CVPR 2018 中国论文分享会 之「人物重识别及追踪」

文 | camel
来自雷锋网(leiphone-sz)的报道
雷锋网(公众号:雷锋网) AI 科技评论按:本文为 2018 年 5 月 11 日在微软亚洲研究院进行的 CVPR 2018 中国论文宣讲研讨会中第三个 Session——「Person Re-Identification and Tracking」环节的四场论文报告。
图森未来王乃岩博士做了第一个报告。在行人重识别中,不同的图片对行人的识别率不同,那么到底需要几帧图片才能够准确地判别一个人的身份呢?王乃岩博士针对这个问题,提出了一种自适应强化学习模型,也即自动学出做出准确判断所需要的帧,其结果显示只需要视频流的 3%-6% 即可获得最好的结果。而事实上这可以作为一种通用的方法用在别的研究任务中。
第二个报告由来自北京大学特聘研究员张史梁介绍他们在行人重识别研究中对「数据对性能的影响」的思考。他们发现,尽管在特定数据集中许多方法能够达到超越人类的水平,但是在实际应用中却表现极差。原因是,目前公开的数据集在数量、场景、时间段、光照等维度都过于单一;且由于不同数据集收集时的标准不同,很难实现跨数据集的研究和应用。基于这样的思考,他们花费很大精力构建了目前看来最大的多场景、多时间段、多光照强度的数据集 MSMT17;此外,他们还涉及了 PTGAN 网络,用于将不同数据集的风格进行融合,以达到相互利用的目的。
随后是由港中文-商汤联合实验室的李鸿升教授介绍了他们在行人重识别研究中的新视角。李鸿升教授在今年的 CVPR 中共有 7 篇入选论文,这里他只介绍了其中两篇。第一篇为 oral 论文,他们考虑到图片之间具有组相似性,而现有的方法大多忽视了这种相似性;基于这种思考,他们提出了用组相似性的约束的全局 loss 函数,取代了之前只是基于局部的 loss 函数。第二篇论文中他们发现图片背景对模型重识别行人有很大的影响。
最后由来自商汤科技的武伟博士介绍了他们在目标追踪方面的工作。基于实际安防监控工作的需要,他们设计了一个利用孪生(Siamese)网络和区域候选网络(Region Proposal Network)构建的高速且高性能的单目标跟踪算法。该算法在 VOT 2016 和 VOT 2017 数据集上都取得了 state-of-art 的结果。
雷锋网注:
[1] CVPR 2018 中国论文宣讲研讨会由微软亚洲研究院、清华大学媒体与网络技术教育部-微软重点实验室、商汤科技、中国计算机学会计算机视觉专委会、中国图象图形学会视觉大数据专委会合作举办,数十位 CVPR 2018 收录论文的作者在此论坛中分享其最新研究和技术观点。研讨会共包含了 6 个 session(共 22 个报告),1 个论坛,以及 20 多个 posters,雷锋网 AI 科技评论将为您详细报道。
[2] CVPR 2018 将于 6 月 18 - 22 日在美国盐湖城召开。据 CVPR 官网显示,今年大会有超过 3300 篇论文投稿,其中录取 979 篇;相比去年 783 篇论文,今年增长了近 25%。
更多报道请参看:
Session 1:GAN and Synthesis
Session 2: Deep Learning
