多标签图片分类指标mAP

多标签图片分类指标mAP:mean AVERAGE PRECISION。这个概念解释前先说一下AP:average precision。
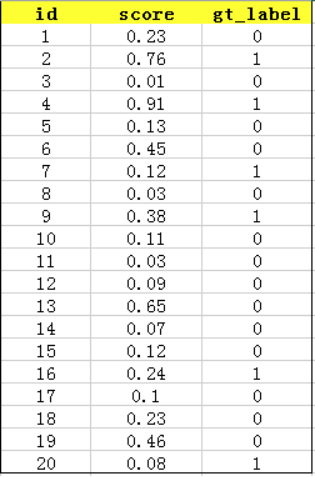
每一个测试图片都会针对每一个类别输出一个概率值。假设我们测试了20张图片,我们将这20张图片中针对某一类(例如car)的prob值取出保存在一个文件中(xxx_test.txt),形成如下形式:(gt-label:ground truth label表示实际标签值)
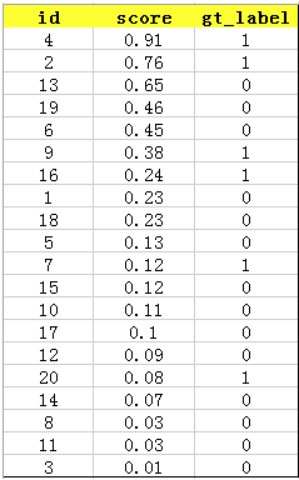
排序后得到:
然后,我们取top-N的结果作为识别该图片为该类(例如car)的结果,我们取top-5为例:
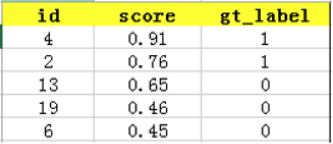
此时,true positives就是4、2,false positives是13、19、6,false negative是9、16、7、20,true negative是1,18,5,15,10,17,12,14,8,11,3。相应precision=2/5,recall=2/6。
实际中,我们通常不能使用top-5来衡量,而是需要知道top-1到top-N的(N为所有测试样本个数,此处为20)相应precision和recall值。最新的AP的计算方法是:假设这N个样本中有M个正例,那么我们会得到M个recall值(1/M, 2/M, ..., M/M),对于每个recall值r,我们可以计算出对应(r' > r)的最大precision,然后对这M个precision值取平均即得到最后的AP值。
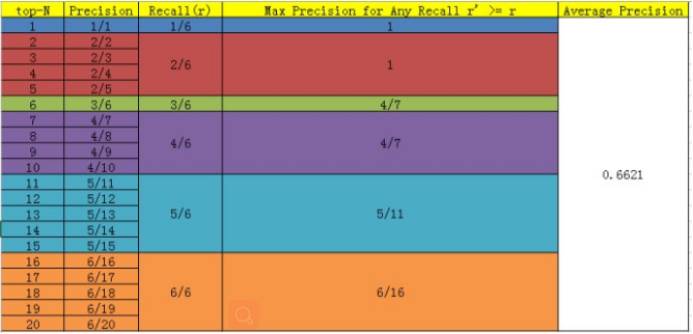
显然随着我们选定的样本越来也多,recall一定会越来越高,而precision会呈单调递减趋势。把recall当成横坐标,precision当成纵坐标,即可得到常用的precision-recall曲线。
AP衡量的是学出来的模型在每个类别上的好坏,mAP衡量的是学出的模型在所有类别上的好坏,得到AP后mAP的计算就变得很简单了,就是取所有AP的平均值。
参考连接:http://blog.sina.com.cn/s/blog_9db078090102whzw.html
往期内容:

课程咨询|微信:julyedukefu
七月热线:010-82712840


