YOLO,一种简易快捷的目标检测算法

本文由兔子老大为AI 研习社撰写的独家供稿。有偿供稿请联系邮箱 【konglingshuang@leiphone.com】。
YOLO全称You Only Look Once,是一个十分容易构造目标检测算法,出自于CVPR2016关于目标检测的方向的一篇优秀论文(https://arxiv.org/abs/1506.02640 ),本文会对YOLO的思路进行总结并给出关键代码的分析,在介绍YOLO前,不妨先看看其所在的领域的发展历程。
目标检测
相对于传统的分类问题,目标检测显然更符合现实需求,因为往往现实中不可能在某一个场景只有一个物体(业务需求也很少会只要求分辨这是什么),但也因此目标检测的需求变得更为复杂,不仅仅要求detector能够检验出是什么物体,还的确定这个物体在图片哪里。
总的来说,目标检测先是经历了最为简单而又暴力的历程,这个过程高度的符合人类的直觉。简单点来说,既然要我要识别出目标在哪里,那我就将图片划分成一个个一个个小图片扔进detector,但detecror认为某样物体在这个小区域 上了,OK,那我们就认为这个物体在这个小图片上了。而这个思路,正是比较早期的目标检测思路,比如R-CNN。
然后来的Fast R-CNN,Faster R-CNN虽有改进,比如不再是将图片一块块的传进CNN提取特征,而是整体放进CNN提取除 featuremap 然后再做进一步处理,但依旧是整体流程分为区域提取 和 目标分类 两部分(two-stage),这样做的一个特点是虽然精度是保证了,但速度上不去,于是以YOLO为主要代表的这种一步到位(one-stage)即 End To End 的目标算法应运而生了。
YOLO详解
细心的读者可能已经发现,是的,YOLO的名字You only look once正是自身特点的高度概括。
YOLO的核心思想在于将目标检测作为回归问题解决 ,YOLO首先将图片划分成SxS个区域,注意这个区域的概念不同于上文提及将图片划分成N个区域扔进detector这里的区域不同。上文提及的区域是真的将图片进行剪裁,或者说把图片的某个局部的像素扔进detector,而这里的划分区域,只的是逻辑上的划分。
为什么是逻辑上的划分呢?这体现再YOLO最后一层全连接层上,也就是YOLO针对每一幅图片做出的预测。
其预测的向量是SxSx(B*5+C)长度的向量。其中S是划分的格子数,一般S=7,B是每个格子预测的边框数 ,一般B=2,C是跟你实际问题相关的类别数,但要注意的是这里你应该背景当作一个类别考虑进去。
不难得出,这个预测向量包括:
SxSxC 个类别信息,表示每一个格子可能属于什么类别
SxSxB 个置信度,表示每一个格子的B个框的置信度,再YOLO进行预测后,一般只保留置信度为0.5以上的框。当然这个阈值也可以人工调整。
SxSxBx4 个位置信息,4个位置信息分别是xywh,其中xy为box的中心点。
说完YOLO的总体思路后,我们在看看YOLO的网络结构
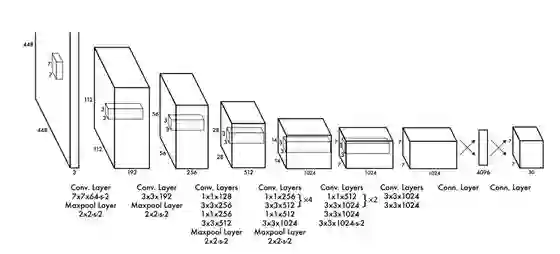
该网络结构包括 24 个卷积层,最后接 2 个全连接层。文章设计的网络借鉴 GoogleNet 的思想,在每个 1x1 的 归约层(Reduction layer,1x1的卷积 )之后再接一个 3∗3 的卷积层的结构替代 Inception结构。论文中还提到了 fast 版本的 Yolo,只有 9 个卷积层,其他则保持一致。
因为最后使用了全连接层,预测图片要和train的图片大小一致,而其他one-stage的算法,比如SSD,或者YOLO-V2则没有这个问题,但这个不在本文讨论范围内。
其实网络架构总体保持一致即可,个人不建议照抄全部参数,还是需要根据你的实际任务或计算资源进行魔改,所以接下来重点会讲述训练的过程和损失函数的构建,其中也会给出MXNET版本的代码进行解释。文末会给出全部代码的开源地址。
损失函数的定义