Session 3: Person Re-Identification and Tracking
Session 4: Vision and Language
Session 5: Segmentation, Detection
Session 6: Human, Face and 3D Shape
1
将增强学习引入行人重识别
论文:Multi-shot pedestrian re-identification via sequential decision making
报告人:王乃岩,图森未来,首席科学家
论文下载地址:https://arxiv.org/abs/1712.07257
所谓行人重识别任务,即将来自多个摄像头的不同轨迹中的行人(例如多张图片或者视频图片)进行身份识别。这在安全领域中的视频分析、视频监控具有广泛的应用基础。在实际中多张图片能够提供丰富的信息,但是同时也带来了大量的冗余,甚至潜在的噪声。解决这一问题的关键在于如何将多张图片中的特性进行聚合。
1、背景
目前实现特性聚合的方法主要有两类。一类是 feature pooling,也即将每一帧图片的特性提取出来后,在对所有帧的特性进行 pooling,从而提取出 frame level 的特性。另一类方法是时序模型,也即假设图片之间存在时序,然后使用光流/LSTM 的方法对 frame level 特性进行融合。
王乃岩在这篇被 CVPR 2018 接收的文章中考虑到,行人重识别应当对不好的检测(例如重影)或遮挡具有更高的鲁棒性,同时对不同图片中行人的识别有一定的弹性。

如上图所示,左侧两张图片可以很容易检测出是否是同一个人,因此期望设计出的模型只是用一对图片做判别即可;而另一方面,右侧的图片,由于遮挡、模糊的原因,一对图片很难判断是否是同一个人,因此希望模型能够自动地选择适量的图片对进行行人身份判断。
2、方法
基于上面的考虑,王乃岩团队提出了一种称为「自适应强化学习」(Adaptive Reinforcement Learning)的模型,如下图所示:
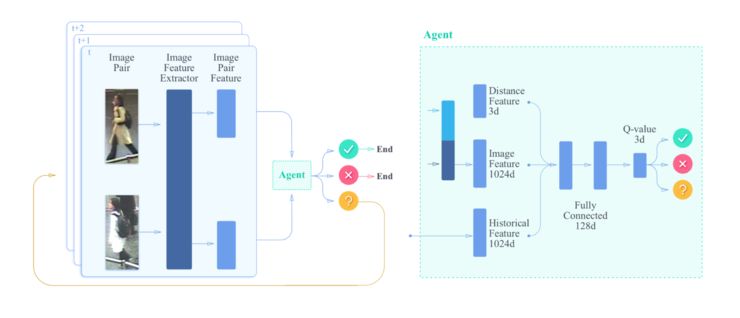
这里有几个关键点需要特别指出:
(1)Actions。图片对生成的 feature 送入 agent 后,agent 将作出三种判断:same,different 和 unsure。当判断结果为 unsure 时,就会返回到开头重新进行判断。
(2)Reward。如果目标图片与 ground truth 图片匹配,那么奖励为+1;如果不匹配,或者尽管还不确定但所有的图片都已经对比完了,那么奖励为-1;否则,当图片对还没有对比完且也没有确定是否匹配,那么奖励为 r_p。显然这里 r_p 大小的设定影响着奖励的结果,如果设置为负值,那么它会因为请求更多图像对而受到惩罚;而当设置为正值,它就会被鼓励收集更多的图像对,直至对比完所有的图像,此时 r_p 会被强行设置为-1。
(3)输入 agent 的 feature,除了学习到的当前图片的 image features 外,还利用了历史 feature(也即前面的判断结果,进行加权平均)和手工设计的距离 3D feature。
(4)学习算法为比较经典的 DQN,学习得到 Q-Value 以判断两张图片中的人是否是同一个人。
