李飞飞团队CVPR论文:让AI识别语义空间关系(附论文、实现代码)

本文经AI新媒体量子位(公众号ID:qbitai )授权转载,转载请联系出处。
本文共1000字,建议阅读5分钟。
斯坦福视觉实验室即将在CVPR 2018上发表的一篇关于研究“指称关系”任务的论文。

“”保安,保安!抓住那个砸玻璃的人!"
对于人类保安来说,理解这个指令是自然而然毫无难度的事。但机器就不一样了:它们能从画面中认出人人人人人,但究竟哪一个才是“砸玻璃的人”呢?
李飞飞领导的斯坦福视觉实验室即将在CVPR 2018上发表的一篇论文 Referring Relationships,研究的就是这个问题。
这篇论文提出的“指称关系”任务,是给计算机一个“主-谓-宾”结构的“关系”描述和一张图,让它能将主体(主语对应的那个东西)和客体(宾语对应的那个东西)定位出来。
比如说:
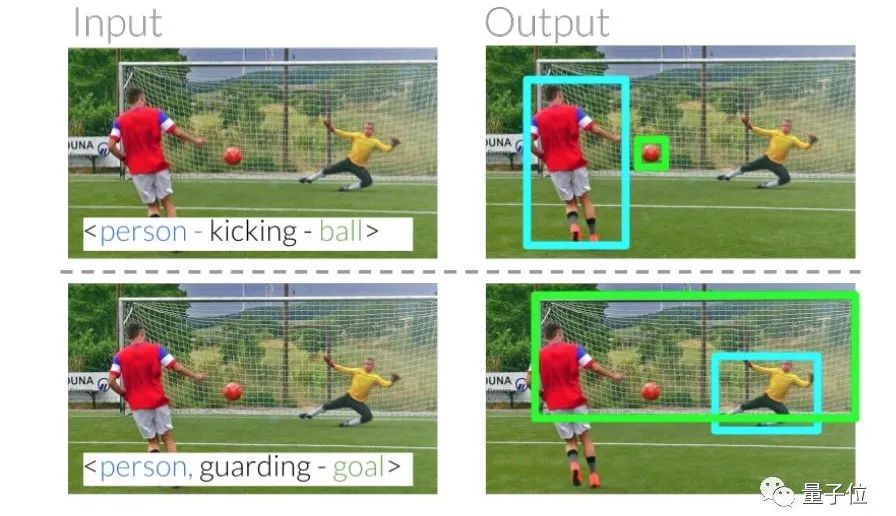
他们要让计算机在这样一个场景中,根据“person - kicking - ball(人在踢球)”这个描述,定位出“踢球的人”和“球”,根据“person - guarding - goal(人在守门)”这个描述,定位出“守门的人”和“球门”。
要正确圈出主体和客体,计算机内心需要经历这样一个过程:
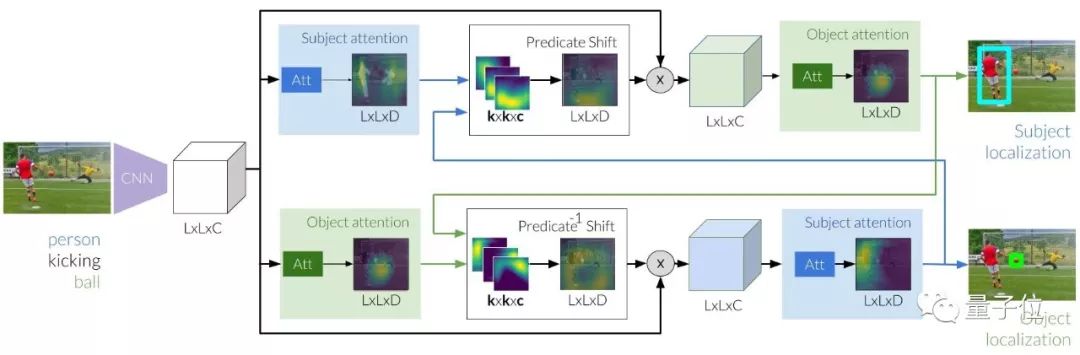
如上图所示,整个过程的第一步是用CNN提取图像特征,供算法用来对主体和客体分别进行初步定位。