图片来源于网络
大题来说,损失函数分别由:
预测框位置的误差 (1)(2)
IOU误差(3)(4)
类别误差(5)
其中,每一个组成部分对整体的贡献度的误差是不同的,需要乘上一个权重进行调和。相对来说,目标检测的任务其实更在意位置误差,故位置误差的权重一般为5。在此,读者可能费解,为什么框的宽和高取的是根号,而非直接计算?
想要了解这个问题,我们不妨来看看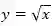
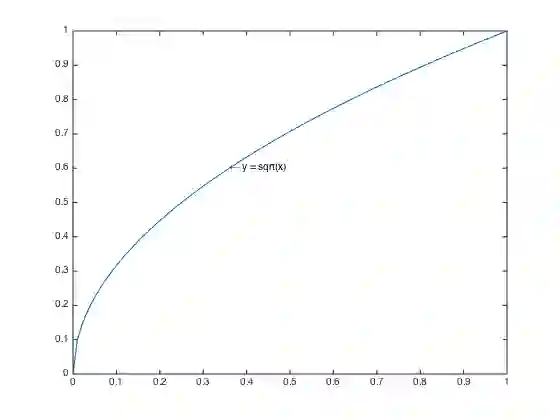
这里额外多说一句,如果有打数据挖掘比赛经验的同学,可能会比较清楚一种数据处理的手段,当某些时候,会对某一特征进行数据变换,比如
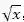
而在损失函数中应用这一方法,起到的作用则是使得小框产生的误差比大框的误差更为敏感,其目的是为了解决对小物体的检测问题。但事实上,这样的设定只能缓解却没有最终解决这个问题。
在说IOU误差,IOU的定义为实际描框和预测框之间的交集除以两者之间的并集。
听上去很复杂,实际我们既然能获得预测框坐标,只要通过简单的换算,该比值实际能转换成面积的计算。而同样的,这里也有一个问题,我们感兴趣的物体,对于整体图片来说,毕竟属于小数。换言之,就是在SxS个格子里面,预测出来的框大多是无效的框,这些无效框的误差积累是会对损失函数产生影响,换句话说,我们只希望有物体的预测框有多准,而不在乎没有物体的框预测得有多差。因此,我们也需要对这些无效框的在损失函数上得贡献乘上一个权重,进行调整。
也就是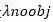
关于分类误差,论文虽然是采用mse来衡量,但是否采用交叉熵来衡量更合理呢?对于分类问题,采用mse和交叉熵来衡量,又会产生什么问题?这个问题留给读者思考。
代码实现
说完了损失函数,下面来讲述如何使用MXNET来实现YOLO,同理的,YOLO的网络结构较为简单,你可以采用任何的框架搭出,如果像我一样只是为了演示demo,对网络结构可以修改一下,采取网络拓扑上比较简单的模型。
同样的,目标检测常使用在ImageNet上预训练(pretrain)的模型 作为特征抽取器,同样,因为这里只是演示demo,同样也省略这一部分,只是重点讲损失函数的构造。
首先,虽然损失函数虽然是逻辑上分成三个部分,但我们不打算分开三个部分计算。
而是将整体式子拆分成 W x loss来计算,这样在代码上,实现起来要方便得多,以下时loss函数的计算过程:
def hybrid_forward(self, F, ypre, label):
label_pre, preds_pre, location_pre =self._split_y(ypre)
label_real, preds_real, location_real=self._split_y(label)
batch_size =len(label_real)
loss =nd.square(ypre - label)
class_weight=nd.ones(
shape =(batch_size, self.s*self.s*self.c))*self._scale_class_prob
location_weight = nd.ones(shape = (batch_size, self.s *self.s *self.b, 4))
confs =self._calculate_preds_loss(preds_pre,preds_real, location_pre, location_real)
preds_weight =self._scale_noobject_conf * (1. - confs) +self._scale_object_conf * confs
location_weight = (nd.expand_dims(preds_weight, axis=2) * location_weight) *self._scale_coordinate
location_weight = nd.reshape(location_weight, (-1, self.s *self.s *self.b *4))
W =nd.concat(*[class_weight, preds_weight, location_weight], dim=1)
total_loss = nd.sum(loss * W, 1)
return total_loss可能会有童鞋好奇,为什么坐标误差是用预测值和label直接mse算呢,w和h不是应该要开根号吗?是的,但我们为了数值稳定,在人工构建label时就已经将wh以开根后的形式存储好了,这是因为,神经网络的输出在初始时,正负值时随机的,尽管在数学上的结果是虚数i,但在DL相关的框架,该操作会直接造成nan,造成损失函数无法优化,而且相应代码的书写更为复杂。而采取直接以取根号后的形式我们只要在获取输出时,再将wh求一个平方即可。
另外要说的一点就是IOU误差,虽然很多文章都将这一点直接成为IOU误差,实际上计算时时IOU误差和置信度的结合。
def_iou(self, box, box_label):
wh = box[:, :, :, 2:4]
wh = nd.power(wh, 2)
center = box[:, :, :, 0:1]
predict_areas = wh[:, :, :, 0] * wh[:, :, :, 1]
predict_bottom_right = center +0.5* wh
predict_top_left =center -0.5* wh
wh = box_label[:, :, :, 2:4]
wh = nd.power(wh, 2)
center = box_label[:, :, :, 0:1]
