【泡泡一分钟】用于快速深度神经网络的协调滤波器(ICCV2017-64)
每天一分钟,带你读遍机器人顶级会议文章
标题:Coordinating Filters for Faster Deep Neural Networks
作者:Wei Wen, Cong Xu, Chunpeng Wu
来源:International Conference on Computer Vision (ICCV 2017)
播音员:糯米
编译:王嫣然 周平(69)
欢迎个人转发朋友圈;其他机构或自媒体如需转载,后台留言申请授权

摘要

大规模的深度神经网络(DNNs)在各种计算机视觉任务中取得了显著的成功。然而,DNN的高计算强度使得在资源有限的系统上部署这些模型变得很困难。一些研究使用低秩方法,以低秩为基础来近似过滤器,以加速测试。这些工作通过低阶近似(LRA)直接分解预训练DNN。然而,如何训练DNN到更低阶的空间以获得更高效的DNN,仍未有定论。为了解决这一问题,我们提出了强制正则化,它使用引力来执行过滤器,以便将更多的权重信息协调到低阶空间中。
我们通过数学和经验验证,在应用该技术后,标准LRA方法可以使用更低的基准重建滤波器,从而得到更快的DNN。我们方法的有效性在ResNets, AlexNet, GoogLeNet中得到全面评估。例如,在AlexNet中,强制正则化在现代GPU上获得了2倍的提速,没有精确度损失,并且损失小部分精确度,在CPU上获得了4.05倍的提速。而且,强制正则化可以更好的初始化低秩DNN,这样微调可以更快地收敛到更高的精度。所获得的更低秩的DNN可以进一步稀疏化,从而证明了强制正则化可以与最先进的基于稀疏度的加速方法相结合。

图1 CIFAR-10卷积神经网络第一层滤波器的低阶基础。 低秩基础由PCA获得的最重要的主要过滤器组成。 顶部:原始网络的低阶基础。 底部:应用力量正则化后,同一网络的低阶基础。 红色框的数量表示重建原始过滤器所需的等级,错误率为20%。
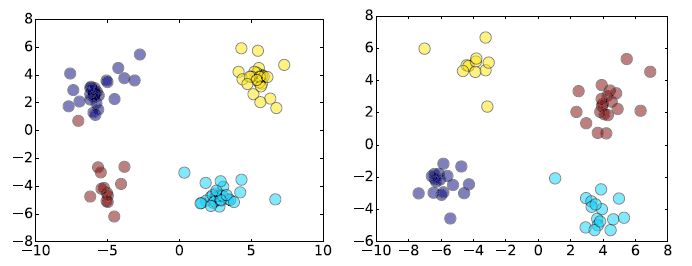
图2 AlexNet(左)和GoogLeNet(右)的第一个卷积层中滤波器的线性判别分析(LDA)。
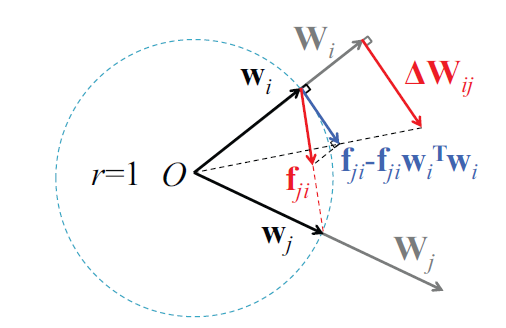
图3 强制正则化协调滤波器
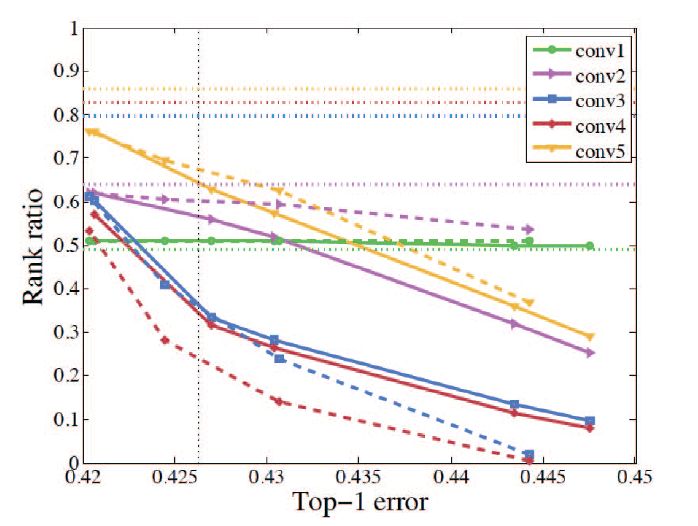
图4 每层的排名(具有≤5%的PCA重构错误)与AlexNet排名前1错误的对比图。 水平虚线表示基线的等级比率,而垂直虚线表示基线的误差。 实线(虚线)描述了强制正则化后的AlexNet的2范数(1-范数)的等级比率。 每层都用一种颜色表示。 超参数λs的灵敏度:沿着从左到右的方向,2-范数力的λs从1.2e-5变为1.8e-5,2.0e-5,3.0e-5和3.5e-5; 对于1范数力,它从1.5e-5变为1.8e-5,2.0e-5和2.5e-5。

Abstract
Very large-scale Deep Neural Networks (DNNs) have achieved remarkable successes in a large variety of computer vision tasks. However, the high computation intensity of DNNs makes it challenging to deploy these models on resource-limited systems. Some studies used low-rank approaches that approximate the filters by low-rank basis to accelerate the testing. Those works directly decomposed the pre-trained DNNs by Low-Rank Approximations (LRA). How to train DNNs toward lower-rank space for more efficient DNNs, however, remains as an open area. To solve the issue, in this work, we propose Force Regularization, which uses attractive forces to enforce filters so as to coordinate more weight information into lower-rank space. We mathematically and empirically verify that after applying our technique, standard LRA methods can reconstruct filters using much lower basis and thus result in faster DNNs. The effectiveness of our approach is comprehensively evaluated in ResNets, AlexNet, and GoogLeNet. In AlexNet, for example, Force Regularization gains 2x speedup on modern GPU without accuracy loss and 4.05x speedup on CPU by paying small accuracy degradation. Moreover, Force Regularization better initializes the low-rank DNNs such that the fine-tuning can converge faster toward higher accuracy. The obtained lower-rank DNNs can be further sparsified, proving that Force Regularization can be integrated with state-of-the-art sparsity-based acceleration methods.
如果你对本文感兴趣,想要下载完整文章进行阅读,可以关注【泡泡机器人SLAM】公众号(paopaorobot_slam)。
欢迎来到泡泡论坛,这里有大牛为你解答关于SLAM的任何疑惑。
有想问的问题,或者想刷帖回答问题,泡泡论坛欢迎你!
泡泡网站:www.paopaorobot.org
泡泡论坛:http://paopaorobot.org/forums/


泡泡机器人SLAM的原创内容均由泡泡机器人的成员花费大量心血制作而成,希望大家珍惜我们的劳动成果,转载请务必注明出自【泡泡机器人SLAM】微信公众号,否则侵权必究!同时,我们也欢迎各位转载到自己的朋友圈,让更多的人能进入到SLAM这个领域中,让我们共同为推进中国的SLAM事业而努力!
商业合作及转载请联系liufuqiang_robot@hotmail.com