3、结果
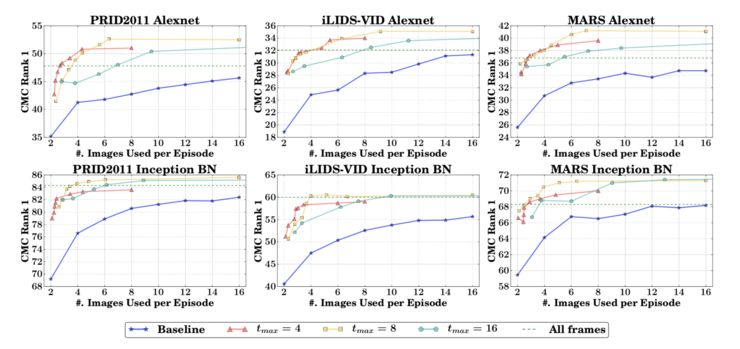
这张对比结果是,当设置每个 episode 中图片对的最大数量(例如 4 对)时,ARL 方法相比 baseline 的结果。可以看出即使使用少量的图片对也能在 CMC Rank 中取得极好的分数。
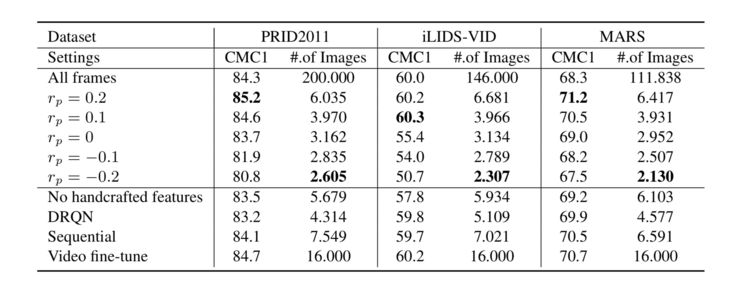
这张图片可以从定量的角度来看该模型的优点。当设置视频流包含 200 张图片时,ARL 方法只用 3 - 6 张图片即可达到近似于使用全部图片的效果。
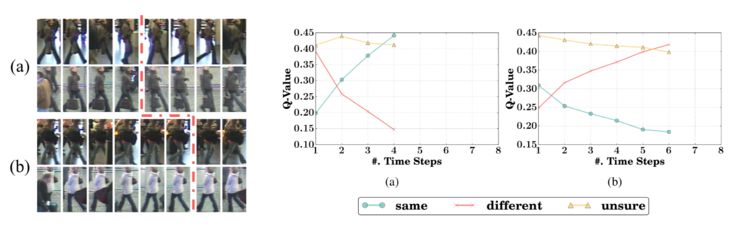
最后展示一下,训练过程中 same、different、unsure 三个 state 分数的变化。左侧的图显示了对不同的图片判断结果所需要的图片对数量也不同,模型能够自适应选择。右侧是相应的分数变化。
4、总结
这篇文章算是首次尝试将增强学习方法引入到 multi-shot 重识别问题当中,其结果显示可能只需要所有图片(例如视频流)中的 3%-6% 的图片即可获得最好的结果。可能这里更为关键的是它可以使用到 single-shot 重识别问题中。据王乃岩表示,这种方法除了能够用于行人的重识别外,或许也可以作为不确定估计的一种通用方法。期待他们接下来的研究成果。
2
最大、多场景、多时间段行人数据集
论文:Person Transfer GAN to Bridge Domain Gap for Person Re-Identification
报告人:张史梁,北京大学
论文下载地址:https://arxiv.org/abs/1711.08565
这篇文章可能提供了最大的多场景、多时间段的行人数据集了。
从 2005 年行人重识别任务首次提出后,经过 2014 年深度学习被引入该领域,行人重识别的研究得到大量的研究(例如 CVPR 上行人重识别的文章从 2014 年的 3 篇剧增到今年的 32 篇),在这些研究中各种模型所表现出的性能也逐步提升,在今年的一些数据集(例如 CUHK03、Market501)上一些方法的表现甚至超越了人类。
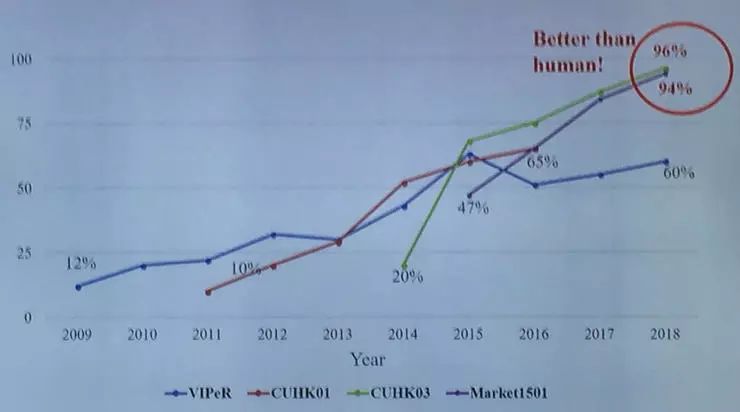
1、行人重识别真的超越人类了吗?
一个让人不禁产生的问题是:我们真的已经解决行人重识别的问题了吗?
事实可能是并没有。对比大多数实验中所使用的数据集和真实世界的数据集,就可以发现仍然存在着很大的差别。例如下表中的五个已有的公开数据集 Duke、Market、CUHK03、CUHK01、VIPeR 与真实世界数据集的对比:
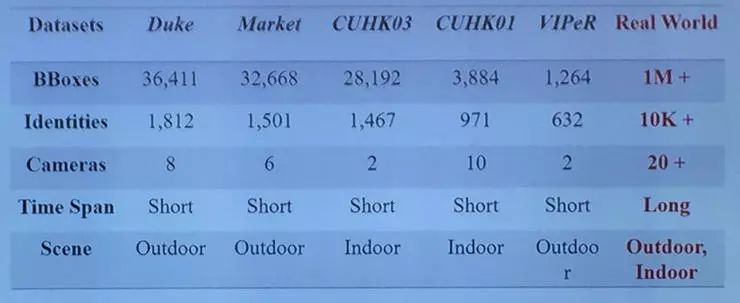
可以看出这些公开数据集有以下几个问题:数据量小、场景单一(indoor 或者 outdoor)、相机数量少、时间短、光线条件单一等。
此外,在实验中大多数情况下,训练数据和测试数据的数量都接近于 1 : 1。但是在现实世界的数据中,训练数据往往只占全部数据中很小的一部分,因此在实验中表现良好的模型放到真实世界中可能并不能获得很好的效果。
2、如何进一步促进?
有了以上的考虑,怎么才能够进一步促进行人重识别的研究,以便能够在现实生活中加以应用呢?
