【泡泡一分钟】使用代表点优化的距离度量学习(ICCV2017-35)
每天一分钟,带你读遍机器人顶级会议文章
标题:No Fuss Distance Metric Learning using Proxies
作者:Yair Movshovitz-Attias, Alexander Toshev, Thomas K. Leung, Sergey Ioffe, Saurabh Singh
来源:International Conference on Computer Vision (ICCV 2017)
播音员:zhuyin
编译:颜青松(38)
欢迎个人转发朋友圈;其他机构或自媒体如需转载,后台留言申请授权

摘要

本文认为,距离度量学习(DML)问题可以定义成训练一个与语义相似度一致的距离。通常对于此类问题,监督分类可以表述成一组具有下述关系的点集:锚点x与正样本点Y相似而与负样本Z不相似,并且基于距离的损失函数最优。虽然损失函数的优化方法各有不同,本文将所有此类思路统称为Triplets,基于该思路的方法统称为Triplets-Based方法。众所周知,Tripets-Based方法的一个难点在于最优求解,其中一个主要原因是需要寻找有意义的Triplets。虽然目前有许多技巧能一定程度解决此问题,例如增加batch大小,严格/半严格Triplet检索等等,但是收敛的速度依然较慢。
本文从一种新的角度计算Triplets的损失,即计算锚点和学习到的代表点(proxy point)的相似和不相似程度,进而简化优化步骤。这些代表点与原始数据近似,因此基于代理点的Triplet的损失是原始损失的严格上界。经过试验验证,本文的算法在3个标准的zero-shot数据集上得到了比当前最优算法高出15%的结果,并且收敛速度比其他Triplet-Based方法快3倍。
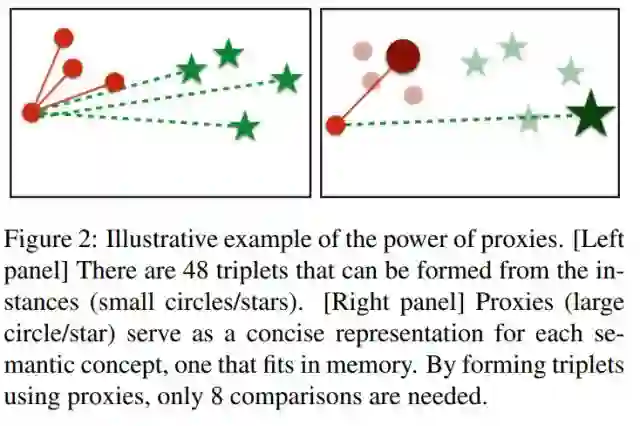
下图展示了本文的一个主要思路,即通过使用代理点减少计算量进而加快迭代次数。其中左图是原始方法,右图是经过优化后本文的方法。
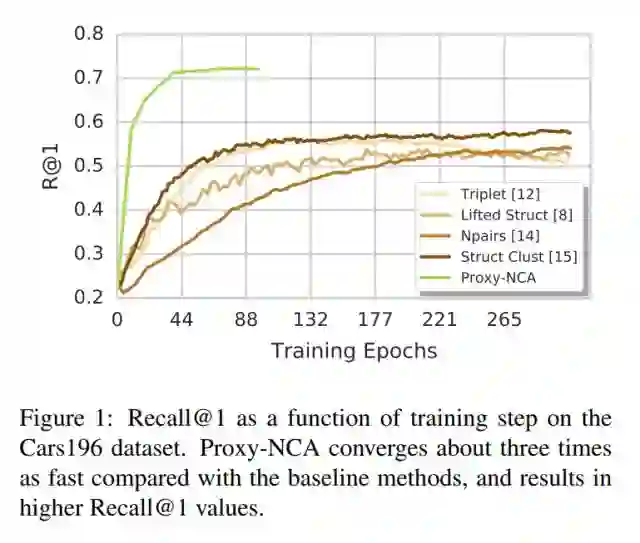
下图展示了本文算法Proxy-NCA的计算效率。

Abstract
We address the problem of distance metric learning (DML), defined as learning a distance consistent with a notion of semantic similarity.
Traditionally, for this problem supervision is expressed in the form of sets of points that follow an ordinal relationship – an anchor point x is similar to a set of positive points Y , and dissimilar to a set of negative points Z, and a loss defined over these distances is minimized.
While the specifics of the optimization differ, in this work we collectively call this type of supervision Triplets and all methods that follow this pattern Triplet-Based methods. These methods are challenging to optimize.
A main issue is the need for finding informative triplets, which is usually achieved by a variety of tricks such as increasing the batch size, hard or semi-hard triplet mining, etc. Even with these tricks, the convergence rate of such methods is slow.
In this paper we propose to optimize the triplet loss on a different space of triplets, consisting of an anchor data point and similar and dissimilar proxy points which are learned as well.
These proxies approximate the original data points, so that a triplet loss over the proxies is a tight upper bound of the original loss. This proxy-based loss is empirically better behaved.
As a result, the proxy-loss improves on state-of-art results for three standard zero-shot learning datasets, by up to 15% points, while converging three times as fast as other triplet-based losses.
如果你对本文感兴趣,想要下载完整文章进行阅读,可以关注【泡泡机器人SLAM】公众号(paopaorobot_slam)。
欢迎来到泡泡论坛,这里有大牛为你解答关于SLAM的任何疑惑。
有想问的问题,或者想刷帖回答问题,泡泡论坛欢迎你!
泡泡网站:www.paopaorobot.org
泡泡论坛:http://paopaorobot.org/forums/


泡泡机器人SLAM的原创内容均由泡泡机器人的成员花费大量心血制作而成,希望大家珍惜我们的劳动成果,转载请务必注明出自【泡泡机器人SLAM】微信公众号,否则侵权必究!同时,我们也欢迎各位转载到自己的朋友圈,让更多的人能进入到SLAM这个领域中,让我们共同为推进中国的SLAM事业而努力!
商业合作及转载请联系liufuqiang_robot@hotmail.com