label_areas = wh[:, :, :, 0] * wh[:, :, :, 1]
label_bottom_right = center +0.5* wh
label_top_left = center -0.5* wh
temp = nd.concat(*[predict_top_left[:, :, :, 0:1], label_top_left[:, :, :, 0:1]], dim=3)
temp_max1 = nd.max(temp, axis=3)
temp_max1 = nd.expand_dims(temp_max1, axis=3)
temp = nd.concat(*[predict_top_left[:, :, :, 1:], label_top_left[:, :, :, 1:]], dim=3)
temp_max2 = nd.max(temp, axis=3)
temp_max2 = nd.expand_dims(temp_max2, axis=3)
intersect_top_left = nd.concat(*[temp_max1, temp_max2], dim=3)
temp = nd.concat(*[predict_bottom_right[:, :, :, 0:1], label_bottom_right[:, :, :, 0:1]], dim=3)
temp_min1 = nd.min(temp, axis=3)
temp_min1 = nd.expand_dims(temp_min1, axis=3)
temp = nd.concat(*[predict_bottom_right[:, :, :, 1:], label_bottom_right[:, :, :, 1:]], dim=3)
temp_min2 = nd.min(temp, axis=3)
temp_min2 = nd.expand_dims(temp_min2, axis=3)
intersect_bottom_right = nd.concat(*[temp_min1, temp_min2], dim=3)
intersect_wh = intersect_bottom_right - intersect_top_left
intersect_wh = nd.relu(intersect_wh) # 把0过滤了
intersect = intersect_wh[:, :, :, 0] * intersect_wh[:, :, :, 1]
ious = intersect / (predict_areas + label_areas - intersect)
max_iou = nd.expand_dims(nd.max(ious,2),axis=2)
best_ = nd.equal(max_iou,ious)
best_boat = nd.ones(shape = ious.shape)
for batch in range(len(best_)):
best_box[batch] = best_[batch]
return nd.reshape(best_box, shape=(-1, self.s*self.s*self.b))
def_calculate_preds_loss(self, ypre, label, local_pre, local_label):
ious =self._iou(local_pre, local_label)
conf = label * ious
returnconf置信度在label的表现形式时,这个地方有目标物体则为1,没有则是0,这样用mse优化后,输出值会在0~1附近,正好可以代表某个框是否框中物体的置信度。
但为什么不直接 对置信度用mse呢,这同样是一个权重的调节的问题,但这里不能说我们就不care那些没有物体的框的值了,因为这里的值是置信度,如果我们任由其发展,万一没有物体的框的置信度比有框中物体的置信度还要高,那我们使用阈值过滤时,就可能出现问题了。只能说我们希望loss中更重视有框中物体的框的误差。
这里补充另外一个知识点最大值抑制 ,简单点来说,既然每个格子会生成B个框(一般B>1)这样就有可能同时两个框都框中了物体,那么到底采用那个框作为预测结果呢?答案是采用IOU值高的那个框,而IOU值小的,就会不被重视而受到抑制。
ious = intersect / (predict_areas + label_areas -intersect)
max_iou = nd.expand_dims(nd.max(ious,2),axis=2)
best_ = nd.equal(max_iou,ious)
best_boat =nd.ones(shape = ious.shape)
for batch in range(len(best_)):
best_box[batch] = best_[batch]
return nd.reshape(best_box, shape=(-1, self.s*self.s*self.b))在求出IOU后,我们求出每一个格子的框中的最大值,再使用equal操作,使得最大值为1,其余值为0再参与后面的运算即可。
代码地址
DEMO-github(https://github.com/MashiMaroLjc/YOLO )
代码使用的是李沐公开课的皮卡丘数据集,用MXNET的Gluon接口实现,Enjoyit!
运行效果:

上述文章若有不正确的地方,敬请指正。

上海交通大学博士讲师团队
从算法到实战应用
涵盖 CV 领域主要知识点
手把手项目演示
全程提供代码
深度剖析 CV 研究体系
轻松实战深度学习应用领域!
▼▼▼

新人福利
关注 AI 研习社(okweiwu),回复 1 领取
【超过 1000G 神经网络 / AI / 大数据,教程,论文】
YOLO9000 好棒好快好强壮 阅读笔记
▼▼▼