第一个想法就是:我们需要有更加真实的数据集。这个数据集的采集应该更加接近真实世界,也即有更多的行人、更多的相机、更多的 bboxes,同时也应当有复杂的场景(既有室内也有室外场景),更加重要的是要还要有不同时段和不同光照下的数据。

解决训练集和测试集严重不均衡的问题,张史梁等人认为一个可行的思路就是重用已有的标注数据。例如在 PRID 中训练集较少,那么可以利用 CUHK03 的数据集进行训练,然后在 PRID 中进行测试。但是这种方法并不像想象的这么容易,例如上面的例子,Rank-1 精度只有 2%。思考其背后的原因,可能是因为在这两个数据集中有不同的光照、背景、相机参数等。
基于这两点考虑,张史梁等人做了两项工作,首先是构建了一个大型的多场景多时段的数据集 MSMT17;其次构建了一个 Person Transfer GAN,用于将不同的数据集进行融合,以便在同一个任务中使用。
3、数据集MSMT17
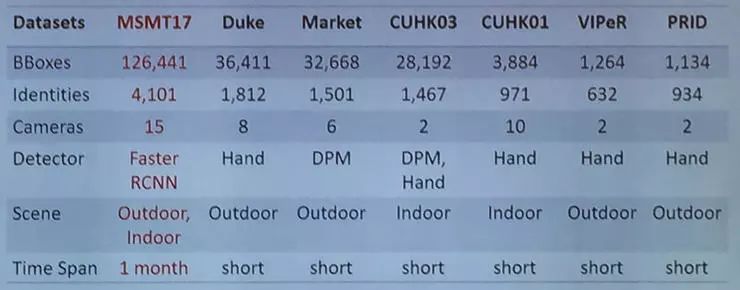
从上图中可以看出 MSMT17 的相比于其他数据集的一些优势。构建这个数据集共使用了 15 个相机,其中 12 个为 outdoor,3 个为 indoor;总共收集了 180 个小时的数据,每个月选择天气环境不同的 4 天,每天早、中、晚分别 3 个小时。他们选择 Faster RCNN 对这些行人进行 bounding box detection,这个标注过程花了两个月的时间,一共有 126441 个 body boxes。为了模拟真实世界中的环境,他们选择了 4101 个对象,其中 1041 个人用作训练,3060 个人用作测试。该数据集目前已经公开,可以说是该研究领域最大的数据集。
感受一下 MSMT17 数据集中的一些案例:

这里有光照的变化、场景和背景的变化、多样的姿态以及遮挡物等多种复杂条件。
4、PTGAN
这个 GAN 网络的目标就是将一个数据集 A 上的风格(包括背景、光照、照相机参数等)转化为另一个数据集 B 的风格,转换完之后则可以使用数据集 A' 作为数据集 B 的训练集。这里要保证两个方面:第一,变换后的风格符合数据集 B 的风格;第二,要保证变换前后人的身份信息不变。
张史梁等人提出的 person transfor GAN(PTGAN)如下图所示:
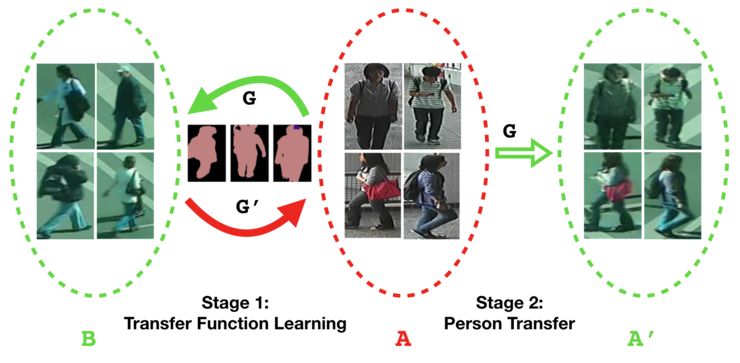