不过,不是所有的主体和客体都那么容易找出来,比如说人很好识别,但球门就不一定了。几位研究员所用的方法,是先找到主客体之间的关系,这样只要定位出其中一个,就很容易找到另一个。
在这个过程中需要对谓语建模,也就是搞清楚对主客体关系的描述。他们把谓语看作主体和客体之间的注意力移动,借此找出主客体之间的关系。
从上面的流程图我们也可以看出,根据主体和构建出来的关系描述,可以推断出来注意力转移到的区域,找到客体应该在的位置,并据此修改图像特征。也可以根据注意力转移,从客体推断出主体位置。这个过程,称为predicate shift。
运用predicate shift过程在主体和客体之间反复传递消息,最终就能将这两个实体定位出来。
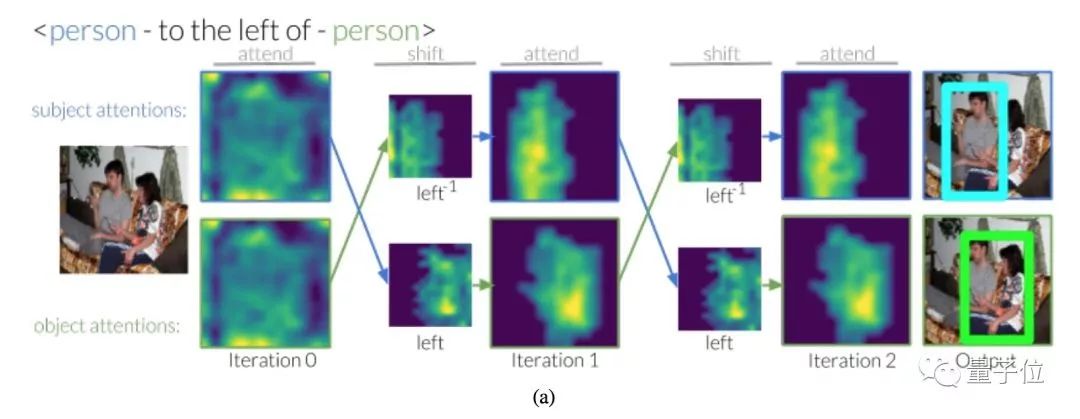
“某人在另一个某人的左边”,这种描述中的两个人,也可以用这种方法定位出来。
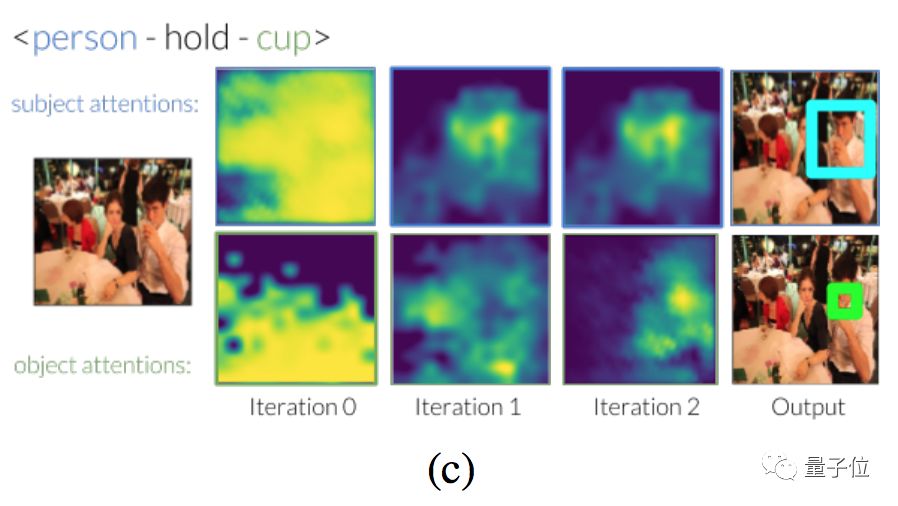
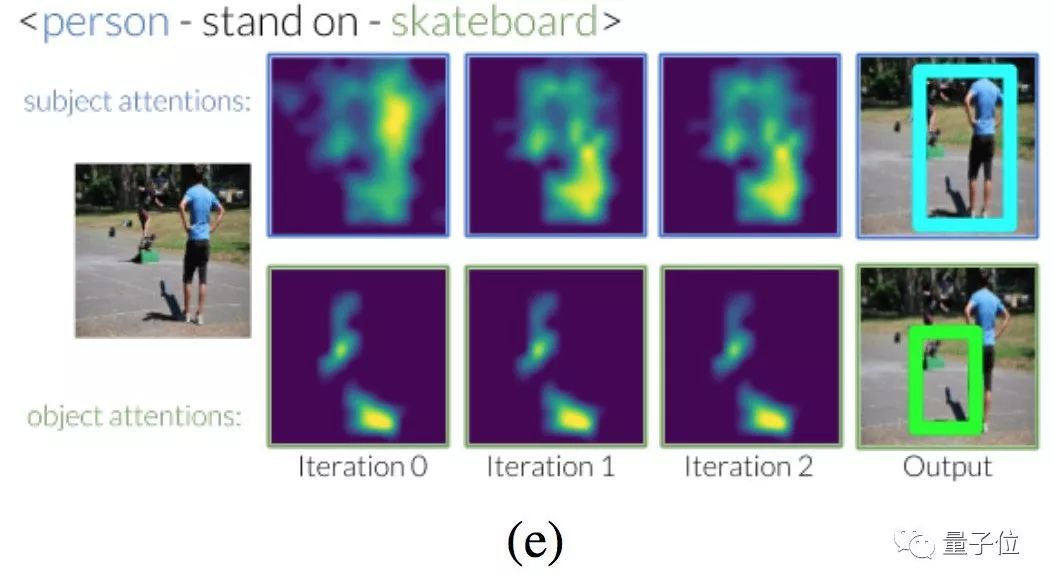
“拿着杯子的人”、“站在滑板上的人”等等也都没问题。
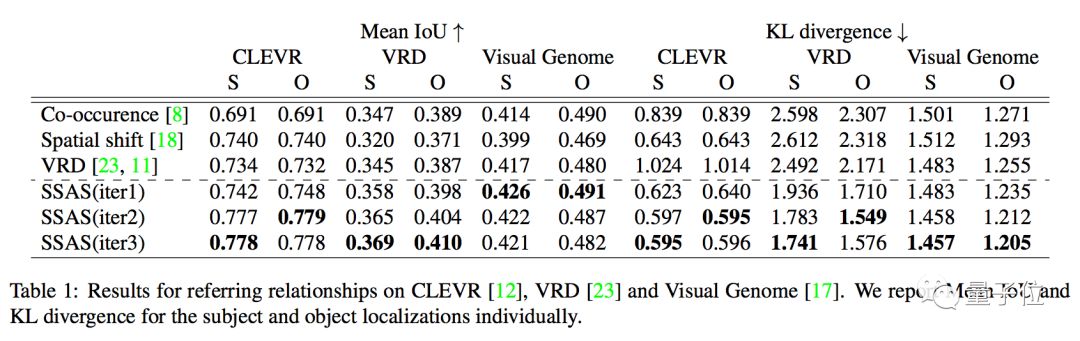
李飞飞团队在CLEVR、VRD和Visual Genome三个视觉关系数据集上评估了自己的模型,成绩如下:
想要了解更多细节,请进入亲自读论文撸代码环节~
论文链接:
https://arxiv.org/abs/1803.10362
Keras+TensorFlow实现:
https://github.com/StanfordVL/ReferringRelationships
根据斯坦福视觉实验室主页介绍,他们在CVPR 2018上总共发表了三篇论文,除了今天介绍的这一篇之外,还有:
What Makes a Video a Video: Analyzing Temporal Information in Video Understanding Models and Datasets
De-An Huang, Vignesh Ramanathan, Dhruv Mahajan, Lorenzo Torresani, Manohar Paluri, Li Fei-Fei, and Juan Carlos Niebles
CVPR 2018 (spotlight)
Finding “It”: Weakly-Supervised Reference-Aware Visual Grounding in Instructional Video
De-An Huang, Shyamal Buch, Lucio Dery, Animesh Garg, Li Fei-Fei, and Juan Carlos Niebles
CVPR 2018 (oral)
这两篇论文的PDF版还未放出,我们会持续关注~






