
8gt_bbox2 = np.array([[258, 188, 398, 287], #2
9 [256, 325, 425, 470], #2
10 [277, 19, 378, 89], #1
11 [280, 168, 414, 242]], dtype=np.float32)#2
然后我们检测到的结果是下面这样, 都是bbox的坐标值, 一共两张图片, 图上都会有每个检测到的类别的坐标
检测到的结果 det_results
1'''det_results 图片 _ 类别'''
2det_results1_1 = np.array([[359, 289, 499, 388],
3 [346, 415, 515, 560],
4 [367, 109, 468, 179],
5 [190, 78, 324, 152],
6 [430, 172, 588, 253]], dtype=np.float32)
7
8det_results1_2 = np.array([[259, 189, 399, 288],
9 [236, 315, 415, 440],
10 [267, 9, 368, 79],
11 [290, 178, 424, 252]], dtype=np.float32)
12
13det_results2_1 = np.array([[359, 289, 499, 388],
14 [346, 415, 515, 560],
15 [367, 109, 468, 179],
16 [190, 78, 324, 152],
17 [430, 172, 588, 253],
18 [230, 72, 388, 53]], dtype=np.float32)
19
20det_results2_2 = np.array([[259, 189, 399, 288],
21 [236, 315, 415, 440],
22 [267, 9, 368, 79],
23 [290, 178, 424, 252],
24 [159, 89, 299, 188]], dtype=np.float32) #not ok
可以看出det_result1_1 表示第一张图的label 1 检测到的框
那么det_result2_2 就表示第二张图检测到label 2的框
所以可以总结
label1 一共检测出11个(TP+FP)
label2 一共检测出 9 个 (TP+FP)
好了, 回到tpfp_default
为了要检查出模型检测的是不是正确的, 也就是TP, 我们就用到了iou_thr这个阈值
一般会是0.5, 那么还要计算出IOU(交并比), 什么是IOU请直走左转找到人就问, 如果连这都写, 篇幅会太长
透过以下的函数进行计算
1ious = bbox_overlaps(det_bboxes, gt_bboxes)
得出来的ious会长这样子
1#这是label 1的第一张图检测与gt的ious结果
2 [[0.9665272 0. 0. 0. ]
3 [0. 0.7804878 0. 0. ]
4 [0. 0. 0. 0.05691057]
5 [0. 0. 0.6701031 0. ]
6 [0. 0. 0. 0.6295463 ]]
7
8#这是label1 的第二张图检测与gt的结果
9 [[0. ]
10 [0. ]
11 [0. ]
12 [0.03430409]
13 [0. ]
14 [0. ]]
1#这是label 2的第一张图检测与gt的ious结果
2 [[0.00107885]
3 [0. ]
4 [0. ]
5 [0.03430409]]
6
7 #这是label 2的第二张图检测与gt的ious结果
8 [[0.9665272 0. 0.36517328]
9 [0. 0.6413269 0. ]
10 [0. 0. 0. ]
11 [0.41336057 0. 0.6701031 ]
12 [0.00149158 0. 0.01764335]]
一脸懵?
没事的, 我刚看到也是懵
label1 图1 检测到的不是五个bbox吗 那么拿去和gt计算 就会有五个分数了
那图2 检测到的6个bbox 也当然就有6个分数了
不要太注意shape不同, 只要注意分数就好
很明显的模型在检测 label1 的时候, 在图1的表现好很多 !我们发现到[0. 0. 0. 0.05691057] 这行分数很低接近于0,因为图1的label是[1, 1, 2, 1, 1]
在第三个值是label 2, 所以算出来的IOU几乎为0, 因为并不属于label1的
在来看到label2 的iou
1#这是label 2的第一张图检测与gt的ious结果
2 [[0.00107885]
3 [0. ]
4 [0. ]
5 [0.03430409]]
分数基本都趋近于0, 就表示模型在图1 完全没找到什么都没检测到
你可以比较一下det_result1_2的坐标和gt_bbox1的坐标就很清楚了, 坐标完全没重合的感觉
如此一来我们就有了label1 和 label2 所有检测到的框和ground truth的 IOU值了
得到了IOU在透过一开始给的iou_thr 阈值, 不就能筛选出谁是TP 谁是 FP了吗?
来, 咱们在复习一次 , 跟着我大声念!
检测大于阈值的叫做TP(TruePositive)
低于阈值的也就是错误的叫做FP (FalsePositive)
喝口水继续
我们将刚刚的ious 进行整理
1ious_max = ious.max(axis=1)
2ious_argmax = ious.argmax(axis=1)
输出会是下面这个样子, 是不是, 说shape先别在意的 !反正都会变这个样子
ious_max [0.9665272 0.7804878 0.05691057 0.6701031 0.6295463 ]
ious_argmax [0 1 3 2 3]
接下来就是透过阈值筛选, 过程代码比较多, 不全写出来
1if ious_max[i] >= iou_thr:
2 matched_gt = ious_argmax[i]
tpfp_default函数输出就会是像这样
tp: [[1. 1. 0. 1. 1.]]
fp: [[0. 0. 1. 0. 0.]]
是不是一目了然?也能够对应到分数?iou高说明检测正确并且归纳在TP 用1表示
而分数低的自然就是FP了 用0表示
拿到了TP FP 就离我们的recalls 和 precisions 不远了啊 !
好了 这只是上半场,Part2 明天继续更!
重磅!CVer-目标检测交流群成立啦
扫码添加CVer助手,可申请加入CVer-目标检测学术交流群,同时还可以加入目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测和模型剪枝&压缩等群。一定要备注:研究方向+地点+学校/公司+昵称(如目标检测+上海+上交+卡卡)

▲长按加群

▲长按关注我们
麻烦给我一个在看!