PTGAN 的训练过程主要由两个 Loss 来约束。
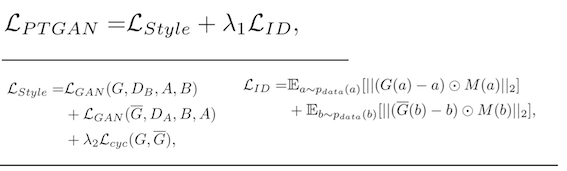
第一个是 Style transfer,即 A 经过 transfer 后风格尽可能和 B 相似,这是一个 unpaired image-to-image translation 任务,因此它就直接采用了 Cycle-GAN 的 loss 函数。另外一个就是 ID loss,保持身份尽可能地不发生变化,这里采用了 PSPNet 的 loss 函数。下图是三种 GAN 模型作用在输入图片上的结果对比:

下面变换前后的对比图之一,从 CUHK03 到 PRID-cam2 的变换:

用变换后的数据训练训练 GoogLeNet,然后在 PRID 数据集上进行测试,结果如下表:
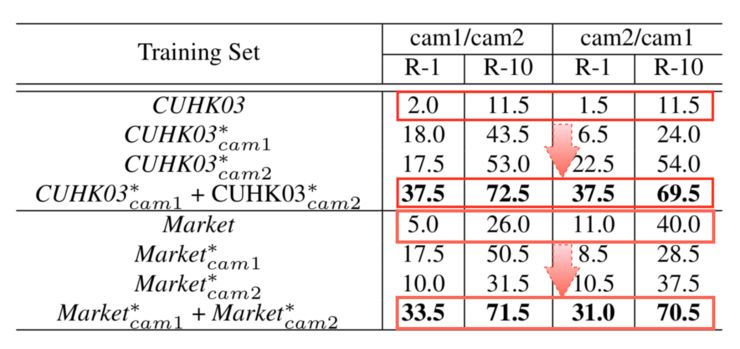
可以看到经过变换后的表现得到了大幅度的提升,例如 CUHK03 - PRID cam1 实验中,Rank-1 分数从原来的 2.0% 一下子提升到了 37.5%。
5、总结
能够适用于真实环境中的行人重识别模型才是真正的好模型,为了实现这点,张史梁等人提出了两种方法。一方面他们构建了一个目前来讲最大的近似真实世界的数据集 MSMT17;另一方面他们希望能够通过数据风格迁移在不同的数据集之间搭建一个桥梁,提出了 PTGAN 模型。
相关代码和数据:https://github.com/JoinWei-PKU
3
行人重识别中的背景影响到底有多大?
报告题目:Towards More Robust Person Re-identification with Group Consistency and Background-bias Elimination
报告人:李鸿升,港中文-商汤联合实验室
论文:
1. Group Consistent Similarity Learning via Deep CRFs for Person Re-Identification (oral)
2. Eliminating Background-bias for Robust Person Re-identification (Poster)
李鸿升教授所在团队在今年的 CVPR 上共有 7 篇行人重识别的论文被录用,其中 1 篇 oral,6 篇 poster。在这次分享会上他着重介绍了上述两篇内容。
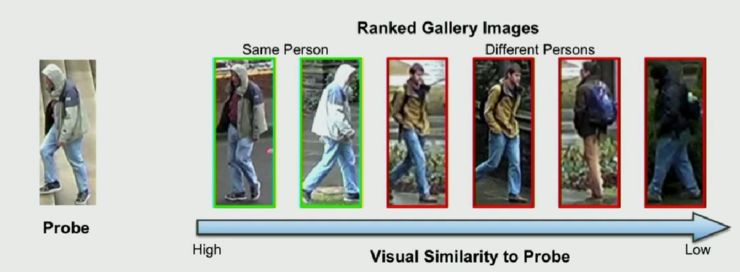
所谓行人重识别,按照李鸿升教授的说法,即给定一个检测图片,依据相似性对图片集中的所有行人图片进行排序。这其中的关键问题是,如何学习行人图片之间的视觉相似性。
1、基于组一致性约束条件的行人再识别
现有方法在通过深度神经网络学习视觉相似性时,一个局限性问题是在其 loss 函数中只用了局部约束。例如下图所示的 pairwise loss、triplet loss 或者 quardruplet loss:
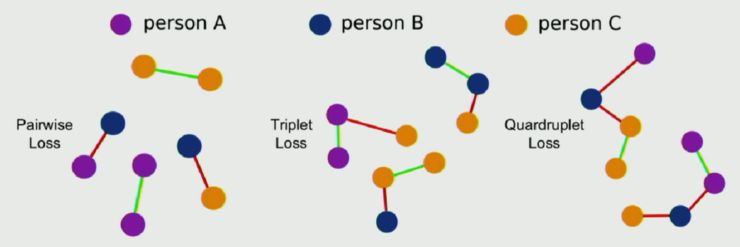
这种局部约束的 loss 函数不能描述图像之间的相似性。基于这样的思考,李鸿升等人认为应当构建一种基于组别相似性的新的 loss 函数,这种函数不仅能够描述局部相似性,还能够描述图片之间的相似性。
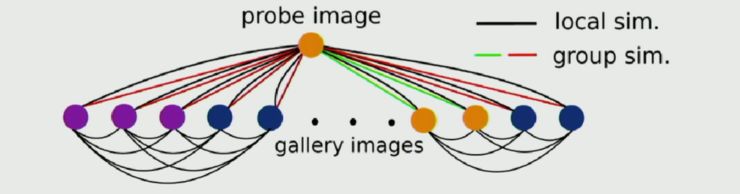
如上图所示,局部相似性仅仅考虑两幅图之间的相似性,而全局相似性则考虑 gallery images 中群组之间的相似性(probe image 也可以视为一个 group)。其方法的框架如下图所示:
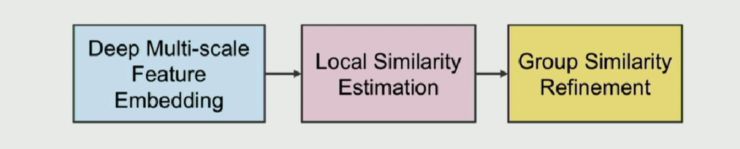
共分为三步:先进性深度多尺度 feature embedding(使用了 ResNet-50 作为主体网络),然后对图片进行一个局部的相似性估计(得到两张图片 I_m,I_n 的局部预估计相似性为 t_mn),最后一步为组相似性增强。
他们假设:给定一个图片 I_p,如果它与图片集 I_i 相似,而图片集 I_i 与图片集 I_j 相似,那么 I_p 也与 I_j 相似;否则如果 I_p 与图片集 I_i 不相似,而图片集 I_i 与图片集 I_j 相似,那么 I_p 与 I_j 不相似。而组相似性取决于整个图片组。
如果记 I_p 和 I_i 之间的组相似性为 y_pi。那么基于组相似性的 CRF 模型即为:

这里组相似性应当尽可能地接近于通过 CNN 网络估计出的局部相似性,因此有:
(unary term)

(pairwise term)

他们的实验结果如下:
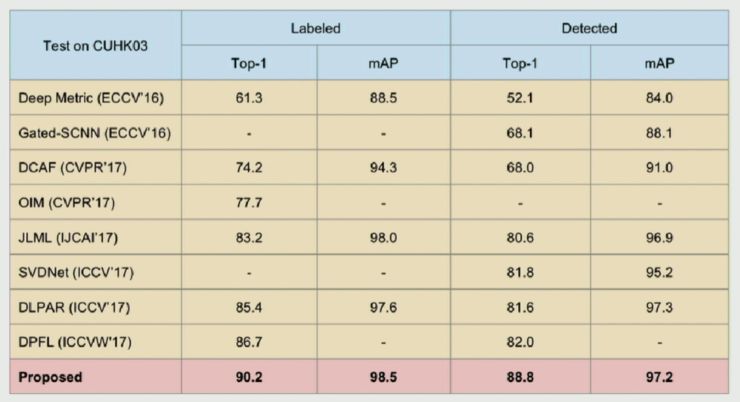
可以看出基于组相似性的重识别效果相比之前的 state-of-art 工作有显著地提升。
2、消除背景偏差
已有行人重识别方法中,大家都是用整张图片作为一个独立的数据样本去训练和检测,但是他们忽略了一个问题,即:行人和背景是不同的对象,在识别行人中,图片背景会带来偏差。如下图所示:
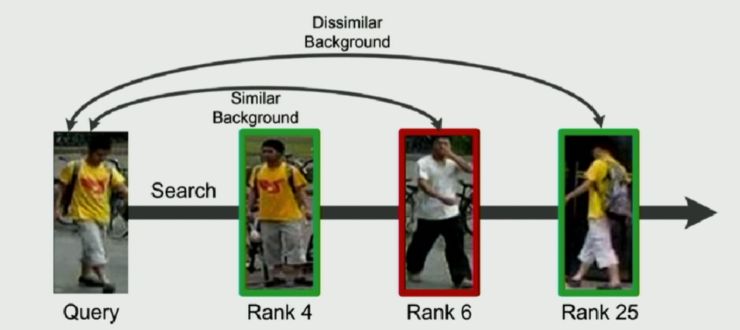
与 query 图片有相似背景但不同行人的图片排在 rank 6,而同一行人不同背景的图片却排在 rank 25。那么在行人重识别中,背景到底会带来多大的偏差呢?李鸿升等人通过在 CUHK03 和 Market-1501 数据集上使用 human parsing mask 的方法获得了 3 类数据集:mean background、random background 和 background only,如下图所示:

他们用原始数据集进行训练后,在 mean background、random background 进行测试:
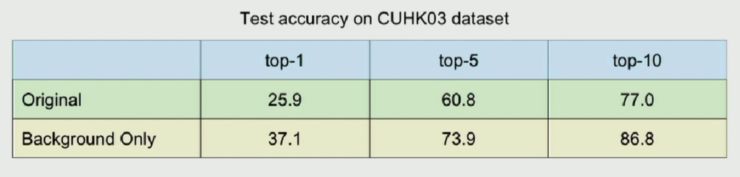
发现去除背景或者(尤其是)随机换背景后,性能出现大幅度的下降。而另一方面他们尝试只用背景图去训练,然后用原图和背景图做测试:
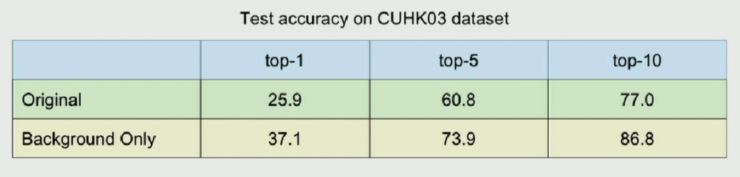
发现前者的表现并不差。这说明在之前深度学习模型中背景起到了相当大的影响,也同时给行人重识别带来了偏差。
基于这种发现,他们构建了一个 Person-region Guided Pooling Network。
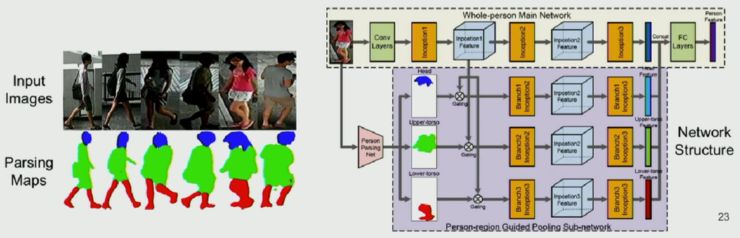
首先他们通过 huaman parsing 方法获得 4 类人体 parsing map(整体、头、躯干、腿),然后用这些 parsing map 从不同的人体区域做特征池化。他们分别对有无背景以及不同比例、on-off line 做了实验对比:
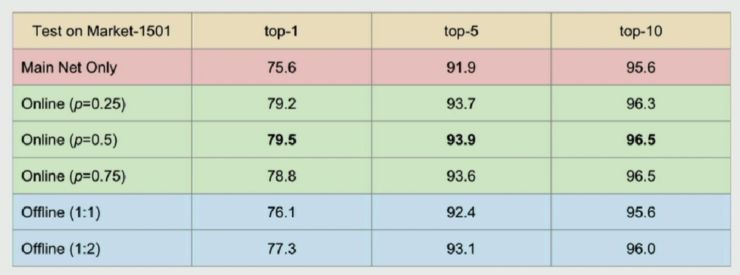
他们发现通过 online 且随机替换掉 50% 的原图的背景能够得到最好(限于对比实验)的结果。
同时他们也将这种方法与其他 state-of-art 方法进行对比:
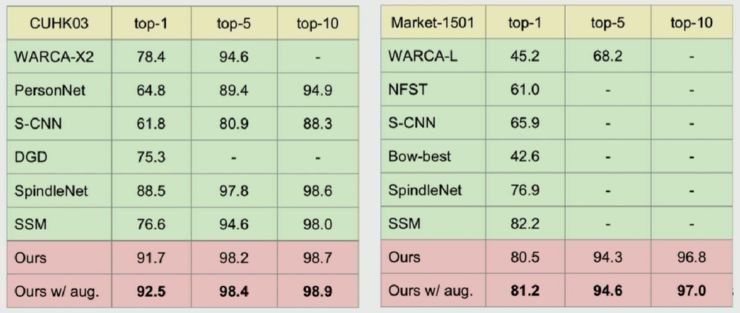
发现在不同数据集上这种方法的表现有显著的提升。
论文:High Performance Object Tracking with Siamese-network
报告人:武伟,商汤科技
论文下载地址:暂无
目标追踪不同于目标检测,首先对于追踪的目标没有一个预定义的分类;其次在整个视频帧当中只有第一帧带有标注;此外,也没有可用于训练的数据存在。
据武伟介绍,他在商汤主要负责安防监控方面的研发工作,之所以考虑做目标追踪,是因为业务需要。现有的单目标跟踪算法很难兼顾到性能和速度,只能再某一个指标上占优。但是在实际应用中则不得不考虑,在不影响性能的同时如何进一步提高速度。
基于这种业务需求,武伟等人提出了一种端到端的深度学习框架,具体来说就是利用孪生(Siamese)网络和区域候选网络(Region Proposal Network),构建了一种高速且高性能的单目标跟踪算法。如下图所示:
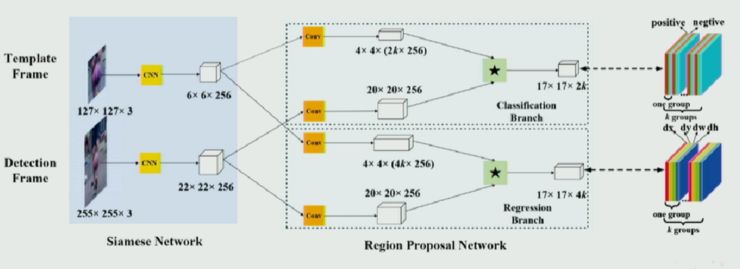
整体上,算法分为 Siamese 特征提取网络和 Region Proposal Network 子网络两个部分。二者通过卷积操作升维,统一在一个端到端的框架里面。
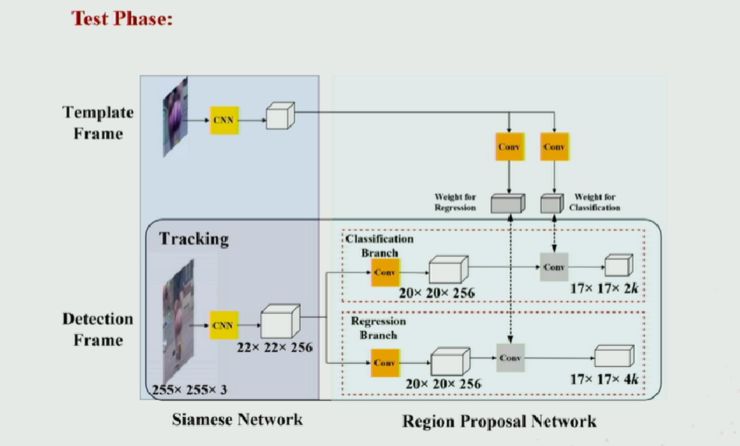
训练过程中,算法可以利用密集标注(VID)和稀疏标注(YoutubeBB)的数据集对进行训练。相比于现有方法,稀疏标注的数据集大大增加了训练数据来源,从而可以对深度神经网络进行更充分的训练;Region Proposal Network 中的坐标回归可以让跟踪框更加准确,并且省去多尺度测试耗费的时间。
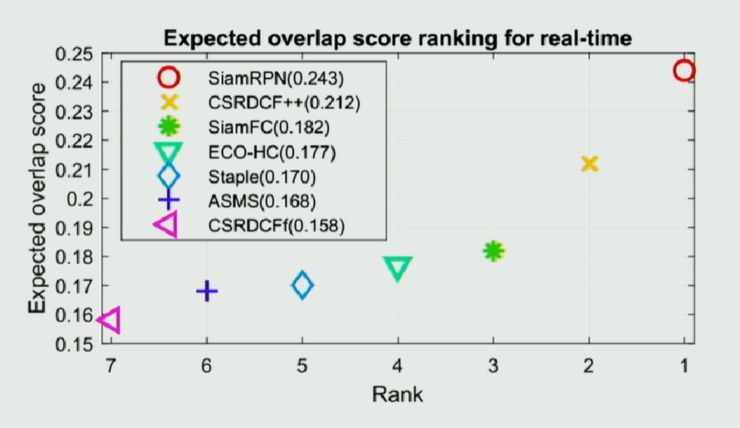
实验方面,本跟踪算法能在保持高速的情况下(160fps),在 VOT2016 和 VOT2017 数据集上取得 state-of-the-art 的结果。
(Performance on VOT 2016)
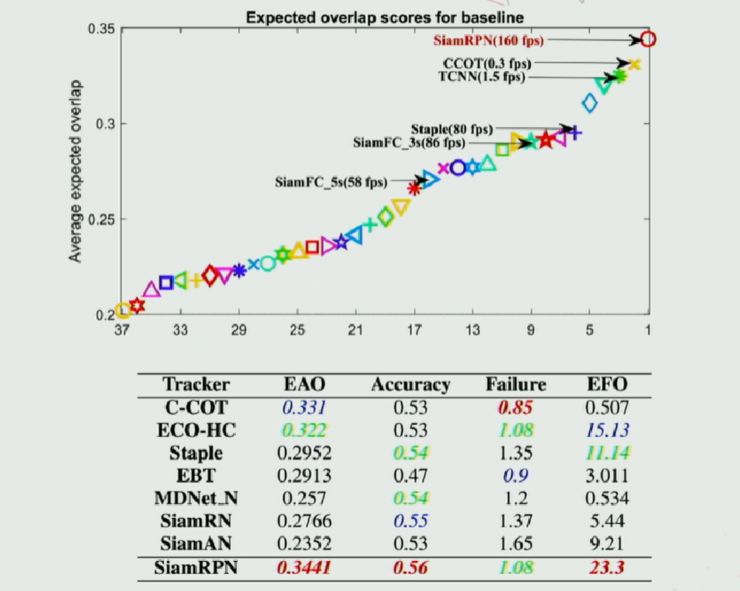
(Performance on VOT 2017)
再来看一张追踪效果:

雷锋网诚招编辑、运营、兼职、外翻等岗位
详情点击招聘启事

关注雷锋网(leiphone-sz)回复 2 加读者群交个朋友




